
Introduction - Azure Blob Storage Lifecycle Management
In our previous article, we discussed and demonstrated the setup of an Azure Storage Account along with configuring Azure blob storage. While configuring Azure blobs we explained the different options that are available to us while adding a blob to a container like container access levels, performance tiers, block size etc.
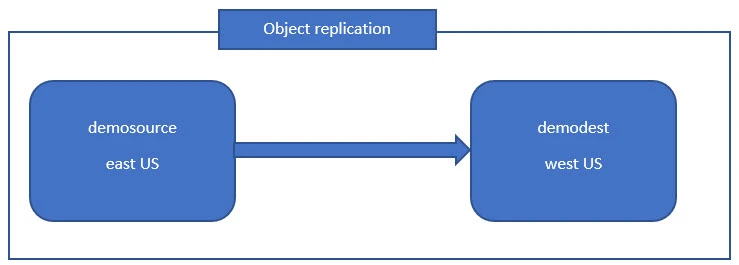
Continuing our discussion on Azure blobs, in this article, we will talk about blob object replication and blob life cycle management.
Azure blob storage Lifecycle management is a feature of the blob service that enables automation to manage the lifecycle of blobs by moving blobs between access tiers, to optimize storage costs. This comprises moving blobs from hot to cooler performance tiers and even blob deletion depending on the frequency of data access.
What is Object Replication?
Replication as the name suggests implies the copying of data in such a way that multiple copies of the said data are available at any given point of time. Object replication asynchronously (not instantaneously) copies block blobs and their versions between a source storage account and a destination storage account. All of the blobs inside the source storage account could be replication to a destination storage account of our choice in the same region or even across regions allowing us to have two versions of the same data present at two different geographical locations.
Features of Object Replication
- Objects are not replicated immediately.
- Besides being able to replicate blobs across regions, we can replicate across subscription and Azure AD tenants.
- Using object replication policies, a storage account can be a source for up to 2 destination accounts.
- Each policy supports only a single pairing and is identified by its policy ID.
- A storage account that is a source for 2 different destinations accounts, and each of those pairings will be its own policy.
Benefits of Object Replication
- Reduced latency: Spanning copies of the data across geographical locations significantly helps to reduce latency especially for read requests. Since, this allows us to place our data in a location that would be closer to from where our customers would be accessing it from.
- Increased efficiency: The ability to process block blobs in different regions helps to improve the efficiency of data processing.
- Data distribution: Since we will be processing and analysing the data in one location and then replicating just the results, the flow or distribution of data will be easier.
- Cost optimization: We could couple object replication with life cycle management to optimize our costs by moving the replicated data to the archive tier to reduce costs in our destination accounts.
Pre-requisites for setting up Object Replication in Azure
Object replication is not available for all categories of blob storage and works for block blobs only. Besides this fact, there are some other pre-requisites needed before setting up object replication which we’ll discuss now.
- Supported Storage Account type: Object replication is only supported on general-purpose v2 standard storage accounts. This is reported regardless of the default access tier selected.
- Versioning: To make object replication possible, we need to have versioning enabled on both the source and destination accounts.
- Change feed: We need to enable the change feed on the source account because Azure storage is going to monitor the system container $blobchangefeed, to advise replication.
Setting up Azure Object Replication
We’ve envisioned a sample scenario to demonstrate object replication wherein we will create two storage accounts in two different regions. One storage account will serve as the source storage account whereas the other one will be the destination storage account. On the source storage account, we’ll also need to setup versioning and change feed.
Although we’ve already demonstrated the creation of a storage account in a previous article, we’ll go through the process of creating the source storage account because here we need to enable versioning and change feed and they are not enabled by default.
Login to the Azure portal and type storage account in the search bar and click on storage account to proceed to the storage account service page. From there, click on the Create button to create a new storage account.
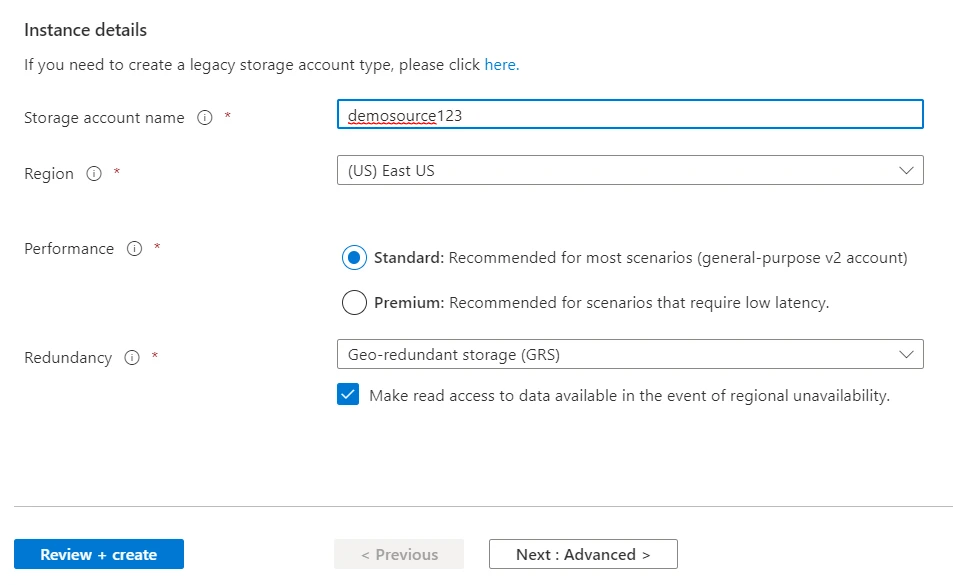
You may select the subscription, resource group and type a name for the storage account but instead of clicking on Review + create, click on the Advanced button.
On this page, click on the Data protection tab and scroll down to the Tracking section. Check mark the Enable blob change feed and Enable versioning for blobs boxes.
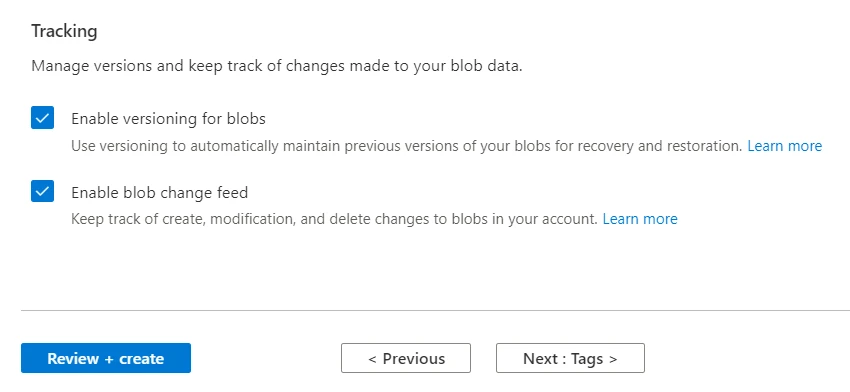
Now click on the Review + create button to proceed with the creation of our source storage account.
Using similar steps we’ll create our destination storage account with versioning enabled.
We’ll now navigate to the Storage Service homepage and find that the storage accounts that we just created are listed as shown below.
Next, we need to create a container in our source and destination storage accounts. We’ve created a container named sourcecon in our source storage account.
And we’ve created a container named destcon in our destination storage account.
Now we will setup a replication policy on the source container. Click on the source container name in the storage account home page and on the left side of the screen, under Data management click on the Objection replication tab.
This will open the Object replication page and here we will click on Set up replication rules.
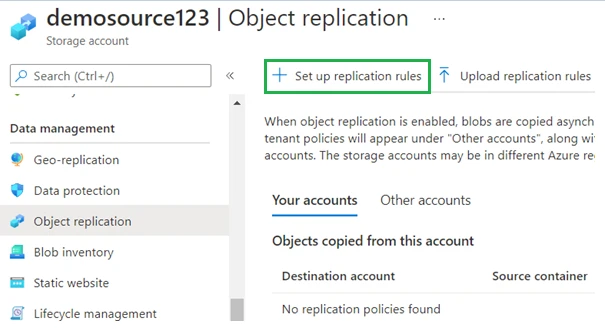
Within the Setup replication rules page, we will configure the destination subscription/storage account we’d like to replicate to and create the pairing for the source and destination containers.
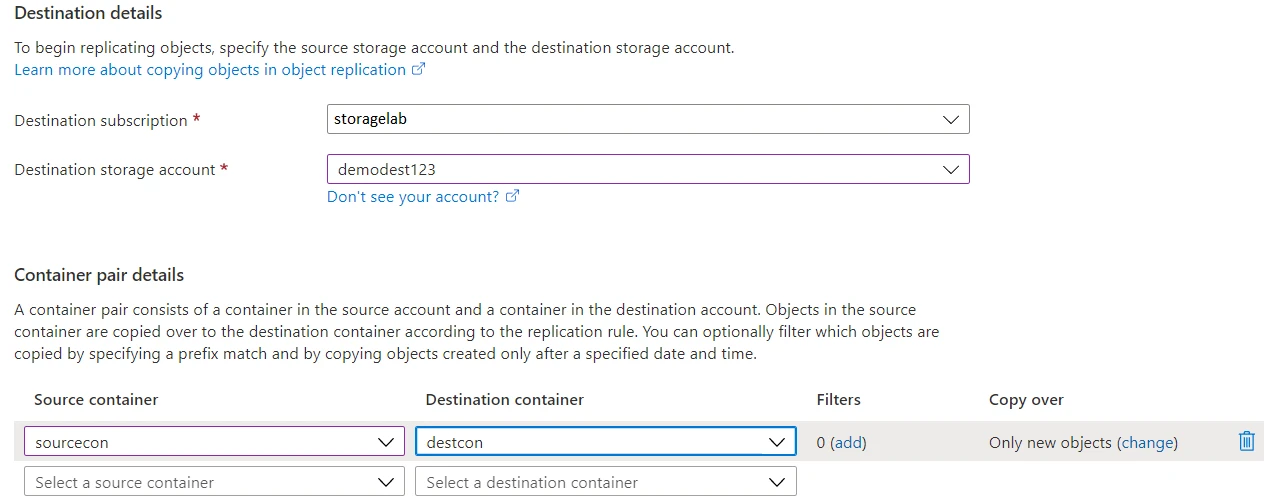
Since both our storage accounts are in the same subscription, we’ll leave that field as it is and provide the name for our destination storage account.
In the container pair details section, we’ll select the source and destination containers we just created.
Here notice the filters and copy over fields. The filters field allows us to select what we’d like to copy i.e.; we could provide a prefix for a certain file name or file extension. The copy over field allows us to choose which objects do we wish to replicate. We may select replicate all objects, replicate objects created after the policy is applied or provide a custom time window.
Once we’ve provided the necessary values, we’ll click on the save and apply button. This will take a few seconds after which the policy should be visible in the Object replication section for the source container.
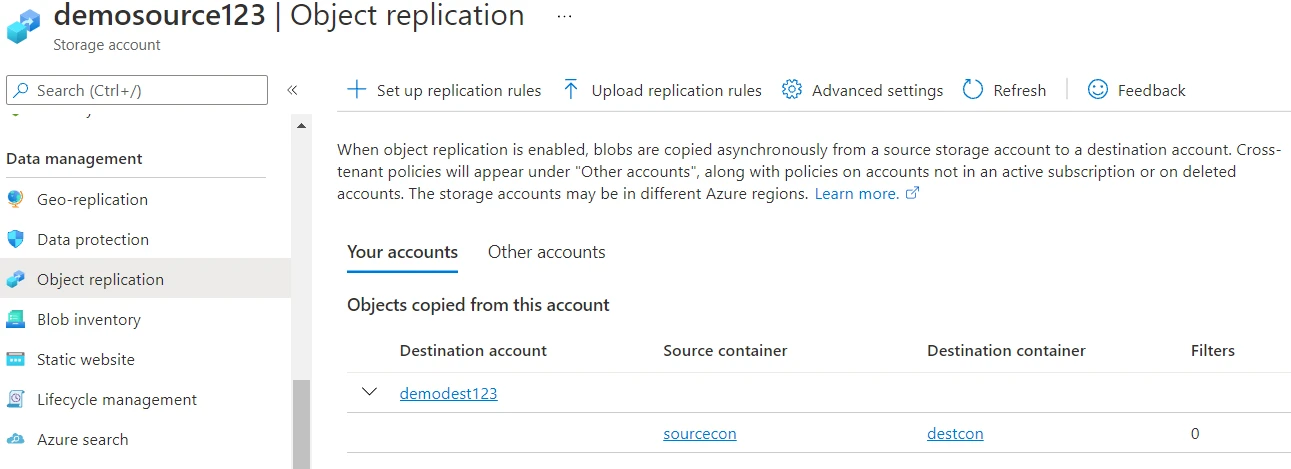
To test this policy, we’ll now upload a file to our source container.
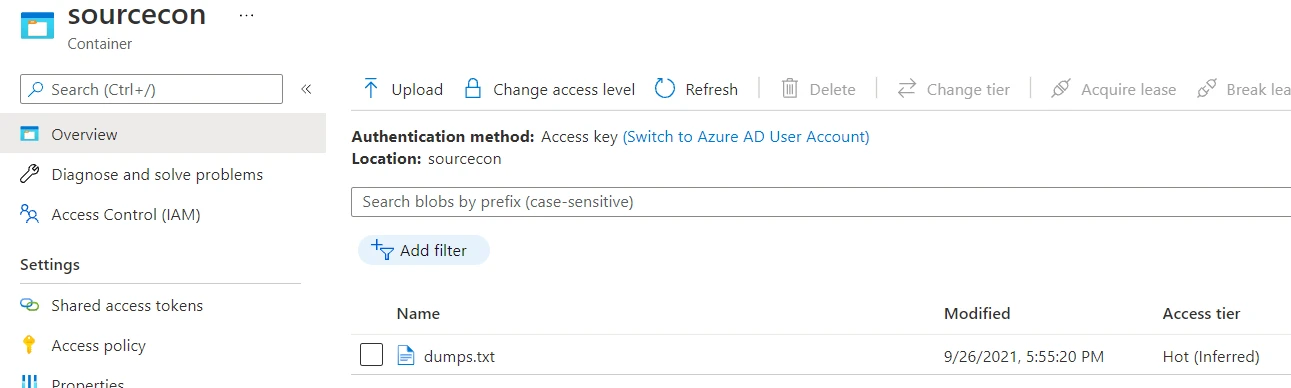
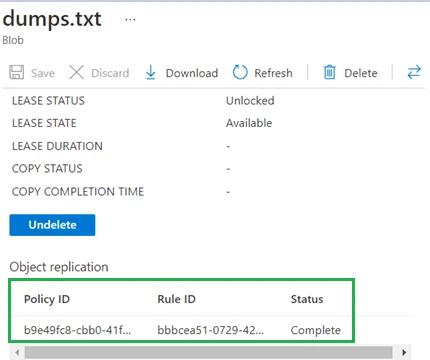
We’ve uploaded a file named dumps.txt and now we’ll take a look at its
properties by clicking on the file name. Towards the end of the
properties section, we will see fields for the copy status, copy
completion time and object replication.
This field appear to be blank for now and the reason for this is that object replication asynchronous. Azure will monitor the changefeed log in the system container to look for these changes and will replicate the file once those changes are listed in the log. When we check the status again just after a few minutes, we found that the object replication had a status of Completed.
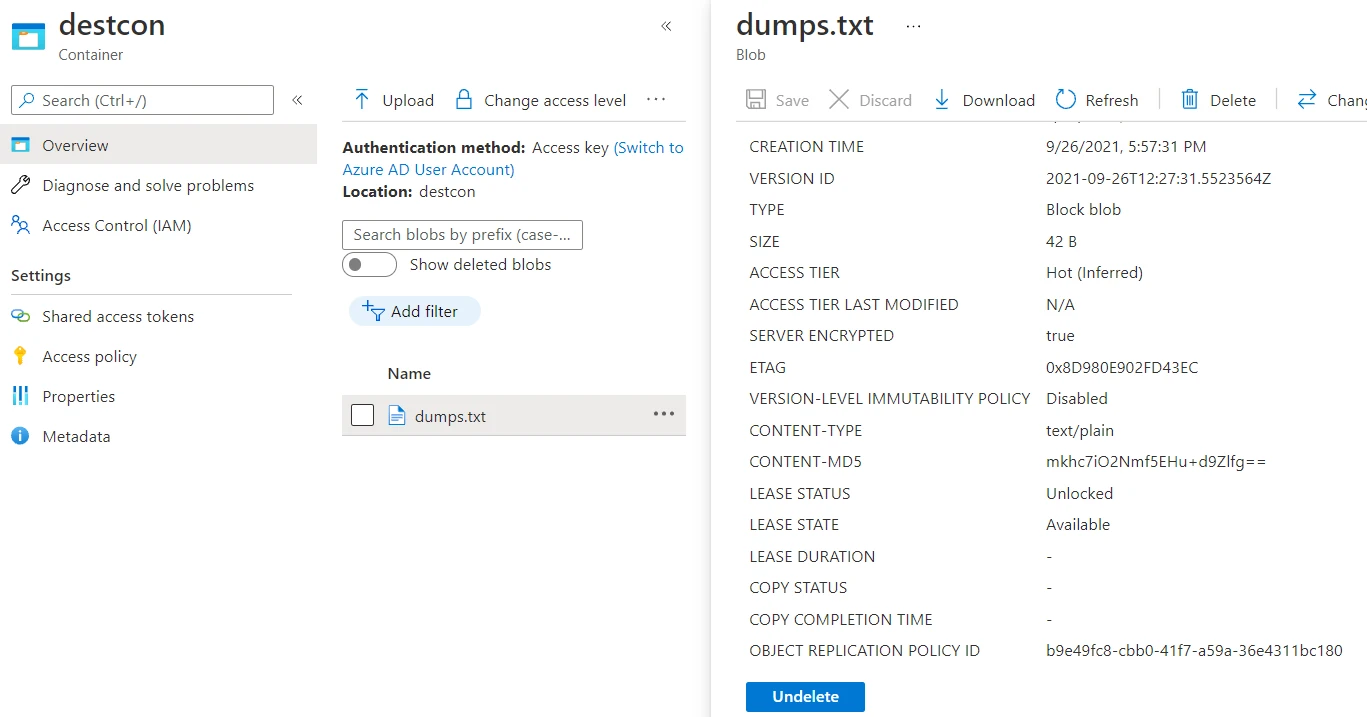
Let’s check our destination container to verify if the object has been
replicated to that location. Upon checking, we indeed find the file
dumps.txt in the
destcon container on
the destination storage account.
Why to use Azure blob storage lifecycle management
Our storage account will have the blob service and inside of the blob service, we'll have different blobs having a default access tier. Upon creation, these blobs will be in the hot access tier by default unless we manually change that. It’s possible that some of these blobs don't belong in the tier that they're in and some of the blobs may need to be moved to cool, or archive, or even be deleted. This process could be cumbersome and sounds ideal for automation.
This is where Azure blob storage lifecycle management comes into the picture. Let’s assume that we uploaded a blob and this blob is hot because it's using the default access tier of the storage account, which is hot. Let's say we create a life cycle policy and inside of our lifecycle management policy, we say that as time progresses, after 30 days, if this blob hasn't been accessed, go ahead and move it to the cool tier, so that we can save some money. And then if it hasn't been accessed for another 180 days from the cool tier, go ahead and move it into archive. And then if it hasn't been accessed in 365 days from the time that it's moved into the archive tier, go ahead and delete the blob.
Features of Azure Blob Storage Lifecycle Management
- Storage accounts: Only general-purpose v2, standard performance storage accounts, Blob storage accounts, and BlockBlob storage accounts, support lifecycle management features.
- Algorithms: Life cycle management uses an if/then logic in its lifecycle rules to move blobs through the access tiers and even to deletion based on modification in access times.
- Scope: Lifecycle management policies can be scoped at the storage account level or limited with blob filters.
- Types: It supports block and append blobs, and support subtypes such as the base blobs, snapshots, and versions of those blobs.
- Filtering: If we choose to limit blobs with filters, we could filter blobs in the rules using their prefix or blob index matches. The blob index feature is in public preview in specific regions. This is really just a tag that is natively searchable through Azure storage, not like a metadata tag that you might have on a blob.
Configuring Azure Blob Storage Lifecycle Management
For the purpose of this demonstration, we’ll use the source storage account and associated entities that we had created earlier to implement a lifecycle management policy on the blobs under it.
We’ll navigate to our source storage account demosource123 and under
the Data management section, click on Lifecycle management.
In the lifecycle management policy page, we’ll click on Add a rule.
In the details section, we’ll provide a name for our rule and will limit the scope to using filters and click Next.
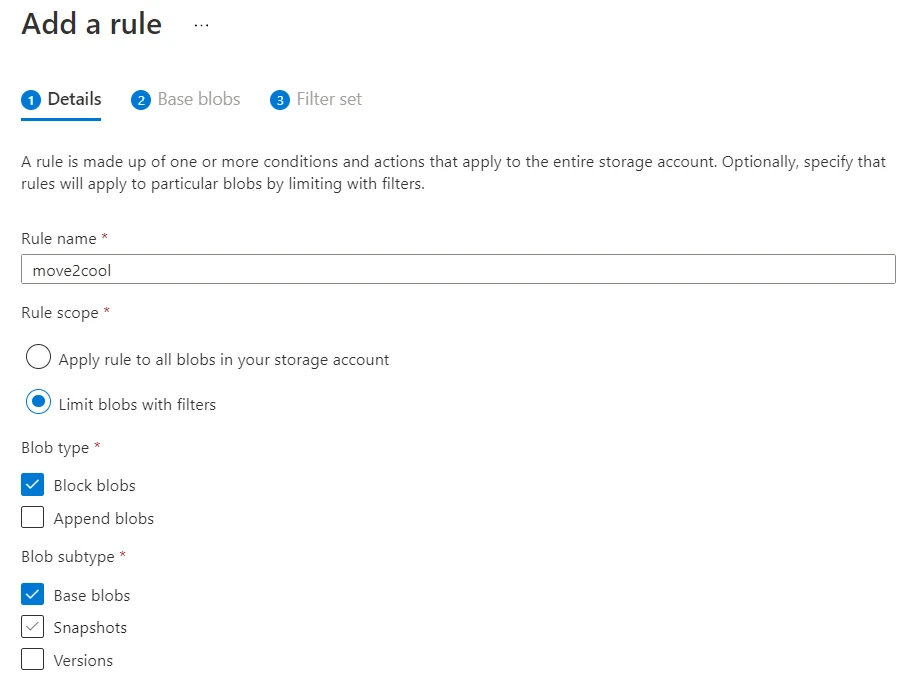
Now we will apply the conditional logic and specify the action to take when the condition is met.
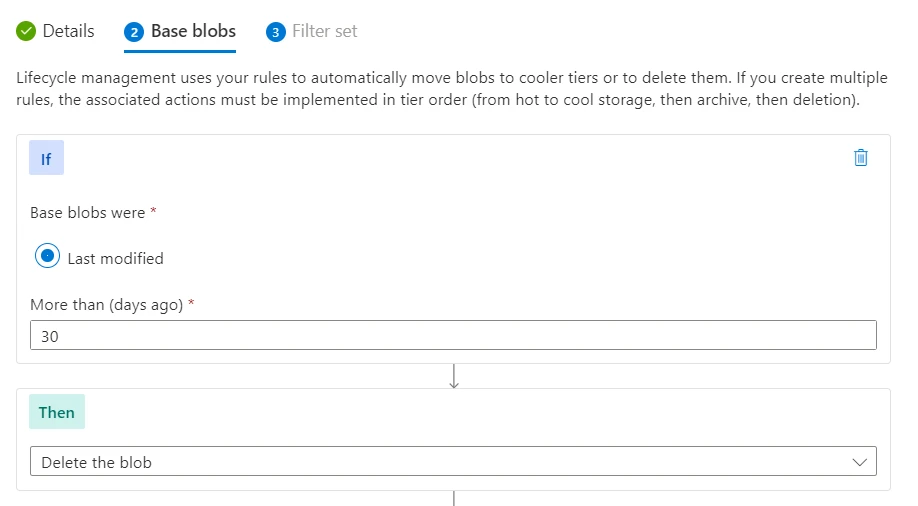
We’ve specified that we’d like to delete the blob if it hasn’t been modified in the last 30 days. From here click next. In the final portion of the rule creation, we’ll provide the Filters that we’d like to apply.
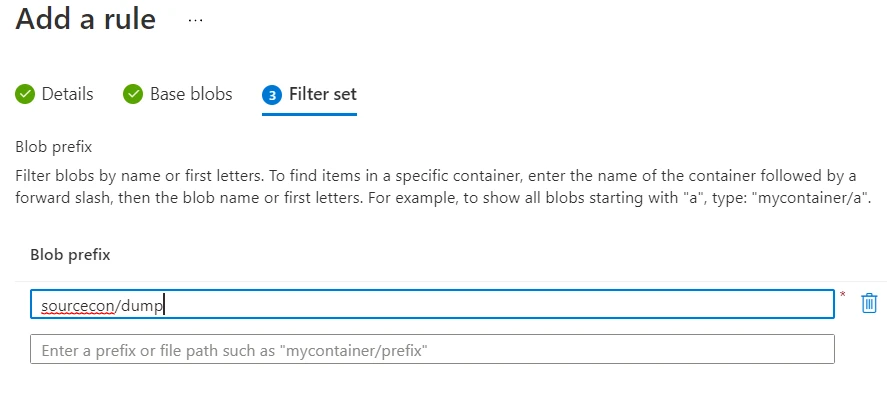
Since we had earlier created our sourcecon container and added the
file dumps.txt in it, we used the same content to construct the
filter. This blob prefix specifies that the rule will be applied to all
blobs starting with the name dump residing in the sourcecon container.
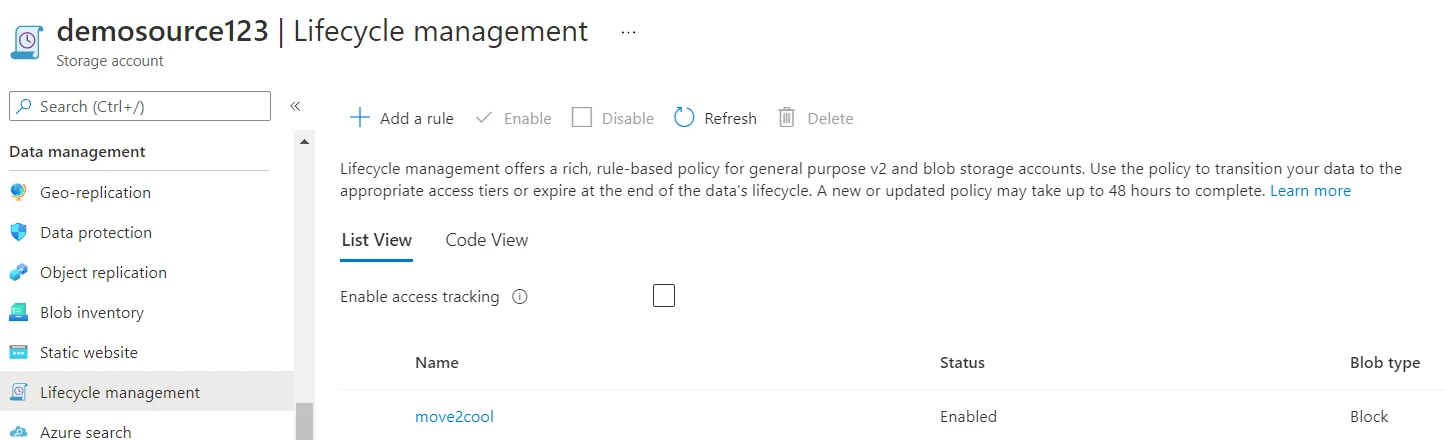
Now, click on the add button to create the rule.
The rule creation should take a couple of seconds after which it should be visible in the Azure blob storage lifecycle management page for the storage account.
Summary
In this article, we explored some interesting features pertaining to the management of Azure Blob storage. We explained and demonstrated blob object replication between regions and verified its implementation. Following which we discussed and demonstrated Azure blob storage lifecycle management while emphasizing its utility for cost optimization.
References
We referred to the official documentation for Microsoft Azure during the writing of this article. Links to the documentation have been shared below for further reading.
Configure object
replication for block blobs
Object replication for block
blobs
Optimize
costs by automatically managing the data lifecycle
Related Searches: azure blob storage lifecycle management, lifecycle management azure storage, azure storage lifecycle, azure storage account lifecycle management, azure storage retention policy, azure storage lifecycle management, blob lifecycle management
