A healthy Kubernetes Operator should spend most of its time idle, waking only when something meaningful changed. A reconcile explosion is the opposite: CPU pegged, apiserver 429s, etcd latency climbing, and logs scrolling faster than you can read—often while the cluster is “fine.”
This guide explains the usual mechanical causes—status churn, accidental .spec writes, Owns() on hyperactive children, aggressive RequeueAfter, and event-shaped logic inside Reconcile—and the patterns controller-runtime teams use to stay level-triggered. For return-path semantics, read Requeue, RequeueAfter, and error handling in controller-runtime first; for incident commands, keep Debugging Kubernetes Operators nearby.
Avoid reconcile explosions in 60 seconds
- Keep
Reconcile()idempotent and based on current state, not individual events. - Avoid unnecessary writes to
.statusand never mutate.specas a side effect. - Use
GenerationChangedPredicateto ignore status-only updates on your primary CR. - Be careful with
Owns()on noisy resources such as Pods. - Use watches for real state transitions instead of aggressive
RequeueAfter. - Fix reconcile logic before increasing
MaxConcurrentReconciles.
Why reconcile storms happen (before you change code)
What “explosion” means in production
You are looking for sustained symptoms, not a single spike:
- Workqueue depth grows and never drains between quiet periods.
Reconcilelogs print the samenamespace/nametens of times per second.- API server latency or 429 Too Many Requests rises with operator load.
- etcd metrics show elevated write rates even though user intent did not change.
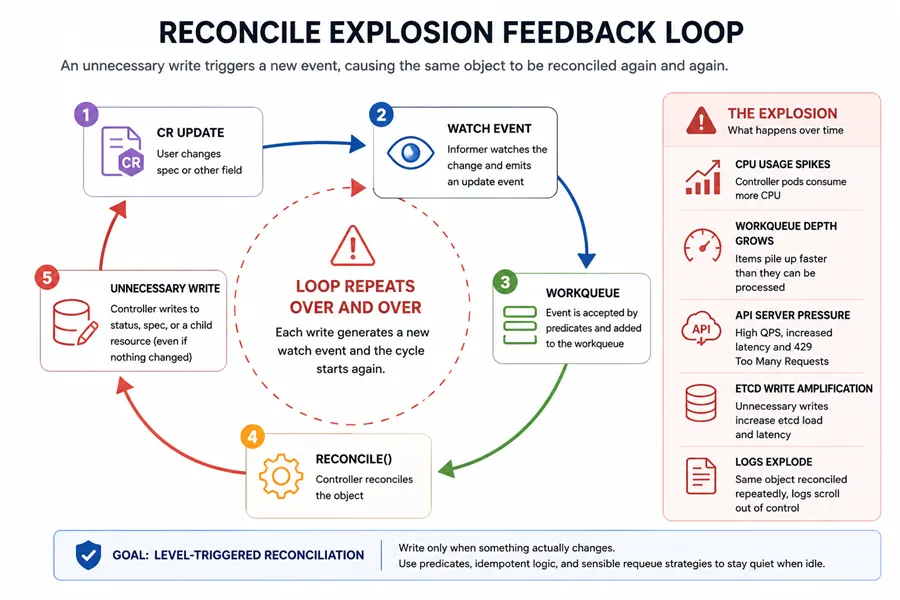
Those symptoms usually mean your controller is fighting itself—each pass writes something that creates another watch event for the same object graph.
Level-triggered reconcile vs accidental edge-triggered behavior
Kubernetes controllers are supposed to be level-triggered: given the current object graph, converge toward desired state. If you still think in edges (“handle this Update event differently from Create”), you tend to add branches that skip idempotency checks and write more often than the level model requires. That mismatch is a common root cause of storms—see desired state vs actual state and the reconcile loop explained.
Status writes that re-trigger reconciliation
How informer updates become new reconcile keys
When you patch .status, the API server emits another update on the same object. Your SharedInformer delivers it to predicates, then possibly to your workqueue. If you treat every update as “full reconcile,” you can loop: reconcile → status patch → watch update → reconcile again.
.metadata.generation vs .metadata.resourceVersion
generationincrements whenspecchanges (for CRDs with a proper status subresource, this is the usual signal you care about for “user intent changed”).resourceVersionchanges on any write, including status-only updates.
Filtering on resourceVersion alone inside your business logic rarely stops storms; you want framework-level filters (predicates) or careful writes.
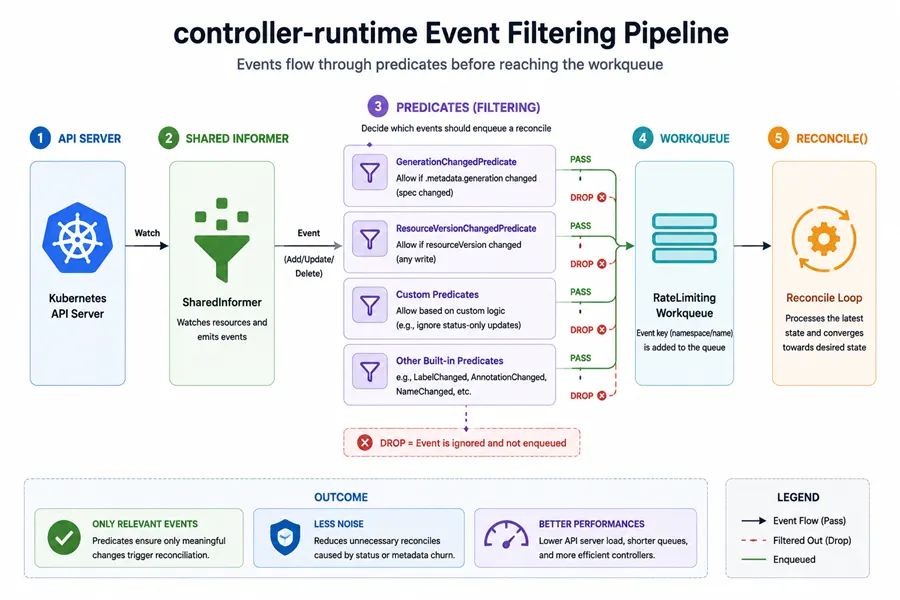
Using GenerationChangedPredicate (and when it is not enough)
In controller-runtime, attaching predicate.GenerationChangedPredicate{} to the primary For(&MyKind{}) controller ignores updates that only touched status or unrelated metadata—while spec edits still enqueue.
It is not a silver bullet:
- If your reconcile mutates
.specevery time (see next section), generation will bump forever. - Some APIs bump generation in ways you do not expect; validate with a watch stream during development.
Details and composition patterns live in watches, events, and predicates.
Writing status without waking the spec reconcile path
Combine generation predicates on the primary kind with narrow status patches (only fields that actually changed). Also avoid writing timestamps, counters, or "last checked" fields on every reconcile unless they provide real user value. Constantly changing status fields are a common source of self-generated events. When you need to react to your own status writes for phased rollouts, consider a dedicated condition and short-circuit early if nothing except your last write changed—or split responsibilities across controllers with clear ownership.
Accidental writes to .spec from Reconcile
Read-only intent vs Update on the whole object
A classic bug:
Getthe CR intoobj.- Mutate status in memory.
- Call
Update(ctx, &obj)on the whole object.
If obj carried defaulted fields or you touched spec accidentally, you just created another spec write—even if the user did nothing. This often happens when the same in-memory object is passed to a full Update() call, which sends both spec and status fields back to the API server. Prefer Patch or Status().Update/Patch for status-only paths, and keep spec mutation explicit and rare.
Patch and SSA habits that avoid spec churn
Server-Side Apply helps when multiple writers share an object: you send only the fields you own and a stable field manager name. Client-side StrategicMergePatch with a diff is still valid when you fully own the object—what matters is that you never round-trip unknown fields through a sloppy Update.
A good rule is that a successful Reconcile should be able to run hundreds of times without producing an API write. Before calling Update, Patch, or Apply, ask whether the desired state actually differs from the live state. Controllers that write the same fields repeatedly—even if the values are logically unchanged—can trigger unnecessary watch events, managed field updates, and reconciliation traffic.
Defaulting and mutation: admission vs reconciler responsibilities
Defaulting webhooks and CRD defaults belong in admission or schema layers. When Reconcile rewrites .spec to “fix” missing fields on every pass, you amplify writes and confuse users (“why did my YAML change?”). Push defaults to admission; keep reconcile focused on operands.
For example, an operator should not see an empty .spec.replicas and write back replicas: 3 during every reconcile. That default belongs in the CRD schema or a mutating admission webhook, so the stored object already represents the intended configuration before the controller starts acting on it.
Keeping .spec user-owned also preserves a clear contract: users declare desired state, and the operator reports observations through .status. Mixing those responsibilities makes debugging ownership and drift much harder.
High-churn child resources and Owns() fan-out
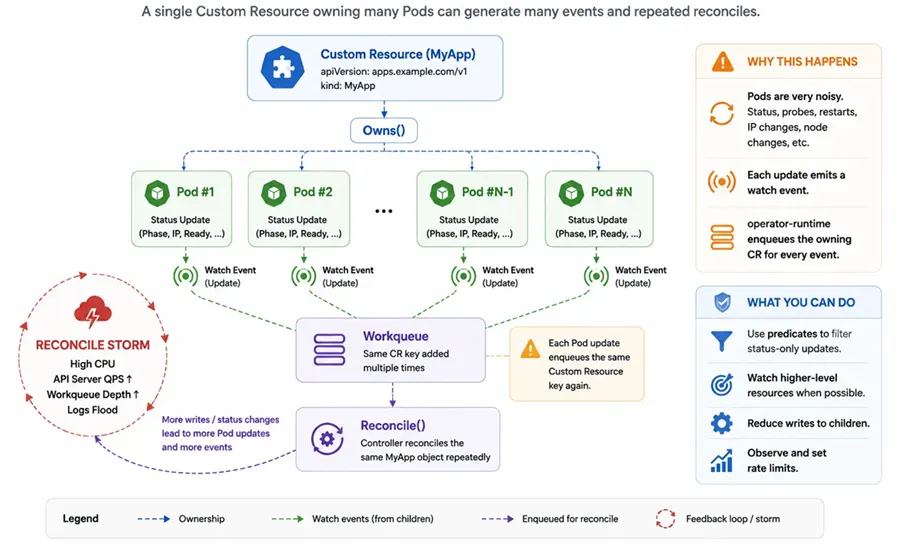
What Owns() adds to the event graph
Owns(&appsv1.Deployment{}) tells controller-runtime to watch child resources and enqueue the owner Custom Resource when those children change. This is the foundation for drift detection—see drift detection patterns—because the controller can react when its managed resources move away from the desired state.
The danger is event fan-out: a single noisy child can generate a stream of updates, and every update can enqueue the same parent CR again. The more child objects each CR owns, the larger the potential amplification.
Noisy children: Pods, Endpoints, ReplicaSet revisions
Pods update constantly: readiness probes, container restarts, PodScheduled, IP assignment, and many other status transitions. If you Owns(&corev1.Pod{}) for every workload, you can easily create a hot reconcile loop unless you filter events aggressively.
Prefer watching higher-level resources such as Deployments or StatefulSets when the health signal you need is already aggregated there. A Deployment's readyReplicas often tells you what you need without receiving every individual Pod status transition.
Use predicates to reduce noise—for example, only react to meaningful readiness changes, deletion events, or labels you care about.
Mapping child events back to the parent CR safely
Use owner references consistently so the framework can map child events back to the correct parent CR—owner references and garbage collection covers the ownership contract.
Avoid patterns where the controller must scan every CR to discover who owns a child object. That turns a single child event into expensive list operations and becomes another scalability bottleneck.
When to prefer Watches with a custom handler over blind Owns
Owns() works best when the child has a clear one-to-one ownership relationship with a parent CR. For shared resources such as a global ConfigMap, a custom Watches() handler with an EnqueueRequestsFromMapFunc can map the event to only the affected CRs.
This gives you precise control over how many reconcile requests a child update creates. The trade-off is more code and careful mapping logic, but it prevents a single noisy resource from waking every controller instance.
Timers: jittered RequeueAfter vs tight loops
Why uniform short RequeueAfter values thunder the apiserver
If every CR returns RequeueAfter: 200 * time.Millisecond “just to be safe,” each object wakes roughly five times per second. With 1000 CRs, that is 5000 reconciles per second even when the cluster is otherwise idle.
That is not a retry or backoff strategy—it is a busy loop with extra steps. Increasing MaxConcurrentReconciles only allows the controller to process the storm faster; it does not remove the unnecessary work.
Jitter, hashing the object UID, and smarter polling
When periodic polling is unavoidable, spread the load:
- Add jitter so all objects do not wake on the same boundary.
- Use a deterministic slot derived from the object UID or name when you need stable scheduling across controller restarts or leader changes.
- Increase the interval once the system reaches a healthy steady state; use shorter delays only while waiting for a known transition.
The goal is to avoid thousands of objects synchronizing their RequeueAfter timers and creating artificial traffic spikes.
When RequeueAfter is appropriate vs relying on watches
Prefer watches for state changes and timers for time-based waiting.
If a dependent Kubernetes resource emits watch events when it becomes ready, you usually do not need a timer at all. The next reconcile will be triggered naturally by the event.
RequeueAfter is appropriate when the signal is outside the watch graph, such as:
- An external API that Kubernetes does not watch.
- A maintenance window or scheduled operation.
- A long-running asynchronous task that must be checked periodically.
For error handling and retry semantics, see Requeue, RequeueAfter, and error handling—timers should represent intentional waiting, not a generic “try again soon” mechanism.
Rate limiting and workqueue behavior (overview)
Per-key backoff vs global QPS—what you are actually tuning
When you return err, controller-runtime applies a per-key exponential backoff through the workqueue rate limiter. A broken object may retry after seconds or minutes instead of being hammered continuously.
RequeueAfter behaves differently: it is a deliberate timer, not an error backoff. If thousands of objects ask to wake up every few hundred milliseconds, the storm comes from object count × wake frequency, not from a single failing resource.
Before tuning QPS or concurrency, first ask why the controller is doing so much work. A healthy operator should spend most of its time waiting for meaningful events.
MaxConcurrentReconciles and goroutine-safe reconcile
Raising controller.Options{ MaxConcurrentReconciles: … } increases the number of worker goroutines processing the queue. It improves throughput for legitimate work, but it also allows a reconcile storm to consume more CPU and generate more API traffic.
Fix excessive events, unnecessary writes, and inefficient reconcile logic first. Increase concurrency only when Reconcile is idempotent, thread-safe, and the workload genuinely benefits from parallel processing.
Also remember that multiple workers can process different CRs at the same time. Avoid shared mutable state inside the controller unless it is protected with proper synchronization.
Pointers to deeper performance tuning
Once the reconcile logic is correct, you can tune throughput and scalability concerns:
- Client QPS and Burst — control how aggressively the operator talks to the API server.
- Informer cache vs direct API reads — balance freshness against API load.
- Shared informer resync behavior — understand periodic reconciliation pressure.
- Workqueue concurrency — increase parallelism only after eliminating hot loops.
For the internals of how events flow through caches, predicates, and the workqueue, read controller-runtime architecture. For controllers that manage many children, see multi-resource reconciliation.
Real performance tuning starts only after you measure actual bottlenecks—API throttling, etcd pressure, expensive diffs, large object graphs, or slow external calls.
Anti-pattern: event-driven imperative branching inside Reconcile
Why “if event.Type == Update” breaks the operator model
controller-runtime does not pass Create/Update/Delete event types into Reconcile—it only provides a request key (namespace/name). This is intentional: a controller should not care why it was triggered, only what the current state of the world looks like.
Trying to preserve event types in a side channel or inferring them later reintroduces edge-triggered thinking. For example, logic like “run this code only on Update” often becomes fragile because multiple events may be coalesced, reordered, or represented by the same reconcile request.
The correct model is: read current state → compare with desired state → apply only the necessary changes. A well-designed Reconcile should produce the same result whether it was triggered by a create event, a spec update, a child object change, a periodic resync, or a manual requeue.
The correct mental model: observe full state, diff, act
At the top of Reconcile:
- Read current CR and dependents from the API (cache-backed client is fine for reads you understand).
- Compute desired child specs from
.spec(and policy). - Diff against live objects; patch minimally.
- Write status describing phase and conditions.
If step 3 is a no-op, return Result{}, nil and let watches do the rest.
How to refactor event-style logic into pure state comparison
How to refactor event-style logic into pure state comparison
Replace “on update, bump this counter” with “if observedGeneration lags generation, run the required action once and record that the desired spec has been observed.”
Replace “on delete” special cases with finalizers—finalizers explained. The API still exposes deletion intent through metadata.deletionTimestamp; your controller can perform cleanup and remove the finalizer when it is safe to delete the object.
Replace “on create, create child resources” with “check whether the required child resources already exist and match the desired specification.” The same logic should work for a newly created CR, a controller restart, a missed event, or a periodic resync.
A useful rule of thumb is: Reconcile should answer "what is missing or different right now?" rather than "what event happened before I got here?"
This is why Kubernetes controllers are resilient to duplicate events, dropped events, restarts, and leader changes—the current state in the API server remains the source of truth.
Diagnosing a hot loop in five checks
Metrics and log signatures that hint at a storm
Watch your operator’s workqueue depth, reconcile rate, reconcile duration histogram, and API client 429/409 rates if you export them—Prometheus metrics for operators covers the common controller-runtime metrics.
A hot reconcile loop often shows a pattern where individual reconciles are fast, but the same keys are processed continuously. High CPU usage is not always caused by expensive logic; it can also come from doing cheap work thousands of times per minute.
kubectl and controller logs: what to check first
Start by filtering controller logs for a single CR and look for the same reconcile phases repeating without a meaningful .spec change.
Check whether the object is constantly changing:
kubectl get myapp example -o yaml | grep -E "generation|resourceVersion"generationincreasing repeatedly often points to an unexpected.specwriter.resourceVersionincreasing whilegenerationremains stable usually indicates status churn or metadata updates.
Also inspect Kubernetes Events with kubectl describe because repeated child failures, retries, or admission problems often leave useful clues.
A quick “is it my predicate?” experiment (safely)
In a development cluster, temporarily add debug logging inside predicate Create, Update, and Delete methods to observe which events are reaching the workqueue.
This helps answer two important questions:
- Is the controller receiving more events than expected?
- Are predicates allowing noisy updates through?
Remove this logging after debugging. In a production storm, excessive logs can amplify CPU usage and make the original problem harder to observe.
Frequently Asked Questions
1. Will GenerationChangedPredicate stop all unnecessary reconciles?
It filters updates where only status or metadata unrelated to spec changed, which removes a huge class of noise. It does not help if your controller still mutates .spec every pass, if generation does not bump for your change, or if child objects you Owns churn for legitimate reasons—you still need sound reconcile logic and sometimes custom predicates.2. Is a short RequeueAfter always wrong?
Short delays are fine when bounded, jittered, and tied to a real waiting condition. They become explosions when every object uses the same tight interval so the workqueue and apiserver see sustained QPS. Prefer watches on the resources that actually flip readiness when you can.3. Why does my operator reconcile more after I added Owns on Pod?
Pods update constantly—status, probes, container restarts, node changes. Each update can enqueue the owning CR again. Narrow predicates, watch higher-level resources when possible, or gate on generation-like signals for the child if you control its writes.See also
If you want to go deeper on the ideas touched here, these tutorials in the Kubernetes Operators series are a good next step:
- The Kubernetes reconcile loop explained
- controller-runtime architecture
- Watches, events, and predicates
- Requeue, RequeueAfter, and error handling in controller-runtime
- Status subresource and conditions
- Server-Side Apply in operators
- Drift detection patterns
- Multi-resource reconciliation
- Debugging Kubernetes Operators
Upstream references
Bottom line: keep Reconcile idempotent and level-triggered. Stop status from re-driving spec work with generation predicates, never “accidentally” touch .spec, be deliberate about Owns() on chatty types, jitter timers instead of tight loops, and treat workqueue tuning as the last step after you stop generating pointless events.