
Related Searches: pandas merge, pandas concat, pd concat, pd merge, pd join, pandas append, dataframe append, pandas left join, pandas merge dataframes, merge two dataframes pandas, pandas merge on index, pandas join dataframes, append dataframe pandas, pandas concatenate, pandas append dataframe, dataframe merge, pandas dataframe append, pandas concat two dataframes, df merge, dataframe join, pandas merge on multiple columns, pandas join two dataframes, python merge, pd merge on multiple columns, join two dataframes pandas, pandas dataframe merge, combine two dataframes pandas, merge dataframe pandas, merge dataframes, python concat, dataframe concat, pandas dataframe join, concat dataframe pandas, pandas join vs merge, pandas merge multiple dataframes, concatenate two dataframes pandas, join dataframes pandas, pandas inner join, combine dataframes pandas
Introduction to pandas merge method
The dataframe and series in pandas are one of the powerful tools to explore and analyze data. One of the most important features of these data sets is their approach to combine separate datasets. With pandas, we can merge and concatenate different datasets together. In this tutorial, we will cover how we can merge and concatenate different datasets in pandas. we will learn about different techniques of merging inlcuding let merging, right merging, inner merging, and outer merging by working on practical examples. Moreover, we will also discuss pandas concat method as well which is another way of merging different datasets together.
Install Python Panda Module
By default pandas module may not be installed on your distro so you may get following error while trying to execute your python code using pandas module:
ModuleNotFoundError: No module named 'pandas'
So you must first install this module. One RHEL/Rocky
Linux/CentOS/Fedora distributions you can use dnf while for
Debia/Ubuntu you can use apt package manager:
# dnf -y install python3-pandas.x86_64
libqhull.so.7()(64bit) needed by
python3-matplotlib-3.0.3-3.el8.x86_64 error while installing
python3-panda. To overcome this we need to enable
"codeready-builder" repo using
subscription-manager repos --enable "codeready-builder-for-rhel-8-{ARCH}-rpms".
Here, replace {ARCH} with your architecture value
Alternatively you can install pip3 and then use pip to install panda module:
# dnf -y install python3-pip
Now you can use pip3 to install the panda module:
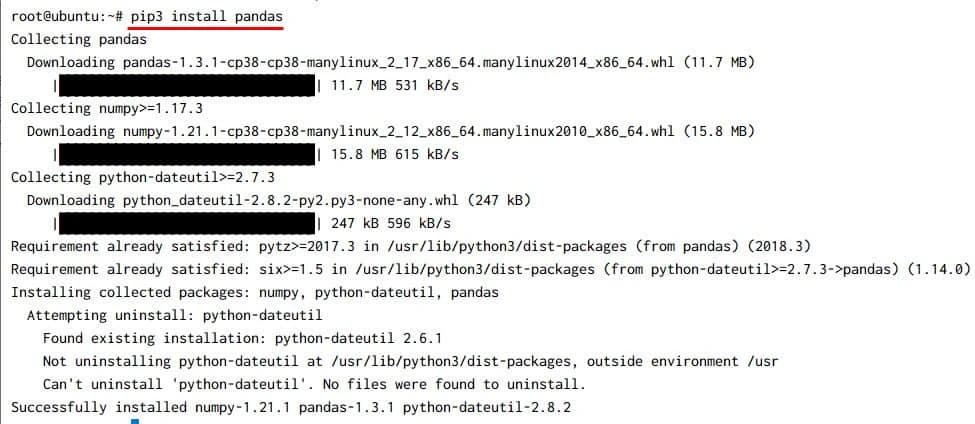
Getting start with pandas merge method
Pandas merge method allows us to create better datasets which helps us
to get efficient and accurate results when trying to analyze data.
merge() method is mostly used to combine data objects based on one or
more keys in a similar way to a relational database. In simple words
merge() is useful when we want to combine rows that share data. Let us
suppose that we have two csv files containing different data.
CSV_file_one.csv contains the following data:
student_id, Name, Gender
5, Erlan, Male
10, Alex, Male
15, soro, Female
20, Khan, Male
25, ateeq, Male
30, MD, Female
35, JK, Male
And CSV_file_two.csv contains the following data:
student_id, major
10, CS
20, MBBS
30, CS
40, CS
50, MBBS
In this section, we will cover different ways to combine the above data using the pandas merge method.
Example of left merging in pandas
Pandas left merge is mostly concerned about the data on the left side and add data from the right side if it has some of the dame ids. To apply left merging, we chop up the rows in the right dataframe and glue a piece of it onto the left dataframe. If something in the right dataframe does not match or doesn’t exist, pandas keep the same length of columns by adding NaN to fill the missing column. Here is a pictorial representation of left merging.

Pandas Left Merge
The simple syntax of left merging in pandas looks like this:
pd.merge(left=left_dataframe_name, right=right_dataframe_name, on=”ID”, how=”left”)
Let us take a practical example and see how left merging works in pandas. We will merge the two csv file given above.
# importing pandas
import pandas as pd
# reading the csv files
left_data = pd.<b>read_csv</b>("CSV_file_one.csv")
right_data = pd.<b>read_csv</b>("CSV_file_two.csv")
# Left merge on "student_ID" column
merged_data = pd.<b>merge</b>(left_data,right_data, on="student_id", how="left")
# printing
<b>print</b>(merged_data)
Output:
student_id Name Gender major
0 5 Erlan Male NaN
1 10 Alex Male CS
2 15 soro Female NaN
3 20 Khan Male MBBS
4 25 ateeq Male NaN
5 30 MD Female CS
6 35 JK Male NaN
You can see that the left merge takes all data from the left dataframe and takes only required data ( data that matches) with the left one.
Example of right merging in pandas
The right merge is very much similar to the left one with the difference that it mostly cares about the right side and adds the data from the left if it matches with the IDs. Here is the pictorial representation of right merging.
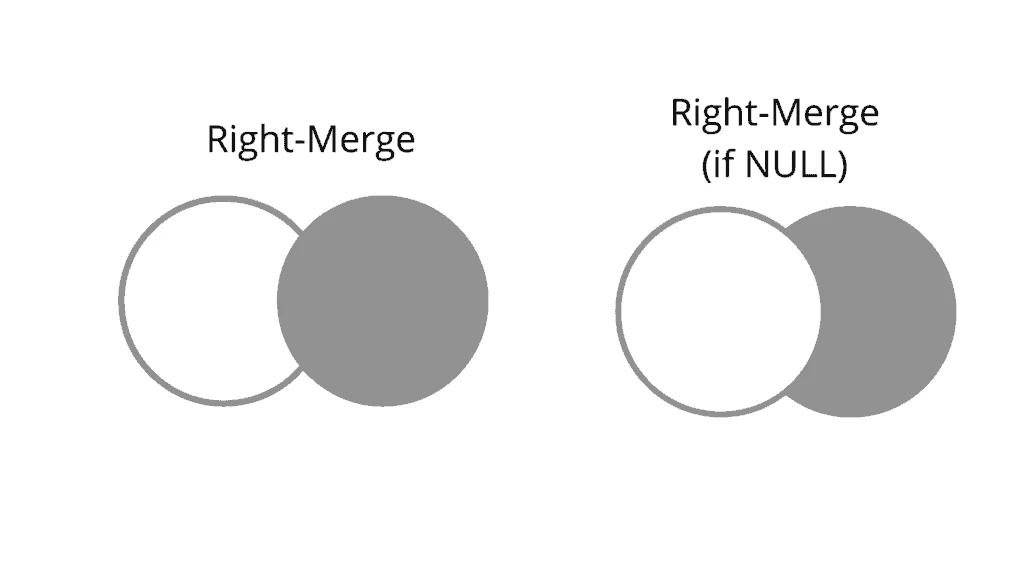
Pandas Right Merge
The simple syntax of right merging is very much similar to left merging.
pd.merge(left=left_dataframe_name, right=right_dataframe_name, on=”ID”, how=”right”)
Everything is the same, except we have to replace left with right. Now let us take example of right merging and merging data in the two csv files.
# importing pandas
import pandas as pd
# reading the csv files
left_data = pd.<b>read_csv</b>("CSV_file_one.csv")
right_data = pd.<b>read_csv</b>("CSV_file_two.csv")
# right merge on "student_ID" column
merged_data = pd.<b>merge</b>(left_data,right_data, on="student_id", how="right")
# printing
<b>print</b>(merged_data)Output:
student_id Name Gender major
0 10 Alex Male CS
1 20 Khan Male MBBS
2 30 MD Female CS
3 40 NaN NaN CS
4 50 NaN NaN MBBS
This time , the right merging methods take all the data from the right dataframe and take only required ( same id ones) from the left and merge them together.
Example of inner merging in pandas
Inner merging is very much similar to the intersection process. In this merging, pandas takes both data frames and merge the staff/data that matches. If an ID dont found in both data frames, pandas will not add that data, nor add NaN. Here is a pictorial representation of inner merging in pandas.
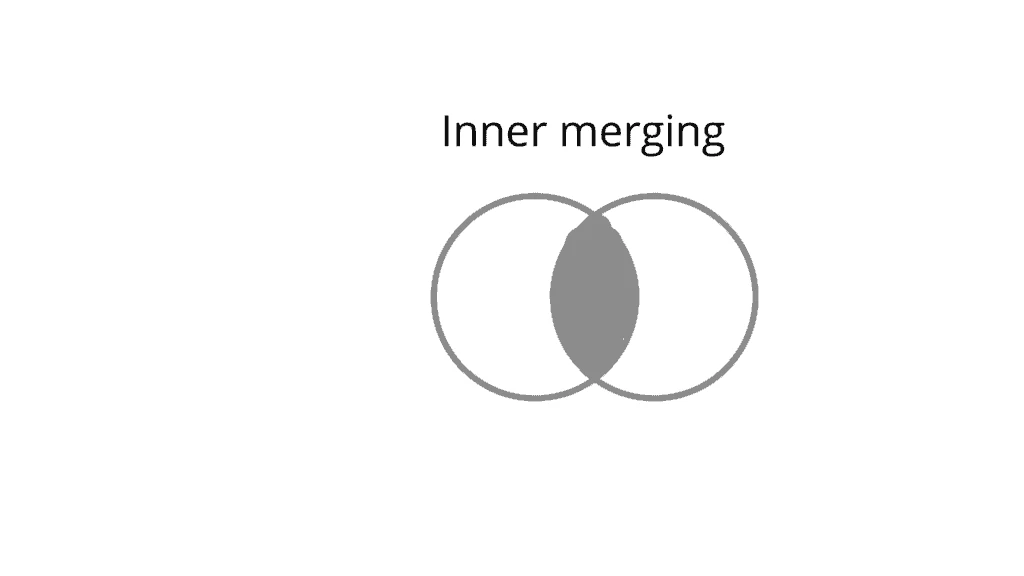
Pandas Inner Merge
Now let us look at the syntax of pandas inner merging.
pd.merge(left=left_dataframe_name, right=right_dataframe_name, on=”ID”, how=”inner”)
We just have to add inner to the code, the rest will be similar to right and left merging. See the example below:
# importing pandas
import pandas as pd
# reading the csv files
left_data = pd.<b>read_csv</b>("CSV_file_one.csv")
right_data = pd.<b>read_csv</b>("CSV_file_two.csv")
# inner merge on "student_ID" column
merged_data = pd.<b>merge</b>(left_data,right_data, on="student_id", how="inner")
# printing
<b>print</b>(merged_data)
Output:
student_id Name Gender major
0 10 Alex Male CS
1 20 Khan Male MBBS
2 30 MD Female CS
You can see the inner merging only takes and gives an output of data that is common(matches) in both data frames.
Example of outer merging in pandas
Outer merging in pandas is very much similar to union, which takes all the data from both data frames and adds NaN to fill the blanks, if any. See the pictorial representation of outer merging.
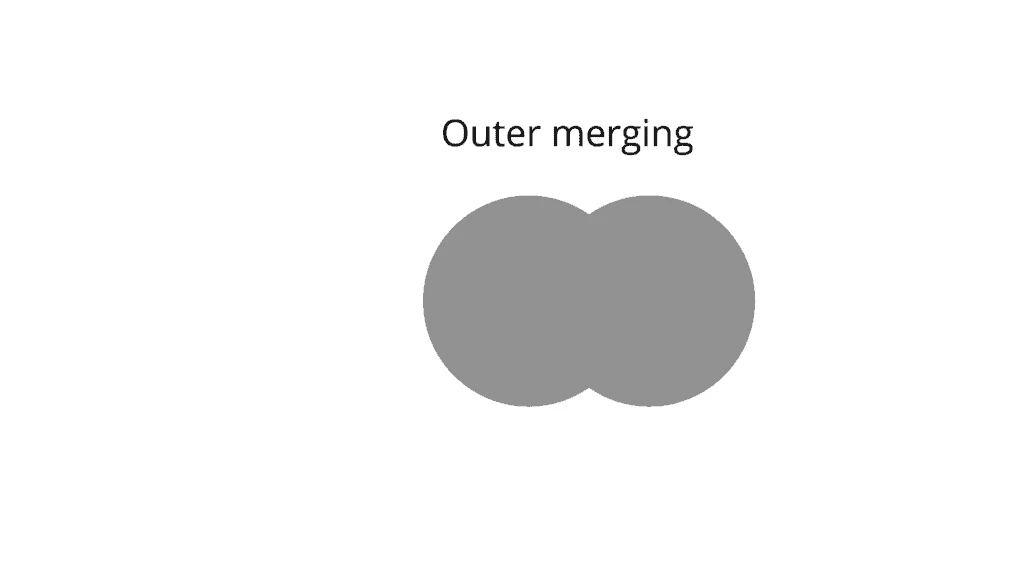
Pandas Outer Merge
The syntax of outer merging is very much similar to other ones. See the syntax below:
pd.merge(left=left_dataframe_name, right=right_dataframe_name, on=”ID”, how=”outer”)
Now let us take one example and merge the two data frames using the outer method.
# importing pandas
import pandas as pd
# reading the csv files
left_data = pd.<b>read_csv</b>("CSV_file_one.csv")
right_data = pd.<b>read_csv</b>("CSV_file_two.csv")
# outer merge on "student_ID" column
merged_data = pd.<b>merge</b>(left_data,right_data, on="student_id", how="outer")
# printing
<b>print</b>(merged_data)
Output:
student_id Name Gender major
0 5 Erlan Male NaN
1 10 Alex Male CS
2 15 soro Female NaN
3 20 Khan Male MBBS
4 25 ateeq Male NaN
5 30 MD Female CS
6 35 JK Male NaN
7 40 NaN NaN CS
8 50 NaN NaN MBBS
Notice that it takes all the data from both dataframes, and merges them together and adds NaNs to the blanks if any.
Example of merging on index in pandas
o far we have used the specified column in the “on” parameter in the merge. Instead of specifying columns, we can merge two dataframe based on indexes. The syntax of the merging on index pandas looks like this:
merged_data = pd.merge(left_data,right_data, left_index=True, right_index=True)
Now let us take the example of the two csv files and merge them based on indexing.
# importing pandas
import pandas as pd
# reading the csv files
left_data = pd.<b>read_csv</b>("CSV_file_one.csv")
right_data = pd.<b>read_csv</b>("CSV_file_two.csv")
# inner merging using indexing method
merged_data = pd.<b>merge</b>(left_data,right_data, how="inner", left_index=True, right_index=True)
# printing
<b>print</b>(merged_data)
Output:
student_id_x Name Gender student_id_y major
0 5 Erlan Male 10 CS
1 10 Alex Male 20 MBBS
2 15 soro Female 30 CS
3 20 Khan Male 40 CS
4 25 ateeq Male 50 MBBS
Pandas concat method to merge datasets
There is a little difference between pandas merging and concatenation methods. With the help of merging, we can get the result dataset in the form of rows from the parent datasets mixed together. Sometimes we might also lose rows that do not have matches in the dataset depending on the type of merging. While concatenation just stitches data together along an axis either in the row axis or column axis.
The simple syntax of pandas concatenation looks like this:
concated_data = pd.concat([dataframe_one, dataframe_two])
Now let us take an example of the two csv files and merge them together using pandas concat() method.
import pandas as pd
# reading the csv files
left_data = pd.<b>read_csv</b>("CSV_file_one.csv")
right_data = pd.<b>read_csv</b>("CSV_file_two.csv")
# pandas merging using concat() method
merged_data = pd.<b>concat</b>([left_data, right_data])
# printing
<b>print</b>(merged_data)
Output:
0 5 Erlan Male NaN
1 10 Alex Male NaN
2 15 soro Female NaN
3 20 Khan Male NaN
4 25 ateeq Male NaN
5 30 MD Female NaN
6 35 JK Male NaN
0 10 NaN NaN CS
1 20 NaN NaN MBBS
2 30 NaN NaN CS
3 40 NaN NaN CS
4 50 NaN NaN MBBS
Notice that it takes all the rows (data) and columns along with the indexing number, adds them together and puts NaN in the missing data.
By default, concatenation is a set of a union, where all data is merged
together. The concat() method can take some optional parameters as
well. The following list gives us information about some of those
parameters.
axis: help us to specify the axis position. By default the value is 0, which concatenates along the index while 1 concatenates along columns.objs: this takes any sequence of series or dataframe objects to be concatenated.join: by default the value is outer, we can specify and make it inner merging as well.key: this parameter allows us to construct a hierarchical index.
Now let us take the same example of two csv files and concatenate them by explicitly mentioning the method(inner). See the example below:
# importing pandas
import pandas as pd
# reading the csv files
left_data = pd.<b>read_csv</b>("CSV_file_one.csv")
right_data = pd.<b>read_csv</b>("CSV_file_two.csv")
# pandas merging using concat() method
merged_data = pd.<b>concat</b>([left_data, right_data], join="inner")
# printing
<b>print</b>(merged_data)
Output:
student_id
0 5
1 10
2 15
3 20
4 25
5 30
6 35
0 10
1 20
2 30
3 40
4 50
This prints all the rows with only one column (the student_id) because by default the axis 0 which means row. See the example below which concatenates column wise.
# importing pandas
import pandas as pd
# reading the csv files
left_data = pd.<b>read_csv</b>("CSV_file_one.csv")
right_data = pd.<b>read_csv</b>("CSV_file_two.csv")
# pandas merging using concat() method
merged_data = pd.<b>concat</b>([left_data, right_data], join="inner", axis=1)
# printing
<b>print</b>(merged_data)
Output:
student_id Name Gender student_id major
0 5 Erlan Male 10 CS
1 10 Alex Male 20 MBBS
2 15 soro Female 30 CS
3 20 Khan Male 40 CS
4 25 ateeq Male 50 MBBS
Pandas join method to merge dataframe
We know that merge() is a modular function while join() is an object
function which lives on a dataframe that helps us to specify only one
dataframe which will join. Syntax is similar to the panda merge method.
See the syntax below:
dataframe1_name.join( dataframe2_name, optional_parameters)
Now let us take a practical example of the two csv files and merged them using join method.
# importing pandas
import pandas as pd
# reading the csv files
left_data = pd.<b>read_csv</b>("CSV_file_one.csv")
right_data = pd.<b>read_csv</b>("CSV_file_two.csv")
# pandas merging using join method
merged_data = left_data.<b>join</b>(right_data)
# printing
<b>print</b>(merged_data)
Output:
student_id Name Gender student_id major
0 5 Erlan Male 10.0 CS
1 10 Alex Male 20.0 MBBS
2 15 soro Female 30.0 CS
3 20 Khan Male 40.0 CS
4 25 ateeq Male 50.0 MBBS
5 30 MD Female NaN NaN
6 35 JK Male NaN NaN
You can see that the join method merges two dataframes and adds NaN to the black areas.
Here is a description of the parameters that join method can take:
other: this is a required parameter which specifies the name of another dataframe. We can also specify a list of dataframe as well.on: Optional parameter which specifies an optional column or index name for the left datframe. By default the value is set to Nonehow: as name suggests, is the same as how the parameter in merge works with a difference that this time it is indexed-based.- l
suffixandrsuffix: similar to the suffixes in merge one. It specifies a suffix to add to any overlapping columns.
As you are now familiar with different parameters that we can use with the join method. Let us take the same example and perform an inner join using the join method.
# importing pandas
import pandas as pd
# reading the csv files
left_data = pd.<b>read_csv</b>("CSV_file_one.csv")
right_data = pd.<b>read_csv</b>("CSV_file_two.csv")
# pandas merging using join method
merged_data = left_data.<b>join</b>(right_data, how="inner")
# printing
<b>print</b>(merged_data)
Output:
student_id Name Gender student_id major
0 5 Erlan Male 10 CS
1 10 Alex Male 20 MBBS
2 15 soro Female 30 CS
3 20 Khan Male 40 CS
4 25 ateeq Male 50 MBBS
Pandas append method to merge dataframes
The append method in pandas is used to append rows of one dataframe to the end of a given dataframe, and return a new dataframe object. Columns which are not in the original dataframe are added as new columns and NaN is added in new cells. Here is a simple syntax of append method in pandas.
dataframe1_name.append(dataframe2_name)
Now let us take the practical example of the two csv files and append one file to the end of another.
# importing pandas
import pandas as pd
# reading the csv files
left_data = pd.<b>read_csv</b>("CSV_file_one.csv")
right_data = pd.<b>read_csv</b>("CSV_file_two.csv")
# pandas merging using join method
merged_data = left_data.<b>append</b>(right_data)
# printing
<b>print</b>(merged_data)
Output:
student_id Name Gender student_id major
0 5.0 Erlan Male NaN NaN
1 10.0 Alex Male NaN NaN
2 15.0 soro Female NaN NaN
3 20.0 Khan Male NaN NaN
4 25.0 ateeq Male NaN NaN
5 30.0 MD Female NaN NaN
6 35.0 JK Male NaN NaN
0 NaN NaN NaN 10.0 CS
1 NaN NaN NaN 20.0 MBBS
2 NaN NaN NaN 30.0 CS
3 NaN NaN NaN 40.0 CS
4 NaN NaN NaN 50.0 MBBS
Notice that it added new columns which were not in the previous one ( major, student_id) and added NaN to the cells.
Summary
Pandas merge and pandas concat methods allow us to create better datasets for analyzing and filtering data. There are different methods of merging available in pandas for example left merging, right merging, inner merging, and outer merging. In this tutorial, we learned about all these pandas merging methods along with examples. We also covered the pandas concat method to merge data by working on practical examples. In a nutshell, we cover everything that you need to know in order to understand and use pandas merge method in practical problems.
Further Reading
pandas merge method documentation
pandas concat method documentation
pandas merge method
