
In this tutorial, we will add worker node to an existing Kubernetes Cluster. You can also use auto-scaling to automatically add or remove worker nodes based on your load and environment. But if you have setup a Kubernetes Cluster manually using kubeadm without auto-scaling, then you can use the steps from this article to add a new worker node to your existing cluster.
Lab Environment
This article assumes that you already have pre-installed Kubernetes
Cluster. I have created my cluster using Oracle VirtualBox VMs where one VM is acting as the
controller while the other one is worker node. I have created one more
Linux VM with CentOS 8 and will add this node to my existing Kubernetes
Cluster using kubeadm join command.
Following are the specs of my Kubernetes Cluster. Here I have removed
worker-2.example.com in my previous article. Now I will add worker-3.example.com to this cluster.
| Resources | controller | worker-1 | worker-3 (To be added) |
|---|---|---|---|
| OS | CentOS 8 | CentOS 8 | CentOS 8 |
| hostname | controller | worker-1 | worker-3 |
| FQDN | controller.example.com | worker-1.example.com | worker-3.example.com |
| Storage | 20GB | 20GB | 20GB |
| vCPU | 2 | 2 | 2 |
| RAM | 6GB | 6GB | 6GB |
| Adapter-1 (Bridged) | 192.168.0.150 | 192.168.0.151 | 192.168.0.153 |
Pre-requisites to bring up worker node
If you are familiar with the Kubernetes Architecture then you will know that we must setup some mandatory pre-requisites to able to configure a worker node. There are certain pre-requisites which must be configured before you add your worker node to the cluster.
Install CentOS 8
You can choose to install your own variant of Operating System. I will use CentOS 8 for my worker nodes. You can follow step by step instructions to install CentOS on your VM. If you are not familiar with CentOS 8 installation steps and want to choose the easy way then you can download CentOS 8 image from OSBoxes CentOS images where you just need to deploy the downloaded file in the VirtualBox and you will have a pre-install virtual machine up and running without any manual steps.
Update /etc/hosts
We must make sure that all the nodes in the Kubernetes cluster are able
to communicate with each other using hostnames. You can do this by
configuring your own BIND DNS server or the alternative would be to use /etc/hosts file.
Following is a sample content from my worker node:

DNS Resolution
CentOS and some other Linux distributions use a local DNS resolver by
default (systemd-resolved). Systemd-resolved moves and replaces
/etc/resolv.conf with a stub file that can cause a fatal forwarding
loop when resolving names in upstream servers.
This can be fixed manually by using kubelet's --resolv-conf flag to
point to the correct resolv.conf (With systemd-resolved, this is
/run/systemd/resolve/resolv.conf). kubeadm automatically detects
systemd-resolved, and adjusts the kubelet flags accordingly. So we will
enable and start systemd-resolved service. In RHEL/CentOS, this
service is owned by systemd-239 package so you can install it if this is
missing:
Enable or disable the unit at boot with systemctl enable; the systemctl command documents enable --now, symlinks under /etc/systemd/system, and masks.
[root@worker-3 ~]# systemctl enable systemd-resolved --now
Created symlink /etc/systemd/system/dbus-org.freedesktop.resolve1.service → /usr/lib/systemd/system/system-resolved.service.
Created symlink /etc/systemd/system/multi-user.target.wants/systemd-resolved.service → /usr/lib/systemd/sytem/systemd-resolved.service.
Disable Swap Memory
At the time of writing this article, kubelet was not compatible with
swap memory hence it is important that you disable swap memory.
[root@worker-3 ~]# swapoff -a
Also make sure that swap is not enabled after reboot, so to make the
changes persistent you can modify /etc/fstab and comment out the line
for swap memory
#/dev/mapper/rhel-swap swap swap defaults 0 0
Verify the same using free command:
[root@controller ~]# free -m
total used free shared buff/cache available
Mem: 6144 454 5207 9 472 3100
Swap: 0 0 0
Set SELinux to Permissive mode
You can either
disable or change SELinux mode to Permissive. To change the SELinux mode to Permissive you
can use:
[root@worker-3 ~]# setenforce 0
Next verify the current mode to check the active mode:
[root@worker-3 ~]# getenforce
Permissive
But these changes will not survive reboot so we also need to update the
mode in /etc/selinux/config file:
[root@controller ~]# sed -i --follow-symlinks 's/SELINUX=enforcing/SELINUX=permissive/g' /etc/sysconfig/selinux
The setenforce command has already changed the ode for current session
so these changes do not require any service or system restart.
Enable required firewall ports
Following are the ports required on the worker node:
| Port range | Protocol | Purpose |
|---|---|---|
| 10250 | TCP | This port is used for Kubelet API |
| 30000-32767 | TCP | NodePort Services |
| 179 | TCP | Calico networking (BGP) |
We are using firewalld on our CentOS 8 environment. So we will use
firewalld to allow required ports in the firewall. If you are using
a different network plugin then make sure you enable the ports required
by the respective CNI. We are using Calico CNI on our cluster.
[root@worker-3 ~]# firewall-cmd --add-port 10250/tcp --add-port 30000-32767/tcp --add-port=179/tcp --permanent
[root@worker-3 ~]# firewall-cmd --reload
[root@worker-3 ~]# firewall-cmd --list-ports
10250/tcp 30000-32767/tcp 179/tcp
Configure Networking
It is recommended to use the same network for your primary LAN as used with other controller and worker nodes. This is because kubeadm while initializing stage generates API address and it should be reachable for all the worker nodes.
Make sure that the br_netfilter module is loaded. This can be done by
running
# lsmod | grep br_netfilter.
To load it explicitly execute the following command:
[root@worker-3 ~]# modprobe br_netfilter
Now re-verify the module status:
[root@worker-3 ~]# lsmod | grep br_netfilter
br_netfilter 24576 0
bridge 192512 1 br_netfilter
As a requirement for your Linux Node's iptables to correctly see bridged
traffic, you should ensure net.bridge.bridge-nf-call-iptables is set
to 1 in your sysctl config:
[root@worker-3 ~]# cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
Activate the newly added changes runtime:
[root@worker-3 ~]# sysctl --system
Install container runtime (Docker CE)
There are multiple
container runtime available which you can choose for your Kubernetes
Cluster. Since we are already using Docker CE container on all our
cluster nodes, so we will install the same on worker-3 as well.
Before we install the docker runtime, let us install the pre-requisite rpms
[root@worker-3 ~]# dnf install -y yum-utils device-mapper-persistent-data lvm2
Next add the docker repository to install the container runtime:
[root@worker-3 ~]# yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
Adding repo from: https://download.docker.com/linux/centos/docker-ce.repo
Now that we have our repository in place, we can install the docker CE container using YUM or DNF:
[root@worker-3 ~]# dnf install containerd.io docker-ce docker-ce-cli -y
Configure the Docker daemon, in particular to use systemd for the management of the container’s cgroups.
[root@worker-3 ~]# mkdir -p /etc/docker
[root@worker-3 ~]# cat <<EOF | sudo tee /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
overlay2 is the preferred storage driver for systems running Linux
kernel version 4.0 or higher, or RHEL or CentOS using version 3.10.0-514
and above.
Restart Docker and enable on boot:
[root@worker-3 ~]# systemctl restart docker
[root@worker-3 ~]# systemctl enable docker
Created symlink /etc/systemd/system/multi-user.target.wants/docker.service → /usr/lib/systemd/system/docker.service.
Check the status of docker service:
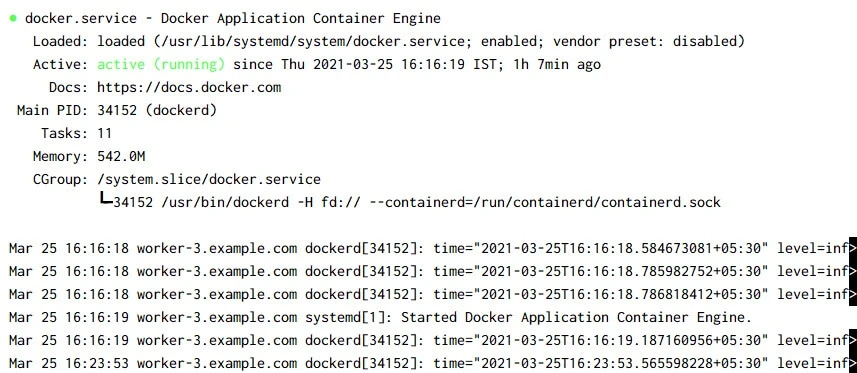
Install Kubernetes Components
Next we need to install the mandatory components to manage our worker node:.
- kubeadm: the command line utility to bootstrap the cluster.
- kubelet: the component that runs on all of the machines in your cluster and does things like starting pods and containers.
- kubectl: the command line utility to talk to your cluster.
Create the Kubernetes repository file on all the nodes which will be used to download the packages:
~]# ~]# cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-\$basearch
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
exclude=kubelet kubeadm kubectl
EOF
Install the Kubernetes component packages using your preferred package manager :
[root@worker-3 ~]# dnf install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
Add node to existing cluster
We are all set up with your environment to add node to the existing Kubernetes Cluster. At this stage we have a single controller and worker node in our cluster:
[root@controller ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
controller.example.com Ready control-plane,master 40h v1.20.5
worker-2.example.com Ready <none> 39h v1.20.5
To add a new into the existing cluster requires your to execute
kubeadm join command which is provided at the kubeadm initialization stage.
But if you don't have that misplaced that command containing the token id then you can generate a new one on the controller node:
[root@controller ~]# kubeadm token create --print-join-command
kubeadm join 192.168.0.150:6443 --token 1642s5.ih5q6mdtf0pt9jey --discovery-token-ca-cert-hash sha256:d35bc841bd1ad7fd0223e506c8484bcafe9aa59427535b2709ed4b41201ce81b
So we can use this command on the worker node to join the Kubernetes cluster.
[root@worker-3 ~]# kubeadm join 192.168.0.150:6443 --token 1642s5.ih5q6mdtf0pt9jey --discovery-token-ca-cet-hash sha256:d35bc841bd1ad7fd0223e506c8484bcafe9aa59427535b2709ed4b41201ce81b
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 20.10.. Latest validated version: 19.03
[WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.sevice'
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yal'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
At this stage our kubelet service must be UP and running:
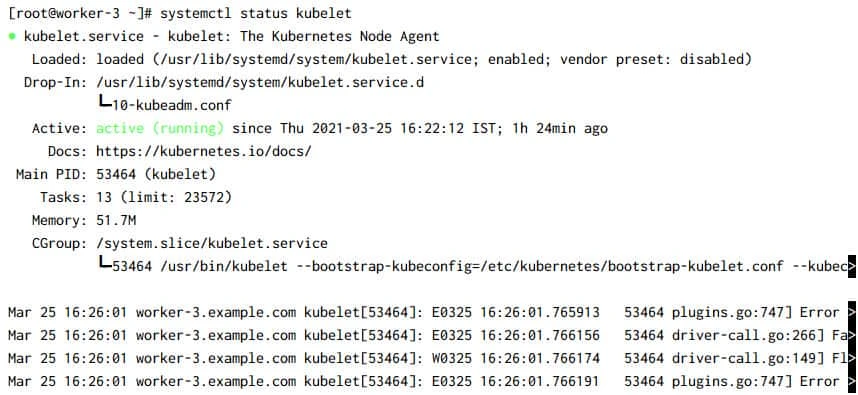
But we must enable the service to make sure it starts automatically on reboot:
[root@worker-3 ~]# systemctl enable kubelet
Now on your controller node you should see that new pods would be getting created for your network plugin, core-dns and kube-proxy for the new worker node:
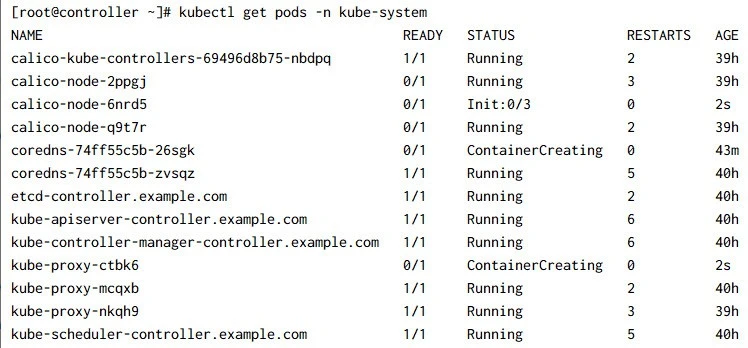
Since the pods are just getting created, most of them are at
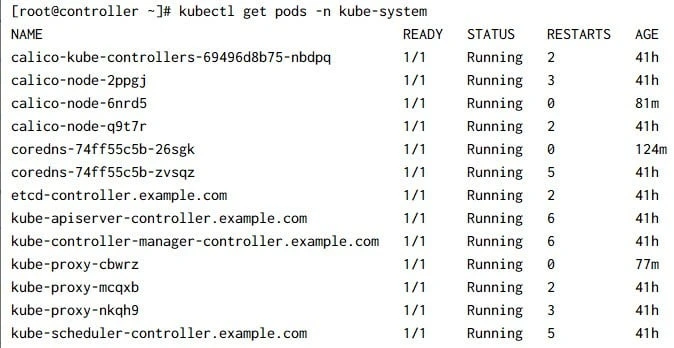
init-container stage or container creating stage. We will check the status again in
few minutes and they all should be running:
Check the list of nodes on your controller node now:

So our worker-3 node was successfully added to the existing Kubernetes
cluster.
Summary
In this tutorial I shared the steps to add a worker (previously known as
minnion) node to an existing Kubernetes cluster. You basically just need
to execute kubeadm join command to join the node to the cluster but
you must account for multiple pre-requisites. For example the list of
firewall ports hwich are required on your cluster. This list would vary
based on your networking plugin and their requirement. Additionally you
must also install container runtime before joining the cluster. So you
must follow all the pre-requisites before executing the kubeadm join
command.
