You understand controller-runtime architecture—Manager, cache, workqueue, Reconcile. This article is the knobs layer: how to run more reconciles in parallel without corrupting shared state, how client QPS and burst interact with that parallelism, when cached vs uncached reads are correct, how predicates protect the apiserver, and what large-cluster patterns (indexers, scoped watches) buy you. When the control plane still pushes back, API Priority and Fairness (APF) is the last mile—usually a platform conversation, not a one-line code fix.
Prerequisites: watches and predicates, requeue and errors, Prometheus metrics so you can measure before and after each change.
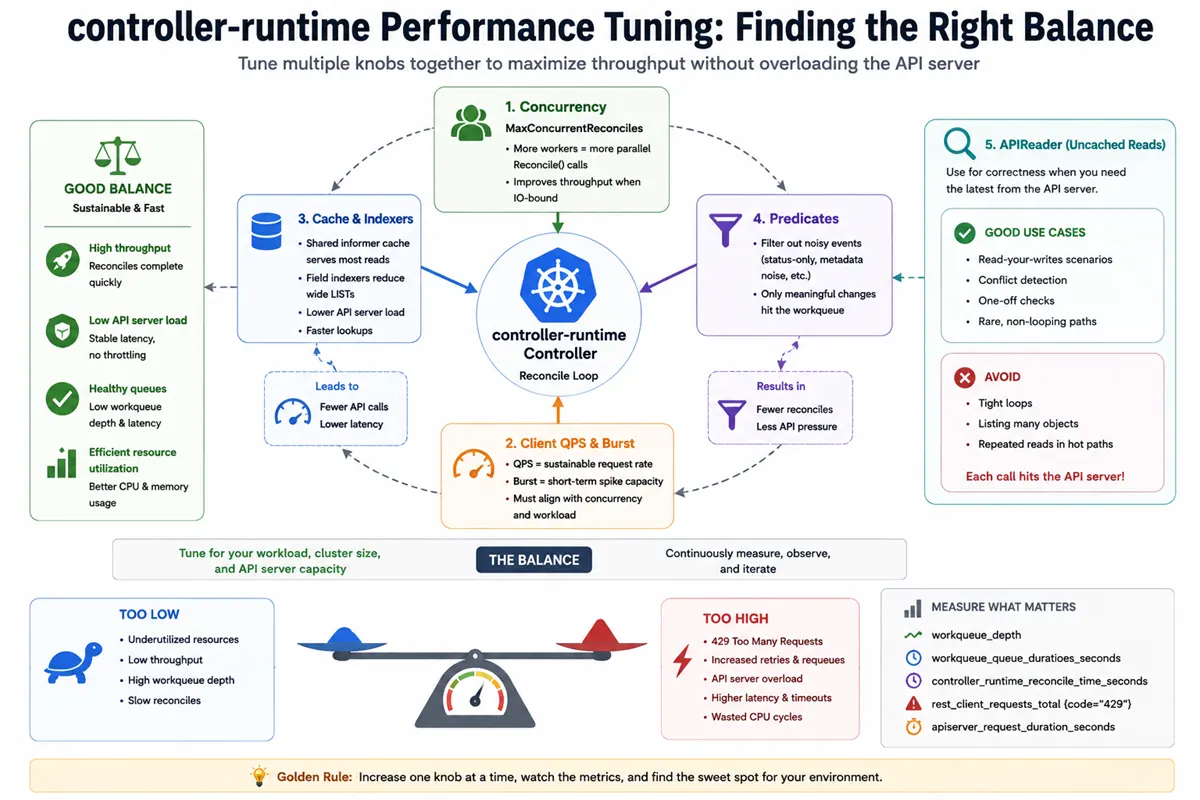
Performance tuning in 60 seconds
- Reduce unnecessary reconciles before adding more workers.
- Increase
MaxConcurrentReconcilesonly when reconcile work is independent and thread-safe. - Tune
QPSandBursttogether with concurrency; more workers without API budget causes throttling. - Prefer cached reads and use
APIReaderonly for rare paths requiring the latest object state. - Use predicates, scoped watches, and indexers to reduce the amount of work entering the queue.
- Treat API Priority and Fairness (APF) as a cluster-level capacity policy, not a replacement for efficient controller design.
MaxConcurrentReconciles and goroutine-safe reconcile
What it controls
Each Controller managed by the Manager drains its workqueue with a pool of worker goroutines. controller.Options{ MaxConcurrentReconciles: N } (Kubebuilder: ctrl.NewControllerManagedBy(...).WithOptions(controller.Options{...})) sets N parallel calls into your Reconcile for that controller.
- Default is low (typically 1)—safe for beginners, conservative for apiserver QPS.
- Increasing N raises throughput only if reconcile is blocked on I/O (API calls, HTTP) more than on CPU.
Correctness under concurrency
Assume different objects reconcile in parallel always, and that the same object can rarely be scheduled twice during races—your code must tolerate concurrent reconciles without:
- unsynchronized writes to package-level maps or caches;
- non-idempotent external side effects without leases / compare-and-swap;
- unbounded goroutines spawned from
Reconcilewithout backpressure.
If two reconcilers must never touch the same external resource concurrently, serialize with a mutex keyed by that resource, a single worker for that subsystem, or redesign ownership so only one CR drives it.
Choosing N
- Start with 2–4 on controllers that talk to the apiserver heavily.
- Watch
workqueue_depth,controller_runtime_reconcile_time_seconds, andrest_client_requests_total{code="429"}(metrics guide). - Increase N only when depth stays high and 429s do not climb.
Anti-pattern: MaxConcurrentReconciles: 32 with default QPS—you will throttle and retry, not fly.
Client QPS and burst on the REST config
The same *rest.Config you pass into ctrl.NewManager backs the delegating client, discovery, and metadata calls. Two fields dominate steady-state throttling:
| Field | Meaning |
|---|---|
QPS |
Average sustainable request rate to the apiserver (token bucket refill). |
Burst |
Short spike capacity above the average. |
Example before constructing the manager:
cfg := ctrl.GetConfigOrDie()
cfg.QPS = 100
cfg.Burst = 150
mgr, err := ctrl.NewManager(cfg, ctrl.Options{Scheme: scheme})Tune together with MaxConcurrentReconciles: more workers multiply concurrent PATCH storms on status-heavy operators. If rest_client_requests_total{code="429"} rises after raising concurrency, raise QPS/Burst modestly or reduce concurrency—never only raise QPS to “paper over” a hot reconcile loop (avoid reconcile explosions).
Cached client vs APIReader (uncached)
Default split client
The usual client.Client injected into reconcilers is a split client: reads come from the local informer cache (for types the cache watches), while writes go directly to the apiserver.
This makes Get and List operations cheap in both latency and apiserver QPS, but the cache is only eventually consistent. For a short period after a write, your next cached read may still return the previous object state until the informer processes the update event.
When to inject client.Reader / mgr.GetAPIReader()
Use the uncached API reader when you need the latest state from the apiserver, for example:
- reading immediately after creating or patching an object when a follow-up decision depends on the latest
resourceVersion, UID, or generated fields; - conflict retry paths where a stale cached object could repeatedly attempt a patch using an old
resourceVersion; - rare authorization, existence, or consistency checks where a small amount of cache lag is unacceptable.
Remember that APIReader is a correctness escape hatch, not a faster client. Every Get or List call becomes a real apiserver request.
Do not replace cached enumeration with API reads. A pattern such as List all Pods cluster-wide using APIReader inside every Reconcile will not scale and can easily become a source of API throttling.
Writes
Both the cached client and APIReader share the same write path; caching does not bypass Kubernetes optimistic concurrency checks.
Use Patch or Server-Side Apply (SSA) strategies where appropriate, handle conflicts explicitly, and design reconcile logic to tolerate stale reads and retries—see SSA in operators.
Predicate strategy to reduce unnecessary reconcile work
Predicates execute in the informer event path before a reconcile request enters the workqueue. They should be O(1), non-blocking, and should never perform API calls or expensive computations.
Predicates do not reduce the cost of watching resources—the informer has already received the event. Their value is preventing unnecessary reconcile requests, which indirectly reduces API traffic, CPU usage, and workqueue pressure.
High-value filters
predicate.GenerationChangedPredicate(or equivalent) to ignore status-only updates on the primary CR. This works best with a proper status subresource so status writes do not bump.metadata.generation.- Label, annotation, or namespace predicates when the operator only manages a subset of resources—for example, multi-tenant operators watching shared namespaces (multi-tenancy patterns).
- Child resource filters when using
Owns()on noisy objects such as Pods, where you only care about specific state transitions.
What predicates cannot fix
Predicates only control what reaches the workqueue. They cannot make an expensive Reconcile cheaper.
If every reconcile still performs wide List calls, expensive diffs, or slow external API operations, fix the data path instead:
- use field indexers instead of cluster-wide lists;
- rely on owner references and targeted watches;
- move expensive computations out of hot paths.
Anti-pattern: expensive predicate logic
Avoid predicates that call the Kubernetes API, query external systems, or deserialize large amounts of data just to decide whether to enqueue.
A predicate should answer a simple question:
"Is this event worth reconciling?"
Deep dive: watches, events, and predicates.
Large clusters: many CRs, hot namespaces, and indexers
Many CRs of the same Kind
Watch workqueue_adds_total, workqueue_depth, reconcile latency, API throttling, and manager memory usage as object counts grow.
If performance degrades linearly with the number of CRs, do not immediately add workers. First determine whether the bottleneck is:
- too many events entering the queue;
- expensive reconcile logic;
- wide
Listoperations; - API throttling (
429responses); - excessive cache size.
Fix the scaling bottleneck before increasing concurrency.
Hot namespaces and scoped caches
When the product is strictly tenant-scoped, prefer a namespace-scoped manager (WATCH_NAMESPACE) or a restricted cache.
Fewer watched objects means:
- lower manager memory consumption;
- fewer informer events to process;
- smaller cache synchronization time after startup;
- reduced accidental cross-tenant access.
For multi-tenant controllers that intentionally watch many namespaces, use label selectors, cache options, and careful RBAC design rather than assuming the entire cluster must be cached.
Field indexers
Register cache indexes for fields that you frequently query. An index allows client.MatchingFields to resolve lookups efficiently instead of performing a full List and filtering objects in Go.
A useful index is one that matches a common access pattern. Every index consumes memory and must be updated whenever cached objects change, so avoid indexing fields that you rarely query.
Examples:
- Index child resources by the owning CR name or UID.
- Index objects by a tenant, cluster, or environment identifier.
Anti-pattern: wide LISTs in every reconcile
Avoid patterns such as List all Secrets in the cluster on every reconcile just to find matching labels.
Prefer:
- owner references with targeted watches;
- field indexers for frequent lookups;
Watches()with custom mapping functions when a shared resource affects only a subset of CRs.
A controller that performs a cluster-wide List for every reconcile may work in development with 20 objects and fail badly in production with 20,000.
API Priority and Fairness (APF) when the operator saturates the apiserver
Symptoms
Watch for signals that the control plane is pushing back:
- Non-zero
rest_client_requests_total{code="429"}(metrics FAQ). - Rising reconcile latency and workqueue retries without obvious CPU saturation in the operator pod.
- Increased time waiting for API requests even though the reconcile logic itself is inexpensive.
First determine whether the throttling is coming from your own client-side QPS/Burst limits or from the apiserver enforcing APF limits.
What APF means
APF controls how the apiserver distributes limited request capacity between different clients. Your operator's ServiceAccount shares that capacity with Kubernetes controllers, kubectl users, admission webhooks, and other workloads.
A well-behaved operator should first reduce unnecessary API traffic:
- drop noisy events with predicates;
- prefer cached reads over unnecessary direct API calls;
- avoid excessive writes;
- tune
MaxConcurrentReconciles,QPS, andBurstwith real metrics.
Only after the controller is efficient should you consider FlowSchema or PriorityLevelConfiguration changes with platform owners.
Increasing APF shares for a noisy controller can simply allow it to generate more unnecessary load and affect other workloads.
APF is a cluster-wide policy decision—not something an application should ship and modify automatically without careful review.
Checklist before you declare “tuned”
- Baseline metrics captured (depth, reconcile seconds, 429 rate, Go
GOMAXPROCS). -
MaxConcurrentReconcileschanged with a hypothesis, not copy-paste. -
QPS/Burstdocumented in the runbook next to concurrency. - APIReader call sites counted per reconcile path (grep / static review).
- Predicates verified against status-only updates.
- Load test on a large fixture namespace or soak cluster.
FAQ
Does lowering concurrency always reduce apiserver load?
Usually yes for write-heavy reconciles; for CPU-bound reconciles it may only slow completion without helping the apiserver—profile first.
Does this apply to Helm-based operators?
The pre-built Helm operator reconciler is not your Go code—you tune chart size, watchDependentResources, and reconcilePeriod instead (Helm operator Part 2).
See also
- controller-runtime architecture
- Watches, events, and predicates
- Avoid reconcile loop explosions
- Multi-resource reconciliation
- Server-Side Apply in operators
- Operator multi-tenancy patterns
- Debugging operators
- Kubebuilder book: Controllers and webhooks
Bottom line: treat concurrency, QPS/burst, cache vs APIReader, and predicates as one system—raising workers without budget for API traffic buys 429s, not speed. Measure with the framework metrics, cut noise before you add power, and leave APF as a shared platform dial, not your first knob.