
Understanding golang concurrency
Concurrency is a property in programming where two or more tasks can be in progress simultaneously. More often than not, people confuse concurrency and parallelism. According to Rok Pike, Concurrency is all about dealing with a lot of things at once. Parallelism on the other hand is all about doing a lot of things at once. In real life parallelism examples are Multi-core CPUs , multiple cashiers at a grocery store or multiple people taking orders at a restaurant.
Thegoroutine is the core concept in Go’s concurrency model. Goroutinesare lightweight processes managed by the Go runtime. When a Go program starts, the Go runtime creates a number of threads and launches a single goroutine to run your program. All of the goroutines created by your program, including the initial one, are assigned to these threads automatically by the Go runtime scheduler, just as the operating system schedules threads across CPU cores.
You can start one simply by placing thegokeyword before a function:
func main() {
go sayHello()
// continue doing other things
}
func sayHello() {
fmt.Println("hello")
}Anonymous functions work too! Here’s an example that does the same thing as the previous example; however, instead of creating a goroutine from a function, we create a goroutine from an anonymous function:
go func() {
fmt.Println("hello")
}()
// continue doing other thingsAlternatively, you can assign the function to a variable and call the anonymous function like this:
sayHello := func() {
fmt.Println("hello")
}
go sayHello()
// continue doing other thingsGo follows a model of concurrency called the fork-join model. The word fork refers to the fact that at any point in the program, it can split off a child branch of execution to be run concurrently with its parent. The word join refers to the fact that at some point in the future, these concurrent branches of execution will join back together. Where the child rejoins the parent is called a join point.
Here’s a graphical representation to help you picture it:
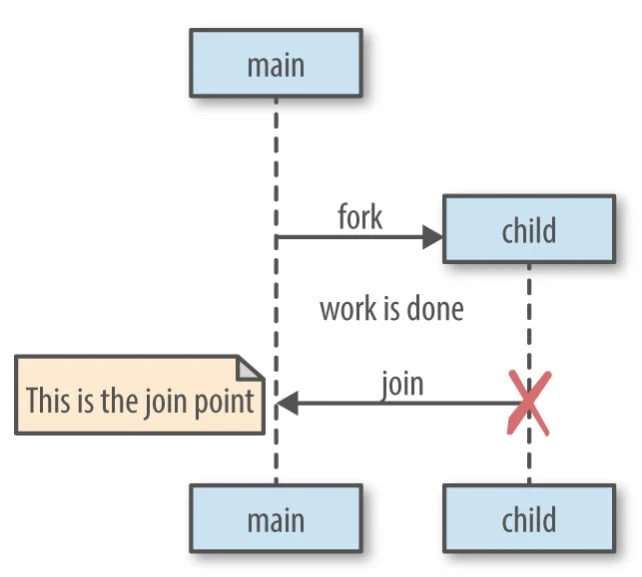
This article will dive into how to use all these concurrency patterns in our application and how they can be used together to achieve a goal.
Golang concurrency Best Practices
Goroutines, for Loops, and Varying Variables
Mostof the time, the closure that you use to launch a goroutine has no parameters. Instead, it captures values from the environment where it was declared. There is one common situation where this doesn’t work: when trying to capture the index or value of aforloop. This code contains a subtle bug:
package main
import "fmt"
func main() {
a := []int{2, 4, 6, 8, 10}
ch := make(chan int, len(a))
for _, v := range a {
go func() {
ch <- v * 2
}()
}
for i := 0; i < len(a); i++ {
fmt.Println(<-ch)
}
}We launch one goroutine for each value ina. It looks like we pass a different value in to each goroutine, but running the code shows something different:
20
20
20
20
20
The reason why every goroutine wrote 20 tochis that the closure
for every goroutine captured the same variable. The index and value
variables in aforloop are reused on each iteration. The last value
assigned tovwas 10. When the goroutines run, that’s the value that
they see. This problem isn’t unique toforloops; any time a goroutine
depends on a variable whose value might change, you must pass the value
into the goroutine. There are two ways to do this. The first is to
shadow the value within the loop:
for _, v := range a {
v := v
go func() {
ch <- v * 2
}()
}Ifyou want to avoid shadowing and make the data flow more obvious, you can also pass the value as a parameter to the goroutine:
for _, v := range a {
go func(val int) {
ch <- val * 2
}(v)
}Always Clean Up Your Goroutines to avoid goroutine leak
Wheneveryou launch a goroutine function, you must make sure that it will eventually exit. Unlike variables, the Go runtime can’t detect that a goroutine will never be used again. If a goroutine doesn’t exit, the scheduler will still periodically give it time to do nothing, which slows down your program. This is called agoroutine leak.
It may not be obvious that a goroutine isn’t guaranteed to exit. For example, say you used a goroutine as a generator:
package main
import "fmt"
func countTo(max int) <-chan int {
ch := make(chan int)
go func() {
for i := 0; i < max; i++ {
ch <- i
}
close(ch)
}()
return ch
}
func main() {
for i := range countTo(10) {
fmt.Println(i)
}
}In the common case, where you use all of the values, the goroutine exits. However, if we exit the loop early, the goroutine blocks forever, waiting for a value to be read from the channel:
func main() {
for i := range countTo(10) {
if i > 5 {
break
}
fmt.Println(i)
}
}Using a Cancel Function to Terminate a Goroutine
We can also use the done channel pattern to implement a pattern: return a cancellation function alongside the channel. The function must be called after theforloop:
package main
import "fmt"
func countTo(max int) (<-chan int, func()) {
ch := make(chan int)
done := make(chan struct{})
cancel := func() {
close(done)
}
go func() {
for i := 0; i < max; i++ {
select {
case <-done:
return
case ch <- i:
}
}
close(ch)
}()
return ch, cancel
}
func main() {
ch, cancel := countTo(10)
for i := range ch {
if i > 5 {
break
}
fmt.Println(i)
}
cancel()
}ThecountTofunction creates two channels, one that returns data and
another for signaling done. Rather than return the done channel
directly, we create a closure that closes the done channel and return
the closure instead. Cancelling with a closure allows us to perform
additional clean-up work, if needed.
Turning Off a case in a select
Whenyou need to combine data from multiple concurrent sources, theselectkeyword is great. However, you need to properly handle closed channels. If one of the cases in aselectis reading a closed channel, it will always be successful, returning the zero value. Every time that case is selected, you need to check to make sure that the value is valid and skip the case. If reads are spaced out, your program is going to waste a lot of time reading junk values.
When that happens, we rely on something that looks like an error: reading anilchannel. As we saw earlier, reading from or writing to anilchannel causes your code to hang forever. While that is bad if it is triggered by a bug, you can use anilchannel to disable acasein aselect. When you detect that a channel has been closed, set the channel’s variable tonil. The associated case will no longer run, because the read from thenilchannel never returns a value:
// in and in2 are channels, done is a done channel.
for {
select {
case v, ok := <-in:
if !ok {
in = nil // the case will never succeed again!
continue
}
// process the v that was read from in
case v, ok := <-in2:
if !ok {
in2 = nil // the case will never succeed again!
continue
}
// process the v that was read from in2
case <-done:
return
}
}Using timeout for goroutines
Mostinteractive programs have to return a response within a certain amount of time. One of the things that we can do with concurrency in Go is manage how much time a request (or a part of a request) has to run. Other languages introduce additionalfeatureson top of promises or futures to add this functionality, but Go’s timeout idiom shows how you build complicated features from existing parts.
func timeoutMyFunc(timeout time.Duration, myFunc func()) bool {
finished := make(chan bool)
go func() {
myFunc()
finished <- true
}()
select {
case <-time.After(timeout):
return false
case <-finished:
return true
}
}
func main() {
success := timeoutMyFunc(3*time.Second, func() {
/*
* Place your code here
*/
})
}Using WaitGroups
Goroutines are simply functions or methods that run simultaneously. For more details about Go Channels please readhere. To be able to execute a goroutine, add the go keyword before a function or a method that converts it into a goroutine. On the other hand, Go WaitGroup is a feature that ensures that all goroutines are executed before the main goroutine terminates the program. These two work together to achieve seamless concurrency. In the example we are going to simulate a program that checks the status code of different websites.
package main
import (
"fmt"
"net/http"
"sync"
)
func main() {
var waitgroup sync.WaitGroup
links := []string{
"https://www.golinuxcloud.com",
"https://www.google.com",
"https://twitter.com",
"https://www.tesla.com",
"https://www.amazon.com",
}
waitgroup.Add(len(links))
for _, link := range links {
go func(link string) {
defer waitgroup.Done()
response, err := http.Get(link)
if err != nil {
fmt.Println("Error: ", err)
return
}
fmt.Printf("[ %s ] -> %d \n", link, response.StatusCode)
}(link)
}
waitgroup.Wait()
fmt.Println("Done..")
}Explanation.
In the above example, we use Go WaitGroups with goroutines to achieve concurrency. How do these two work together ? Well , normally the main thread executes in the order in which it reads code, top to bottom, left to right. When the main goroutine encounters a goroutine, it calls it and moves to the next line. When the Go WaitGroup is added, the main goroutine is forced to wait for other goroutines to finish their business.
The Go WaitGroups has three methods that it calls in order for the
goroutines to work concurrently. These methods
areAdd(),Done()andWait(). TheAdd()method takes a counter
which is the number of
goroutines
that will be used. TheDone()function decreases the internal counter
by one after each goroutine is executed. TheWait()method tracks the
internal counter and releases the control back to the main goroutine
when the counter is 0.
Output:
$ go run test.go
[ https://www.golinuxcloud.com ] -> 200
[ https://www.google.com ] -> 200
[ https://www.amazon.com ] -> 200
[ https://www.tesla.com ] -> 200
[ https://twitter.com ] -> 200
Done..
Goroutines and Mutex
In the
previous section we have seen how channels are great for communication among
goroutines(ping(), ping() and pongError()). Goroutines can also work
simultaneously and race against each other as they try to access and
modify a resource. When this happens, it leads to a phenomenon called
race condition(mutual exclusion). Go provides the mutex data structure
to prevent race condition by locking and unlocking critical
variables(memory locations) that goroutines might want to access and
modify at the same time. The standard library provides two kinds of
mutex namely sync.Mutex and sync.RWMutex. The latter is optimized
for cases where your program deals with many readers and few writer and
readers. For more information you can refer
Go Mutex.
Example
package main
import (
"fmt"
"sync"
"time"
)
type updateBalance struct {
mx sync.Mutex
balance int
}
func (u *updateBalance) deposite(wg *sync.WaitGroup, amount int) {
u.mx.Lock()
defer u.mx.Unlock()
defer wg.Done()
u.balance += amount
time.Sleep(time.Second)
}
func (u *updateBalance) getBalance(wg *sync.WaitGroup) {
u.mx.Lock()
defer u.mx.Unlock()
defer wg.Done()
fmt.Printf("Current balance is %d \n", u.balance)
}
func main() {
var wg sync.WaitGroup
u := updateBalance{balance: 0}
wg.Add(5)
for i := 0; i < 5; i++ {
go u.deposite(&wg, 1000)
}
go u.getBalance(&wg)
wg.Wait()
fmt.Println("Done")
}Explanation
In the above example, we define an updateBalance struct type that has
mutex and int types as its fields. The updateBalance struct has
two methods(goroutines) name deposit() and getBalance() . The
deposit() method updates the balance variable that it locked using
the u.mx.Lock() method. This means that one goroutine gets to update
the balance attribute one at a time. At the same time the getBalance()
goroutine reads the balance. These two methods access the same attribute
without causing any race conditions thanks to the Mutex lock and unlock
mechanism, hence achieving concurrency.
Output
$ go run -race main.go
Done
Current balance is USD 5000
Goroutines and Atomic
Package sync/atomic provides low-level atomic primitives useful for
implementing synchronization algorithms. Atomic operations from the
sync/atomic package are lockless and are generally implemented at
hardware level. The sync/atomic package helps achieve synchronization
when doing concurrency. sync/atomic does the same thing as mutex does
when it comes to protecting shared variables(memory address) and
preventing race condition , but they are more performant and fast
compared to mutex.
The atomic package contains the load(), store() and addition()
operations for the int32, int64, uint32, uint64.
Example
package main
import (
"fmt"
"sync"
"sync/atomic"
)
func inc(counter *uint32, wg *sync.WaitGroup) {
defer wg.Done()
for i := 0; i < 50; i++ {
atomic.AddUint32(counter, 1)
}
}
func main() {
var counter uint32
var wg sync.WaitGroup
wg.Add(3)
go inc(&counter, &wg)
go inc(&counter, &wg)
go inc(&counter, &wg)
wg.Wait()
fmt.Printf("Counter value is %d \n", counter)
}Explanation
In the above example we define the inc() goroutine that takes an
argument, counter and wait group. The sole purpose of the inc()
goroutine is to increase the value of a counter variable by one using
the atomic.AddUint32() method. This means the counter variables can be
updated by many goroutines, but there will be no race conditions.
In the main function we spin three goroutines that race to update the counter variable but there will be none race condition experienced.
Output
$ go run main.go
Counter value is 150
Goroutines, channels and Select statement
In the spirit of concurrency in Go, select statement lets a goroutine to wait for multiple communication operations. The select statement will block until one of its cases can run. If this happens, the case will be executed. If multiple cases are ready at the same time, it will choose one at random hence achieving concurrency.
Example
package main
import (
"fmt"
)
func main() {
channel1 := make(chan string)
channel2 := make(chan string)
go func() {
channel1 <- "Channel 1 message"
}()
go func() {
channel2 <- "Channel 2 message"
}()
for i := 0; i < 2; i++ {
select {
case msg1 := <-channel1:
fmt.Println(msg1)
case msg2 := <-channel2:
fmt.Println(msg2)
}
}
fmt.Println("Done")
}Output
$ go run main.go
Channel 2 message
Channel 1 message
Done
Summary
We’ve looked at concurrency and learned why Go’s approach is simpler
than more traditional concurrency mechanisms. In doing so, we’ve also
clarified when you should use concurrency and learned a few concurrency
rules and patterns. Concurrency is an important aspect in building fast
and performant applications that deal with many operations at the same
time. This tutorial provides rich examples of achieving concurrency
using channels, Mutex and atomic operations. They all perform well , but
the atomic operations from sync.atomic are fast and performant.




![Convert Go []byte to string (Casting, Builder, Buffer, strconv)](/go-bytes-to-string/golang-byte-to-string_hu_e77d43b219043453.webp)



