Releasing a Kubernetes Operator is not the same as deploying a stateless application. The release includes a controller image, CRDs, RBAC, webhooks, manifests or Helm charts, optional OLM bundles, and a rollback story that must respect Kubernetes API compatibility.
Most people searching for a Kubernetes Operator release pipeline want a production path from Git tag to running cluster:
Git tag -> image digest -> rendered manifests -> staging smoke test -> GitOps promotion -> production verification -> rollback plan
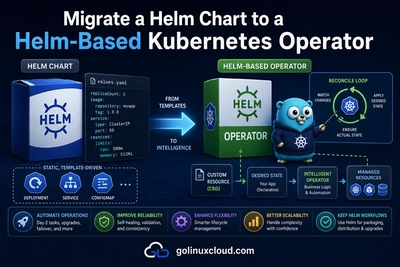
This guide turns that path into a practical release runbook. It builds on CI/CD with GitHub Actions, CRD version upgrades and conversion webhooks, Helm-based Operator vs Flux vs Argo CD, and Debugging Kubernetes Operators.
Operator release pipeline in 60 seconds
- Treat the Git tag, manager image digest, CRD YAML, install manifests, Helm chart, and optional OLM bundle as one tested release unit.
- Build and publish the manager image from a semver tag, but promote by immutable digest.
- Render install artifacts from the same commit that produced the image.
- Deploy to staging first, apply a sample CustomResource, and wait for meaningful status conditions.
- Promote to production by changing GitOps state, not by running one-off
kubectl set imagecommands. - Roll back the whole release tuple when CRDs, conversion webhooks, storage versions, or finalizers changed.
- Publish OLM bundles only after the image digest and release metadata are known.
Release flow: Git tag to cluster
A practical operator release flow looks like this:
| Step | Output | Gate before continuing |
|---|---|---|
| Create semver Git tag | v1.5.0 |
Tag points to reviewed release commit |
| Build manager image | repo/operator@sha256:... |
Image builds, scans, and optional signatures pass |
| Render install artifacts | Helm chart, Kustomize output, raw YAML | CRDs, RBAC, webhooks, and manager image digest match the tag |
| Validate API packaging | CRD validation, optional OLM bundle | Bundle and CRDs validate with pinned tooling |
| Deploy to staging | Running manager and CRDs | Rollout, health probes, metrics, and webhooks pass |
| Smoke-test sample CR | Real CustomResource reaches Ready |
Status, events, finalizers, and cleanup behave correctly |
| Promote via GitOps | Environment overlay or Helm values updated | Approval, diff, and policy checks pass |
| Verify production | Same digest running in cluster | Post-deploy smoke and dashboards are clean |
This structure matters because an operator release is an API release. A broken controller can usually be rolled back quickly. A broken CRD storage version or conversion webhook can trap existing resources in a much harder failure mode.
The release artifact contract
Every production release should answer one question: which exact artifacts were tested together?
| Artifact | Source | Version identity | Promotion rule |
|---|---|---|---|
| Manager image | Dockerfile and Go code | Image digest plus semver tag | Promote by digest, not by mutable tag |
| CRDs | config/crd/bases or chart templates |
Same Git tag as controller | Apply compatible CRDs before manager rollout |
| RBAC and webhooks | config/rbac, config/webhook, chart templates |
Same Git tag as controller | Validate permissions and webhook reachability |
| Helm chart | Chart directory or OCI chart | Chart version and appVersion |
Values should reference image digest or exact tag |
| Kustomize overlay | base plus environment overlays |
Git commit in environment repo | Promotion is a reviewed Git change |
| OLM bundle | bundle/, CSV, metadata, bundle image |
Bundle version and image digest | Validate before catalog publishing |
| Sample CR | Test fixture or release smoke test | Versioned with the release | Must reconcile to expected status |
If one artifact is owned by another team, document that ownership explicitly. For example, a platform team may own CRDs and webhooks while application teams own CustomResources. That can work, but only if the compatibility matrix and rollout order are clear.
Stage 1: Build, tag, and sign the manager image
Semver tags and immutable digests
Use semver tags such as v1.5.0 for releases. The tag should point to the commit that contains:
- controller source code,
- generated CRDs and RBAC,
- install manifests or chart changes,
- release notes or changelog entry,
- OLM bundle changes if the bundle is committed.
Build and push the manager image from that tag, then record the digest:
ghcr.io/example/database-operator@sha256:3d2f...Human-readable tags such as v1.5.0 are useful, but production promotion should use the digest. A mutable tag can be repushed; a digest identifies the exact image content.
Registry layout
Use a predictable registry layout:
ghcr.io/example/database-operator:v1.5.0
ghcr.io/example/database-operator:v1.5
ghcr.io/example/database-operator:sha-a1b2c3d
ghcr.io/example/database-operator@sha256:...Use per-commit tags for staging and semver tags for releases. Avoid latest in production manifests unless the cluster is intentionally disposable.
Signing, SBOM, and provenance
Add signing, SBOM, and provenance after the basic release path is reliable:
- sign the image digest with Cosign or Sigstore,
- publish an SBOM for the manager image,
- attach provenance from CI,
- verify signatures before promotion if your platform supports it.
These controls help consumers trust the digest, but they do not replace staging smoke tests.
Stage 2: Image to deployable manifests
Raw YAML, Helm, or Kustomize
Operator installs commonly use one of three packaging styles:
| Packaging | Best fit | Watch out for |
|---|---|---|
| Raw YAML | Small internal operators | Harder environment-specific overrides |
| Kustomize | Platform-owned overlays and GitOps | Image and namespace substitutions must stay visible in Git |
| Helm | Teams already standardizing on charts | CRD upgrade behavior and hook ordering need discipline |
Kubebuilder's make deploy is a useful development starting point. Production installs usually add resource requests, Pod security settings, topology spread, affinity, image pull secrets, and tighter RBAC. See RBAC minimum permissions before broadening permissions.
Helm chart values
For a Helm-packaged operator, keep image settings explicit:
image:
repository: ghcr.io/example/database-operator
tag: v1.5.0
digest: sha256:3d2f...If both tag and digest are supported, production templates should prefer the digest. The tag remains useful for humans reading values files.
Kustomize image substitution
For Kustomize, CI or the GitOps promotion job can update the image:
kustomize edit set image controller=ghcr.io/example/database-operator@sha256:3d2f...Commit that change to the environment repository instead of applying it directly to the cluster. The Git commit becomes the promotion audit trail.
Stage 3: Staging smoke test
Apply CRDs and webhooks before the manager
Order matters:
- Apply CRDs.
- Wait for CRDs to become established.
- Apply RBAC and service accounts.
- Ensure webhook service and certificates are ready if the operator uses webhooks.
- Apply webhook configurations.
- Roll out the manager Deployment.
- Apply the sample CustomResource.
Useful checks:
kubectl wait --for=condition=Established crd/widgets.example.com --timeout=120s
kubectl rollout status deployment/database-operator-controller-manager -n database-operator-system --timeout=120s
kubectl get validatingwebhookconfiguration
kubectl get mutatingwebhookconfigurationFor GitOps, encode ordering with Argo CD sync waves or Flux dependencies when CRDs, webhooks, manager, and sample CRs are managed as separate units.
Apply a sample CustomResource
Use the smallest real CustomResource from your docs:
apiVersion: database.example.com/v1
kind: Database
metadata:
name: smoke-test
spec:
size: smallThen assert a meaningful condition:
kubectl wait database smoke-test --for=condition=Ready --timeout=180sIf your CRD does not expose a Ready condition, poll the exact status field your users rely on:
kubectl get database smoke-test -o jsonpath='{.status.phase}'For condition design, see Kubernetes status and conditions.
Negative and cleanup checks
A release smoke test should prove more than "the Pod is running":
- Apply an invalid spec and confirm CRD validation or admission webhook rejects it.
- Delete the sample CR and confirm finalizers complete.
- Check operator logs for reconcile errors.
- Check Kubernetes events in the operator namespace.
- Confirm
/healthz,/readyz, and metrics endpoints behave as expected.
Related deep dives: health probes, Prometheus metrics, and finalizers.
Stage 4: GitOps promotion
CI produces the digest; CD consumes it
CI should export a single fact:
IMAGE_DIGEST=ghcr.io/example/database-operator@sha256:3d2f...CD or GitOps then consumes that digest by updating:
- a Helm values file,
- a Kustomize image patch,
- a raw manifest,
- an OLM bundle or catalog lane.
Avoid humans changing live Deployments without a matching Git change. If production drifts from Git, rollback and audit become much harder.
Argo CD and Flux ordering
Operator releases often need ordering beyond a normal app deployment.
For Argo CD, common ordering is:
| Sync wave | Resource |
|---|---|
-2 |
CRDs |
-1 |
namespace, service account, RBAC |
0 |
webhook service and certificates |
1 |
webhook configurations |
2 |
manager Deployment |
3 |
sample CR or smoke-test job |
For Flux, split CRDs, manager, and sample CRs into separate Kustomization resources when you need dependency ordering. Use dependsOn so the manager does not start before the API exists.
GitHub Environments and approvals
If GitHub Actions handles the promotion step, use GitHub Environments for production:
- required reviewers,
- environment-scoped secrets,
- deployment history,
- wait timers or change windows when needed.
Keep production registry credentials and cluster credentials out of pull request workflows.
Rollback matrix
The most common operator release mistake is assuming every rollback is only a Deployment rollback.
| Change in failed release | Is Deployment rollback enough? | Safer rollback |
|---|---|---|
| Controller-only logic bug | Usually yes | Roll back manager image digest |
| RBAC regression | No, if permissions changed | Restore RBAC and manager from prior tag |
| Added optional CRD field | Maybe | Confirm old controller ignores or tolerates field |
| Removed, renamed, or pruned CRD field | Usually no | Restore compatible CRD and controller tuple |
| Conversion webhook changed | Risky | Restore webhook service, config, CRD, and controller together |
| Storage version changed | No | Follow migration plan; do not assume simple rollback |
| Finalizer behavior changed | Usually no | Verify cleanup logic before rolling back blindly |
| Operand data changed | No | Repair data plane separately from operator rollback |
Treat the manager image, CRDs, webhooks, RBAC, Helm chart or Kustomize render, and OLM bundle as a tuple. Roll back one piece only when your compatibility matrix says it is safe.
CRD and controller versioning
Single release train
For most teams, one semver release should include:
- manager image,
- CRD YAML,
- RBAC and webhooks,
- Helm chart or Kustomize overlays,
- OLM bundle if used,
- changelog entry for breaking API changes.
This makes v1.5.0 mean "the exact API and controller we tested together."
Breaking vs non-breaking CRD changes
Non-breaking additions are usually easier:
- adding optional fields,
- adding enum values when clients tolerate them,
- adding status fields,
- adding printer columns.
Riskier changes need a migration plan:
- removing or renaming fields,
- changing validation in a way that rejects existing objects,
- changing storage versions,
- changing conversion webhooks,
- changing finalizer semantics.
For versioned APIs, follow the patterns in CRD version upgrades and conversion webhooks.
Safe rollout order
When conversion or webhook behavior changes, prefer this order:
- Ensure the conversion webhook service can answer for old and new versions.
- Apply compatible CRD changes.
- Wait for CRDs to become established.
- Roll out the new manager.
- Verify existing CRs can still be listed, watched, and reconciled.
- Only then promote to production.
The key question is not "did the Deployment roll out?" It is "can the Kubernetes API still serve every existing CustomResource correctly?"
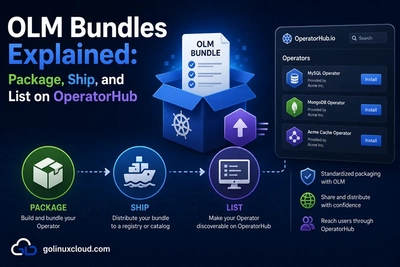
OLM bundle and catalog publishing
OLM adds another release lane. The manager image and CRDs still come first; the bundle packages them for OLM users.
A typical OLM release path:
- Build and push the manager image.
- Generate the bundle with the final image reference.
- Validate the bundle with a pinned
operator-sdkversion. - Build and push the bundle image.
- Test install or upgrade from the bundle.
- Update a catalog or file-based catalog.
- Publish to internal catalog or submit to OperatorHub if applicable.
Common commands:
make bundle IMG=ghcr.io/example/database-operator@sha256:3d2f...
operator-sdk bundle validate ./bundle
make bundle-build BUNDLE_IMG=ghcr.io/example/database-operator-bundle:v1.5.0
make bundle-push BUNDLE_IMG=ghcr.io/example/database-operator-bundle:v1.5.0
operator-sdk run bundle ghcr.io/example/database-operator-bundle:v1.5.0Keep bundle metadata in lockstep with the same image digest tested in staging. Bundle validation checks packaging; it does not replace runtime smoke tests.
For a deeper packaging guide, see OLM bundles & OperatorHub.
Pre-flight checks before production
Before promoting to production, answer these questions:
| Check | Why it matters |
|---|---|
| Does the production change point to the same digest tested in staging? | Prevents promoting a different binary |
| Are CRDs established and compatible with existing CRs? | Avoids API-serving failures |
| Are conversion webhooks reachable? | Prevents list/watch failures during version conversion |
| Did RBAC change? | Avoids runtime permission failures |
| Did the sample CR reach the expected condition? | Proves reconciliation, not only rollout |
| Did invalid input fail as expected? | Proves validation and admission behavior |
| Did finalizer cleanup complete? | Avoids stuck deletes during incidents |
| Are metrics, alerts, and logs clean? | Catches silent reconcile failures |
| Is rollback tested or documented? | Reduces pressure during incidents |
Checklist: gate, artifact, verification
| Gate | Artifact | Verify |
|---|---|---|
| Tag pushed | Semver Git tag | Tag points to release commit |
| Image build | Digest-pinned manager image | Pull in staging, optional signature/SBOM checks |
| Manifest render | Helm chart, Kustomize output, or raw YAML | CRDs, RBAC, webhooks, and image digest match |
| Bundle validation | OLM bundle and bundle image | operator-sdk bundle validate, install or upgrade test |
| Staging apply | Running manager and CRDs | Rollout, health, readiness, metrics, and logs |
| Smoke test | Sample CustomResource | Status condition, events, cleanup, invalid-spec rejection |
| Production promotion | GitOps overlay or Helm values | Same digest as staging, approval complete |
| Post-deploy verification | Production operator | Sample or canary CR, dashboards, alerts |
| Rollback rehearsal | Previous release tuple | Restore manager, CRDs, RBAC, webhooks, and bundle as needed |
Frequently Asked Questions
1. Should CRDs and the controller image share one Git tag?
For most teams, yes. A single semver tag should identify the manager image digest, CRD YAML, Helm chart or Kustomize render, and optional OLM bundle tested together. Splitting versions across artifacts is how clusters end up with controller and API skew.2. Can I roll back only the operator Deployment?
Only for controller-only bugs where CRDs, stored versions, webhooks, and operand data remain compatible. If the release changed CRDs, conversion webhooks, storage versions, or finalizer behavior, roll back the matched release tuple instead of only the Deployment.3. Where does GitOps fit in an operator release pipeline?
CI builds immutable artifacts and records the image digest. GitOps promotes those artifacts by updating Helm values, Kustomize images, or environment overlays, then Argo CD or Flux applies the staged change to clusters with review, ordering, and drift detection.4. Should I deploy CRDs separately from the operator manager?
It depends on ownership. Platform teams often manage CRDs separately so API changes are reviewed carefully. Smaller teams may ship CRDs and manager together. Either way, define ordering, compatibility, and rollback rules before production.5. How should I test an operator release before production?
Deploy the exact image digest and manifests to staging, wait for CRDs and webhooks, roll out the manager, apply a minimal CustomResource, verify status conditions, check metrics and events, test invalid input, and confirm finalizer cleanup.6. Where does OLM bundle publishing fit?
OLM publishing is an additional release lane after the image and manifests are known. Generate the bundle, validate it with a pinned operator-sdk version, build and push the bundle image, test install or upgrade, then update the catalog or OperatorHub submission.See also
- CI/CD with GitHub Actions
- CRD version upgrades and conversion webhooks
- Operator capability levels (OLM)
- Helm-based Operator vs Flux vs Argo CD
- Debugging Kubernetes Operators
- Configuration: flags, env, live reload
- Pause and resume patterns
- RBAC minimum permissions
Upstream references
- Kubernetes CRD versioning
- Operator SDK packaging
- Argo CD sync phases and waves
- GitHub deployment environments
- OLM
Bottom line: release a Kubernetes Operator as a tested artifact set, not as a lone Deployment. Build the image once, promote the digest through Git, keep CRDs and webhooks compatible, prove the release with a real CustomResource in staging, and roll back the whole tuple when API shape or stored data is involved.