![How to use CloudFront with S3 [Practical Example]](/how-to-use-cloudfront-with-s3/cloudfront_s3-800w.webp)
In this tutorial, we are going to learn that how to use CloudFront with S3. But before we learn to use CloudFront with S3, let's have a look at what Amazon CloudFront is.
What is Amazon CloudFront?
Amazon CloudFront is a web service that speeds up the distribution of our static and dynamic web content, such as .html, .css, .js, and image files, to our users. CloudFront delivers our content through a worldwide network of data centers called edge locations. When a user requests content that we're serving with CloudFront, the request is routed to the edge location that provides the lowest latency (time delay), so that content is delivered with the best possible performance.
- If the content is already in the edge location with the lowest latency, CloudFront delivers it immediately.
- If the content is not in that edge location, CloudFront retrieves it from an origin that we've defined— for our tutorial, we will use CloudFront with S3 Bucket.
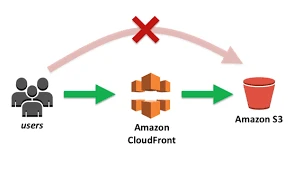
Use CloudFront with S3
Before we learn to use CloudFront with S3, let's have a look at Amazon CloudFront Key Features.
Amazon CloudFront Key Features
Following are the key features of Amazon CloudFront.
1. Global Edge Network
Amazon CloudFront provides reliable, low latency, and high throughput network connectivity. It peers with thousands of Tier 1/2/3 telecom carriers globally, is well connected with all major access networks for optimal performance, and has hundreds of terabits of deployed capacity. CloudFront Edge locations are connected to the AWS Regions through the AWS network backbone - fully redundant, multiple 100GbE parallel fiber that circles the globe and links with tens of thousands of networks for improved origin fetches and dynamic content acceleration. Edge locations are located in North America, Europe, Asia, Australia & New Zealand, South America, the Middle East, Africa, and China.
2. Security
Amazon CloudFront provides protection against Network and Application Layer Attacks. CloudFront, AWS Shield, AWS Web Application Firewall (WAF), and Amazon Route 53 work seamlessly together to create a flexible, layered security perimeter against multiple types of attacks. With Amazon CloudFront, content, APIs, or applications can be delivered over HTTPS using the latest version Transport Layer Security (TLSv1.3) to encrypt and secure communication between viewer clients and CloudFront. Access can be restricted to content through a number of capabilities using Amazon CloudFront with signed URLs, signed Cookies, geo-restriction capability, and Origin Access Identity (OAI) feature. Moreover, CloudFront infrastructure and processes are all compliant with PCI-DSS Level 1, HIPAA, and ISO 9001, ISO/IEC 27001:2013, 27017:2015, 27018:2019, SOC (1, 2 and 3), FedRAMP Moderate, and more to ensure secure delivery for sensitive data.
3. Availability
The volume of application origin requests is automatically reduced by using Amazon CloudFront as content is stored in its edge and regional caches and only fetched from origins when needed. The load on application origins can be further reduced by using Origin Shield to enable a centralized caching layer. Moreover, CloudFront also supports multiple origins for backend architecture redundancy. When the primary origin is unavailable, CloudFront’s native origin failover capability automatically serves content from a backup origin.
4. Edge Computing
Amazon CloudFront offers programmable and secure edge CDN computing capabilities through CloudFront Functions and AWS Lambda@Edge. CloudFront Functions is ideal for high scale and latency-sensitive operations like HTTP header manipulations, URL rewrites/redirects, and cache-key normalizations. AWS Lambda@Edge is a general-purpose serverless compute feature that supports a wide range of computing needs and customizations. Lambda@Edge is best suited for computationally intensive operations. This could be computations that take longer to complete (several milliseconds to seconds), take dependencies on external 3rd party libraries, require integrations with other AWS services (e.g. S3, DynamoDB), or need network calls for data processing.
5. Real-time Metrics and Logging
Amazon CloudFront is integrated with Amazon CloudWatch, and automatically publishes six operational metrics per distribution, which are displayed in a set of graphs in the CloudFront console. Additional, granular metrics are available with a simple click on the console or via API. Moreover, it provides two ways to log the requests delivered from your distributions: Standard logs and Real-time logs. Standard logs are delivered to the Amazon S3 bucket of our choice. CloudFront real-time logs are delivered to the data stream of our choice in Amazon Kinesis Data Streams.
6. DevOps Friendly
CloudFront offers fast change propagation and invalidations, within a matter of minutes. Typically, changes are propagated to the edge in a matter of a few minutes, and invalidation times are under two minutes. It provides developers with a full-featured API to create, configure and maintain CloudFront distributions. In addition, developers have access to a number of tools such as AWS CloudFormation, CodeDeploy, CodeCommit, and AWS SDKs to configure and deploy their workloads with Amazon CloudFront. Our CloudFront Distribution can be configured with multiple behaviors which govern how CloudFront will process our request and what features will be applied. We can customize CloudFront behaviors, such as: how CloudFront caches, how it communicates with our origin, what headers and metadata are forwarded to our origin, creation of content variants with flexible cache-key manipulation, selection of compression modes, what headers are added to your HTTP responses, and more.
7. Cost-Effective
CloudFront offers personalized pricing options including pay-as-you-go, the CloudFront Security Savings Bundle, and custom pricing.If AWS origins such as Amazon S3, Amazon EC2, or Elastic Load Balancing are used, there is no charge incurred for data transferred from origins to CloudFront Edge locations (this type of data transfer is known as origin fetch). Not all origins are alike and some may involve processes such as just-in-time packaging that are more computationally expensive per GB than fetching content out of storage. CloudFront provides regional edge caches at no additional cost to decrease the operational burden on origins and lower operating costs. Further reductions in origin-related costs are available using Origin Shield to minimize the number of origin fetches.
Now let's get started with the implementation part where we will use CloudFront with S3.
Use CloudFront with S3
First, we will log in to our AWS account and create an S3 bucket then we will create CloudFront Distribution for our S3 Bucket so that we can use CloudFront with S3.
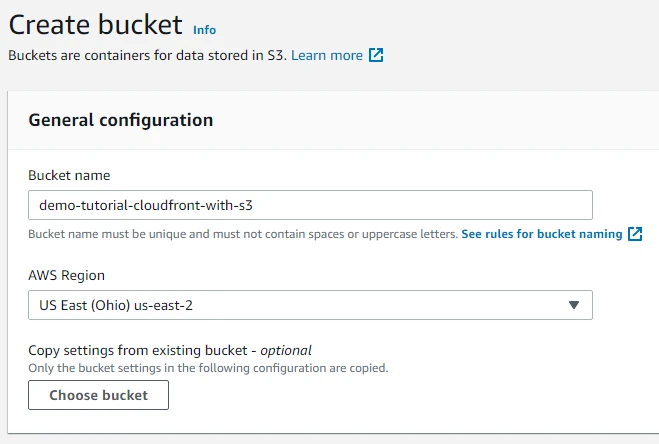
1. Create s3 bucket
Since we will use CloudFront with S3 so for that first we will create an S3 bucket. Here we will only provide the bucket name and leave the rest of the configurations to default and then click on Create Bucket.
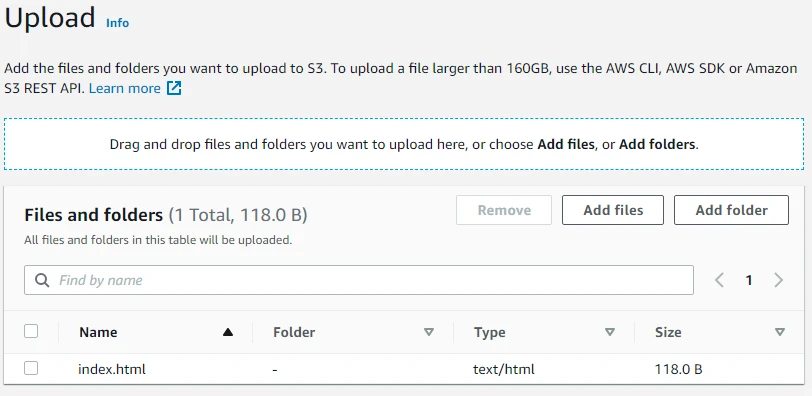
Now we will upload the index.html file to our bucket. This file only contains simple text for demo purposes.
Now we have our bucket ready to use CloudFront with S3.
2. Create Distribution
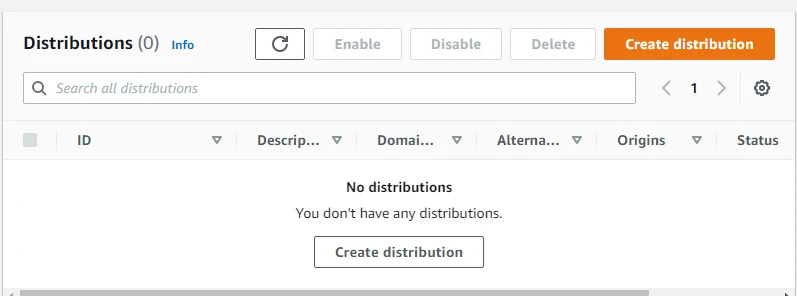
Now we will create CloudFront Distribution for our bucket. Currently, we do not have any distributions. We will click on Create Distribution.
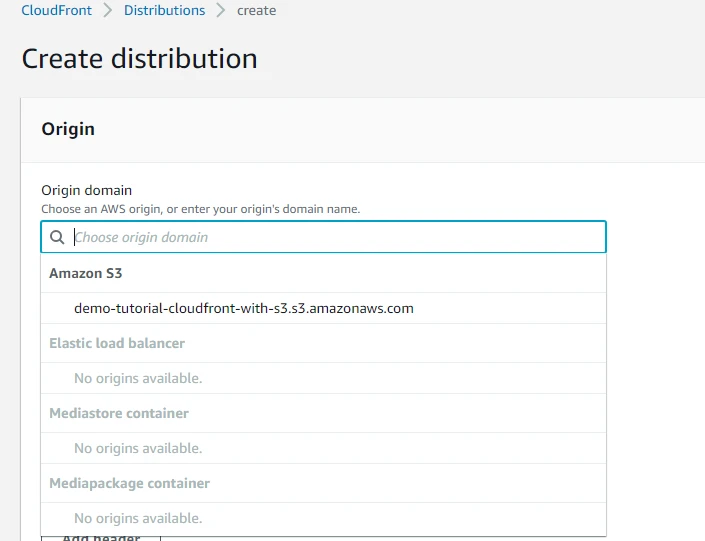
Here we will provide the Origin domain which in our case is from Amazon S3 i.e. demo-tutorial-cloudfront-with-s3.s3.amazonaws.com. Note that an origin is a location where content is stored, and from which CloudFront gets content to serve to viewers.
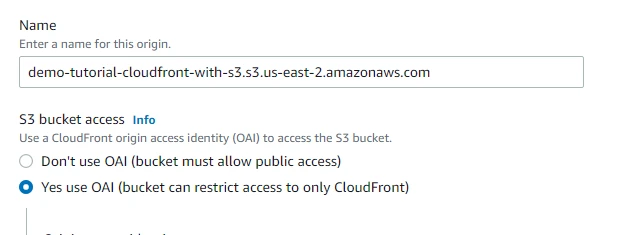
In S3 bucket access, we will select Yes use OAI as we are only restricting user access to CloudFront. To restrict access to content that we serve from Amazon S3 buckets, these steps are followed.
- Creation of a special CloudFront user called an origin access identity (OAI) and its association with our distribution.
- Configuration of S3 bucket permissions so that CloudFront can use the OAI to access the files in our bucket and serve them to our users. Make sure that users can’t use a direct URL to the S3 bucket to access a file there.
After these steps are taken, users can only access our files through CloudFront, not directly from the S3 bucket.
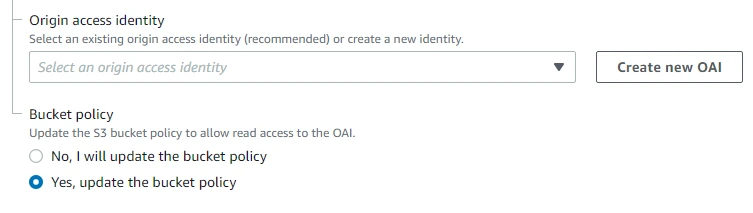
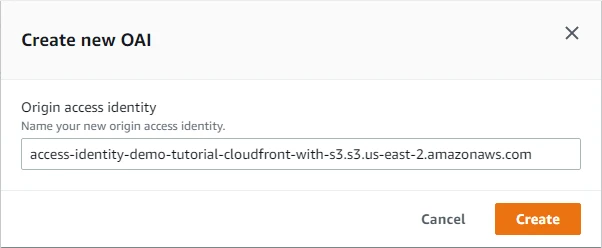
In Origin access identity, we will click on Create new OAI. For Bucket policy, we will select Yes, update the bucket policy. Here we are updating the bucket policy to allow read access to the OAI.
Here we will get a default name for OAI then we will click on Create.
In the Default root object, we will write the name of the file i.e. index.html that we uploaded to our bucket.

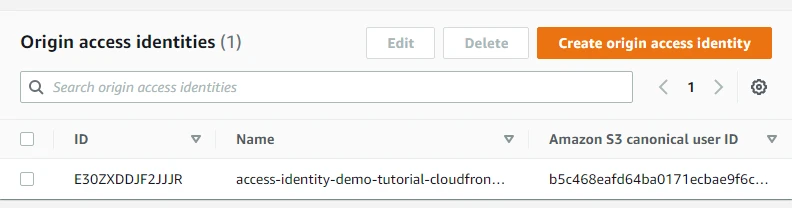
Now after creating our distribution we can view our newly created OAI.
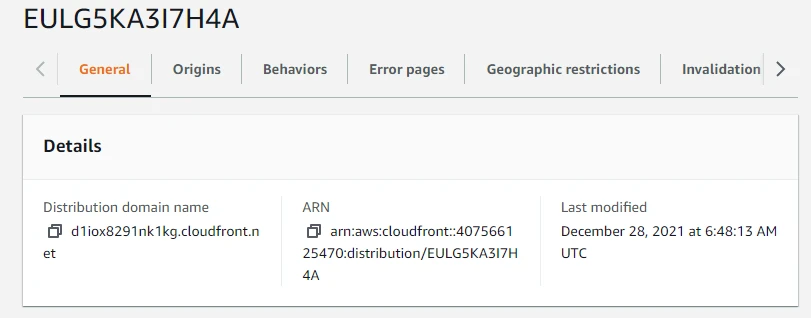
Now to check whether things are working properly let's test our CloudFront Distribution. We will copy the Distribution domain name and enter it into our browser.
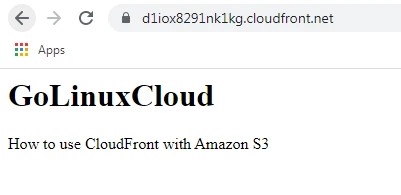
Our CloudFront Distribution is working perfectly fine. We have successfully learned that how to use CloudFront with S3.
3. Caching and Invalidations
In order to view cache policy, we will go to the Behaviours tab and click on Edit.
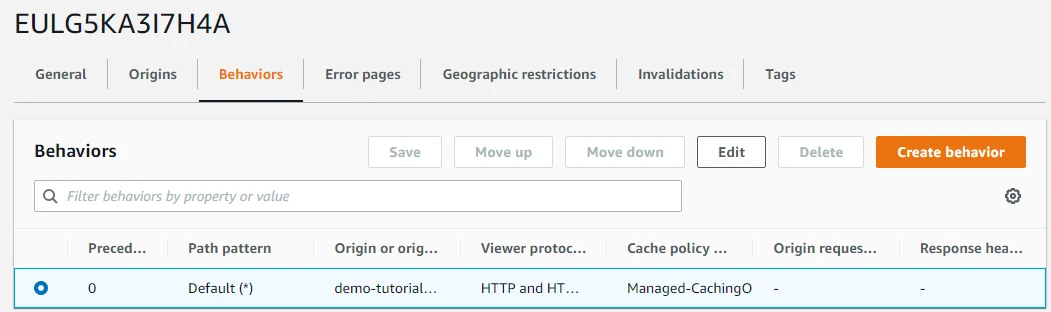
Here we will click on View policy that will open a new window for us.
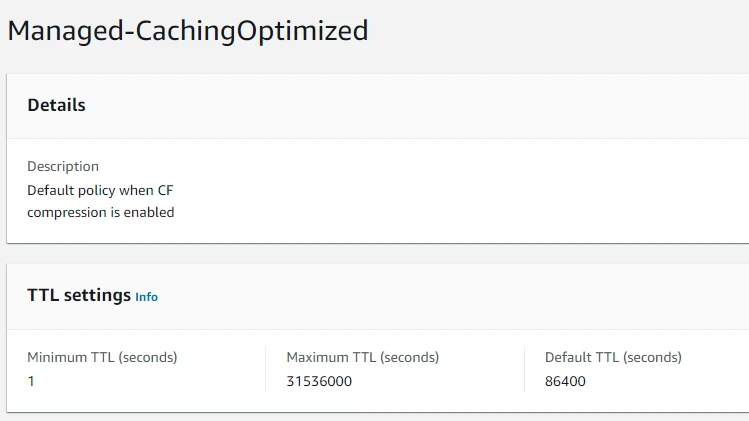
In our TTL settings, we can see that the values of Minimum TTL, Maximum TTL, and Default TTL are 1, 31536000, and 86400 seconds respectively. Since we are using the Default TTL, so data in our cache will reside for one whole day. We can also create our own cache policy based on our requirements.
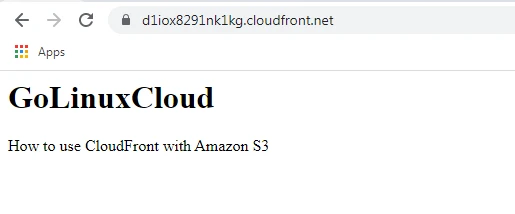
Now let's see the working of cache. First, we will update our file in the S3 bucket. Then we will open our file from there directly with a pre-signed URL. Here we can see our updated web page.

Now when we access our web page from CloudFront Domain we can clearly see that the webpage is not updated. That means data is retrieved from the cache and not from the S3 bucket directly.
4. Create Invalidation
If we need to remove a file from CloudFront edge caches before it expires, we can invalidate the file from edge caches. By creating invalidation, the next time a viewer requests the file, CloudFront returns to the origin to fetch the latest version of the file. Here we will click on Create invalidation.
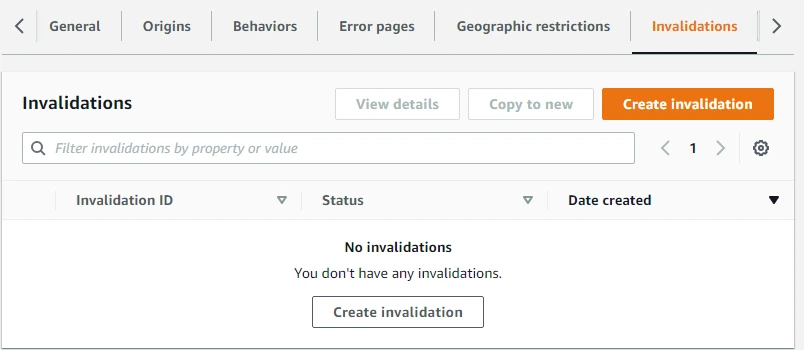
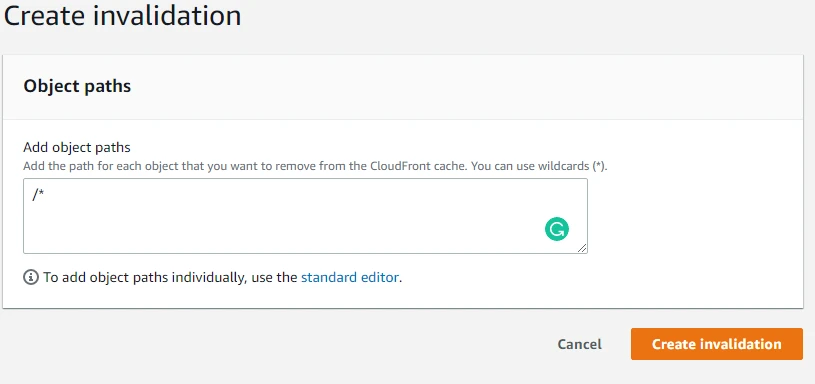
Here we enter /* in Add object paths and then click on Create invalidation. Through /* we are invalidating all the files in the distribution. We can also add the path for each object that we want to remove from the CloudFront cache.
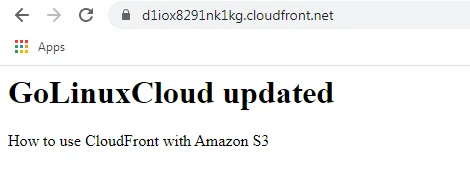
Now when we enter the URL again we can see the updated web page which shows that our cache has been invalidated.
With this, we are all geared up now to use CloudFront with S3.
Conclusion
With this, we have come to the end of our tutorial. In this tutorial, we learned that how to use CloudFront with S3. First, we learned about Amazon CloudFront and its key features. After that, we created an S3 bucket followed by CloudFront Distribution so that we could use CloudFront with S3. And in the end, we also explored the cache invalidation feature of Amazon CloudFront.
Stay tuned for some more informative tutorials coming ahead. Feel free to leave any feedback or query in the comments section.
Happy learning!

![Tutorial: Getting started with AWS AppSync [Hands On]](/aws-appsync-tutorial/aws_appsync_hu_150f68098b21ac7a.webp)