
In this tutorial, we are going to learn how to use Amazon DynamoDB. But before moving ahead let's have a quick overview of Amazon DynamoDB.
Amazon DynamoDB overview
- Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability in a way that we don't have to worry about hardware provisioning, setup, and configuration, replication, software patching, or cluster scaling.
- Amazon DynamoDB provides protection to sensitive data with its encryption at rest feature.
- We can create database tables that can store and retrieve any amount of data and serve any level of request traffic with DynamoDB.
- With DynamoDB, the throughput capacity of our tables can be scaled up or down without downtime or performance degradation.
- With DynamoDB, we can delete expired items from tables automatically which helps us to reduce storage usage and the cost of storing data that is no longer relevant.
- With DynamoDB, we can create on-demand backups of our tables for long-term retention and archival for regulatory compliance needs.
- With DynamoDB, we can enable point-in-time recovery that helps protect our tables from accidental write or delete operations.
- To handle our throughput and storage requirements, the data and traffic for our table are spread automatically over a sufficient number of servers by Amazon DynamoDB.
- Amazon DynamoDB provides built-in high availability and data durability by storing our data on solid-state disks (SSDs) and automatically replicating it across multiple Availability Zones in an AWS Region.
- To keep DynamoDB tables in sync across AWS Regions, we can use global tables.
Now let's have a look at the core components of Amazon DynamoDB.
Amazon DynamoDB Core Components
- Amazon DynamoDB stores data in tables which is a collection of data.
- An item is a group of attributes that is uniquely identifiable among all of the other items. There is no limit to the number of items that can be stored in a table.
- An attribute is a fundamental data element, something that does not need to be broken down any further.
- The primary key uniquely identifies each item in the table. DynamoDB supports two different kinds of primary keys: Partition key and Partition key and sort key (used together).
- A partition key is a primary key, composed of one attribute. The partition key's value is used as input to an internal hash function. The output from the hash function determines the partition (physical storage internal to DynamoDB) in which the item will be stored. Note that no two items can have the same partition key value in a table that has a partition key only.
- The partition key and sort key used together are referred to as the composite key. All items with the same partition key value are stored together, in sorted order by sort key value. In a table that has a partition key and a sort key, it's possible for multiple items to have the same partition key value but those items must have different sort key values. A composite primary key gives you additional flexibility when querying data.
- A secondary index is a data structure that contains a subset of attributes from a table, along with an alternate key to support Query operations. DynamoDB supports two kinds of indexes i.e Global secondary index and Local secondary index. GSI is an index with a partition key and sort key that can be different from those on the table whereas an LSI is an index that has the same partition key as the table, but a different sort key.
- In DynamoDB tables, data modification events can be captured by DynamoDB Streams. Note that DynamoDB Streams can be used together with AWS Lambda to create a trigger—code that runs automatically whenever an event of interest appears in a stream.
Now let's head straight to the implementation part!
Create Amazon DynamoDB table
- First, we will log in to our AWS account then type DynamoDB under the Services tab. Then we will click on Create table.
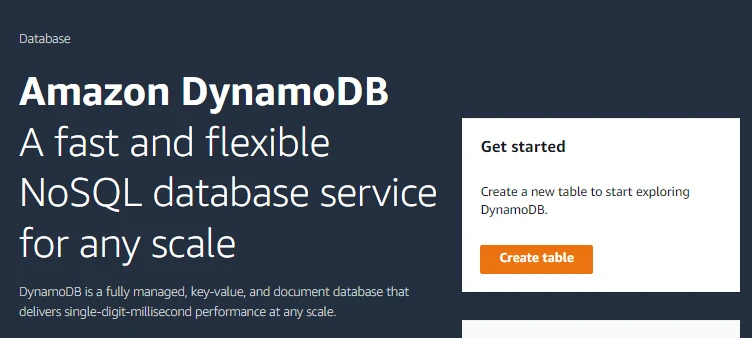
- Here we will provide the table name i.e. Users. Note that DynamoDB is a schemaless database that requires only a table name and a primary key when we create the table.
- Then we will provide the Partition key i.e. user_id of type String. The Partition key can be a number or binary as well.
- We will not provide the Sort key for now.
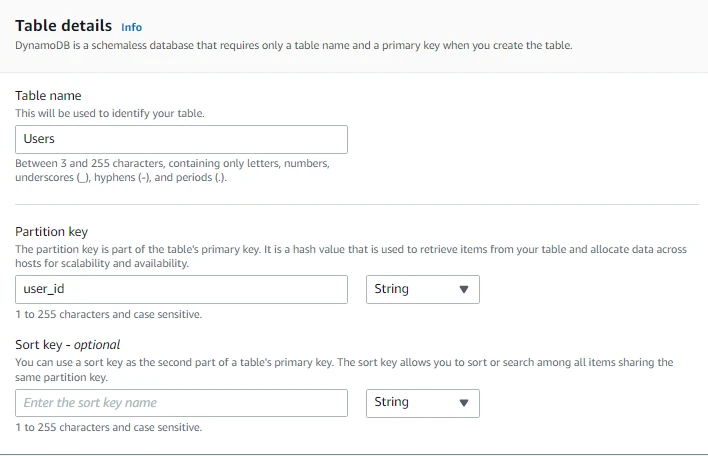
- Now here we can either choose from Default settings or Customize settings.
- Note that choosing Default settings is the fastest way to create our table. We can change these settings now or after our table has been created. We can see the configurations below in case we select Default Settings.
- Through Customize settings we can use advanced features to make DynamoDB work according to our needs. We will choose Customize Settings for now.
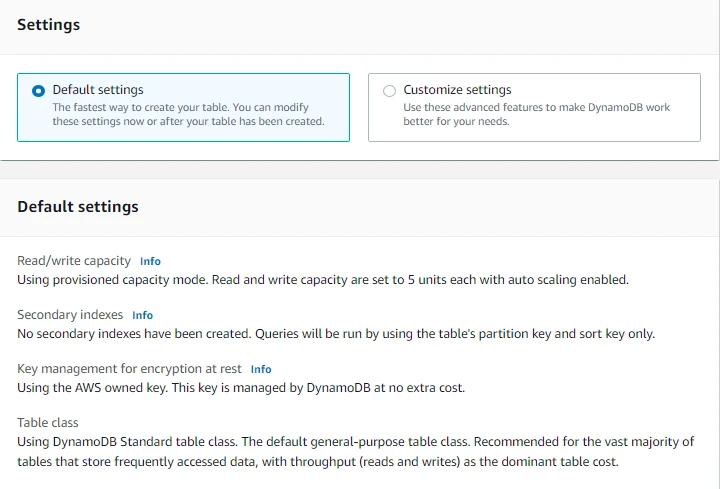
- Now we will choose table class to optimize our table's cost based on the workload requirements and data access patterns. Here we will choose DynamoDB standard. Note that it is the default general-purpose table class. It is recommended for the vast majority of tables that store data that is frequently accessed, with throughput as the dominant table cost.
- We will leave Capacity Calculator for now. We will see it later in the tutorial.
- Under Read/Write capacity settings, for Capacity mode we will select Provisioned for now. Note that On-demand capacity mode simplifies billing as we will be paying for the actual reads and writes our application performs whereas in the Provisioned capacity mode we will manage and optimize our costs by allocating read/write in advance.
- On-demand capacity mode is more expensive than Provisioned mode.
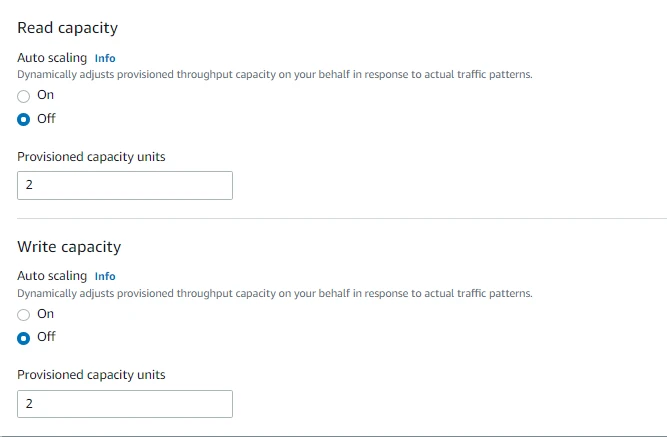
- For Read Capacity, we will turn off the Autoscaling for now and set the Provisioned capacity units to 2.
- Similarly, for Write Capacity, we will turn off the Autoscaling for now and set the Provisioned capacity units to 2.
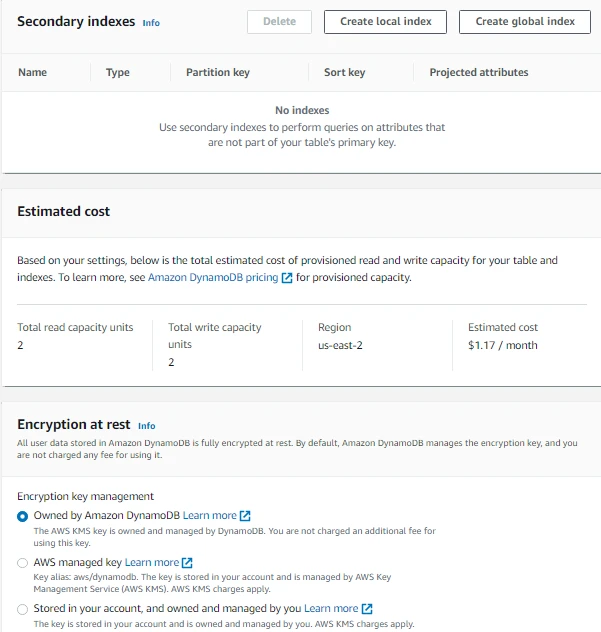
- We can also create a Local Secondary Index or Global Secondary Index. But we won't do it for now.
- We can also see the estimated cost of provisioned read and write capacity for our table and indexes based on the settings we did earlier.
- For Encryption key management we will select Owned by Amazon DynamoDB in which AWS KMS Key is owned and managed by DynamoDB. Note that we can also select AWS managed key in which the key is stored in our account and managed by AWS KMS. We can also store the key in our account which is managed and stored by us.
- Then we will click on Create table.
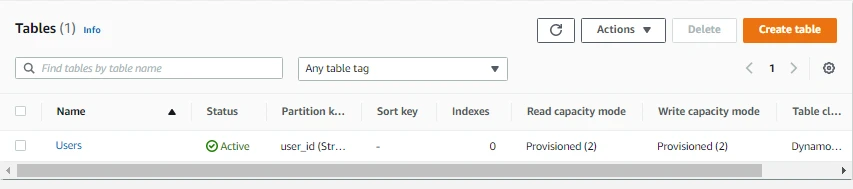
- Here we can see our newly created DynamoDB table.
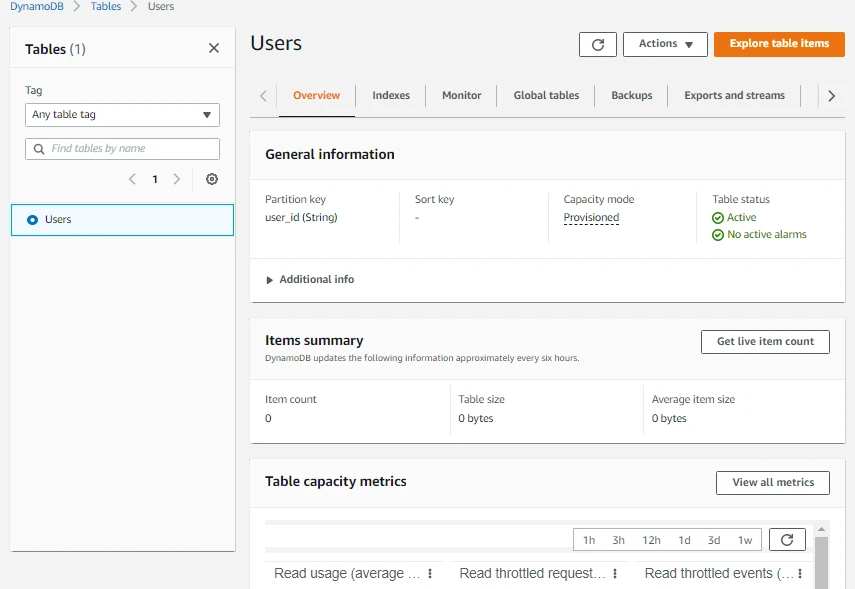
Now let's create an item in DynamoDB table.
Create item
- First, we will click on the table name Users.
- Then we will click on Explore table items.
- Then we will click on Create item
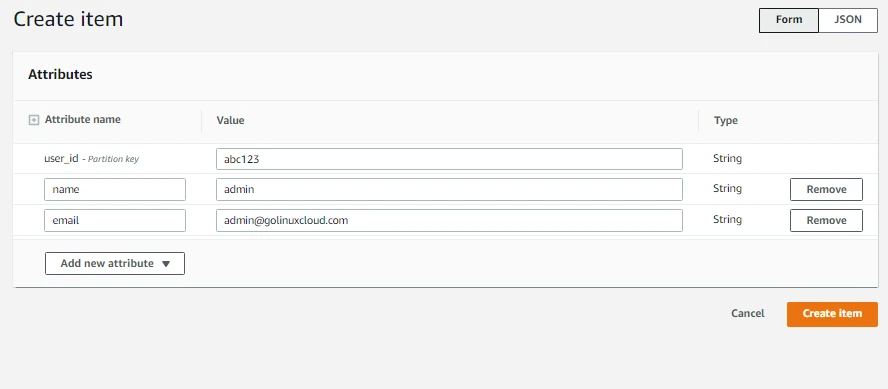
- Here we will enter attributes and their values. We will create attributes named name and email, user_id will already be there**.** Note that we can add attributes of different data types. Then we will click on Create item.
- We can create items either through a Form or a JSON document as shown in the top right below.
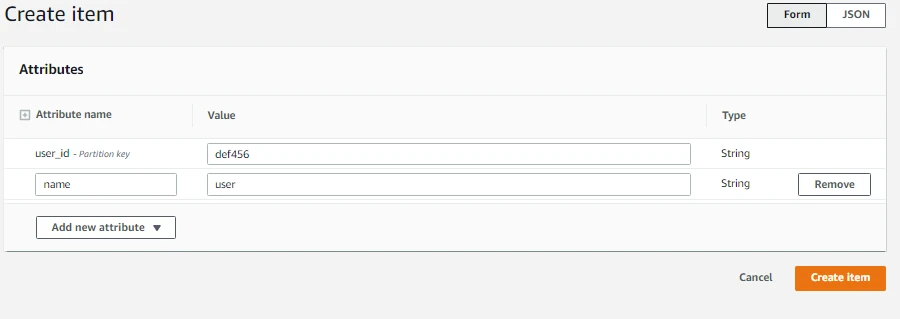
- Now let's add another item but this time we will only have two attributes i.e. user_id and name. Note that we cannot use the user_id that we used before as Partition Key needs to be unique.
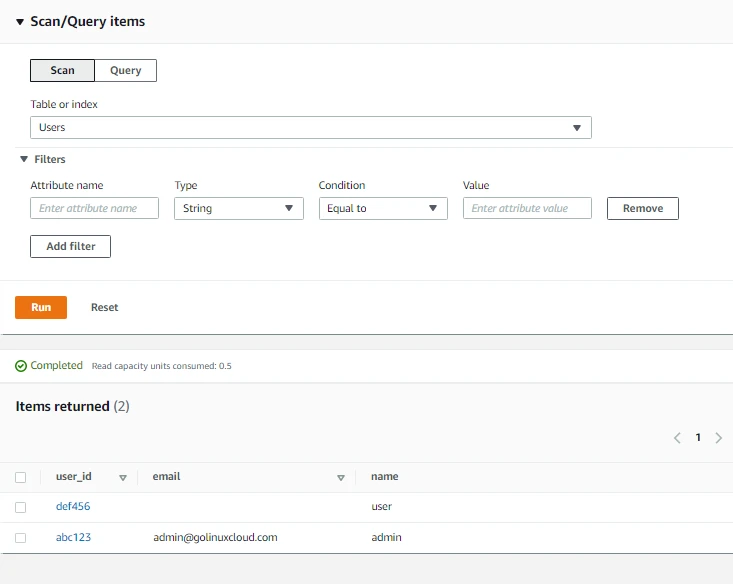
- Here we can view our newly created items. We can also Scan and Query our table.
- In DynamoDB we can have items with different attributes as shown below. The only attribute required for all the items is user_id. With DynamoDB, we can add attributes over time without affecting our previously entered items.
Now let's have a look at the Read/Write capacity of our DynamoDB table.
Read/Write Capacity
The read/write capacity mode controls how we are charged for read and write throughput and how we manage capacity. Let's explore it.
- First, we will switch to the Additional Settings tab. Then we will click on Edit.
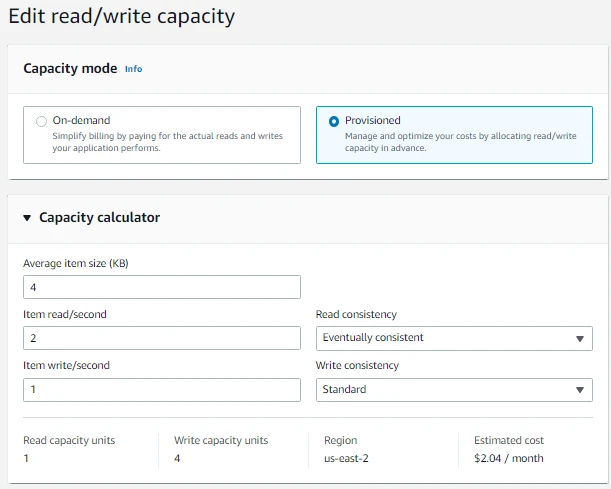
- Under Capacity Calculator we will set the Average item size to****4, item read/second to 2, item write/second to 1, Read consistency to Eventually consistent, and Write consistency to Standard as shown below.
- Read capacity units, Write Capacity units and Estimated cost will be calculated based on the values we have provided.
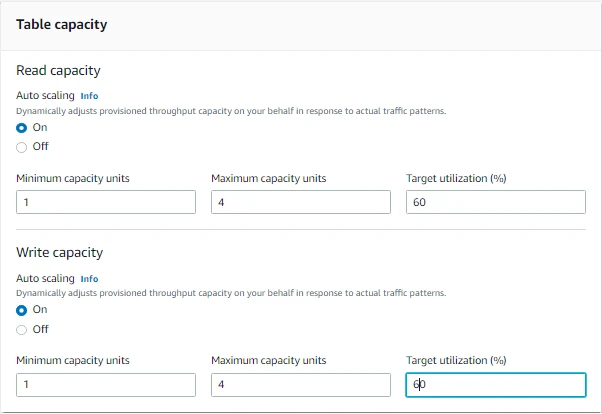
- Under Table Capacity, now we will turn on Auto Scaling for Read and Write capacity. Note that Autoscaling dynamically adjusts provisioned throughput capacity on our behalf in response to actual traffic patterns.
- We will set the Minimum Capacity units to 1, Maximum Capacity units to 4, and Target Utilization to 60% for Autoscaling of both Read and Write capacity.
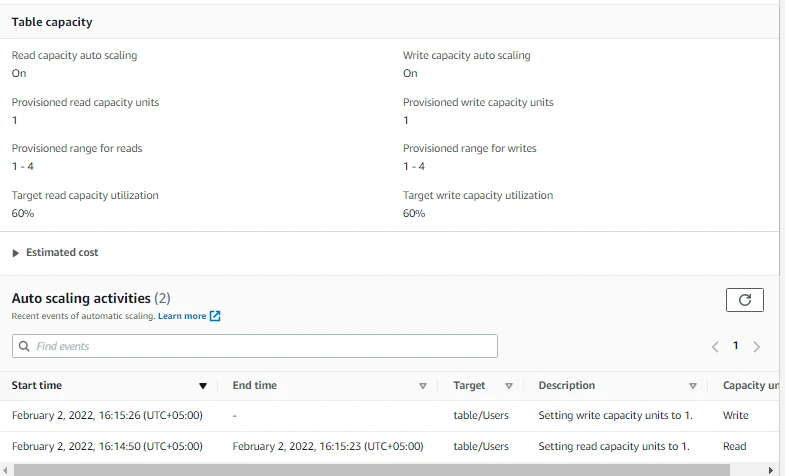
- Now we can see the updated Table capacity information. Note that Read capacity auto scaling is on now.
- The value of Provisioned read capacity units and Provisioned write capacity units is currently 1 as there is no need to scale out for now. Previously it was fixed to 2.
- Similarly, we can see the provisioned range for reads and writes as well as Target read and write capacity utilization. Previously we did not have these values.
- Auto-scaling activities can also be seen below.
Conclusion
With this, we have come to the end of our tutorial. In this tutorial, we learned to use Amazon DynamoDB. First, we had a quick overview of Amazon DynamoDB and its core components. Then we created a DynamoDB table. After that, we learned to create an item in DynamoDB table. And in the end, we explored Read/Write capacity of DynamoDB table.
Stay tuned for some more informative tutorials ahead. Feel free to leave any feedback in the comments section.
Happy learning!