
What is a disruption in plain English?
In simple words, a break or interruption in the normal course or continuation of some activity or process is called disruption.
It comes into the picture when a pod needs to be killed and respawned. Disruptions are inevitable, and they would need to be handled delicately, otherwise, we will have an outage.
What is a PodDisruptionBudget (pdb) in Kubernetes?
PodDisruptionBudgetensures a certain number or percentage of Pods will
not voluntarily be evicted from a node at any one point in
time.Voluntaryhere means an eviction that can be delayed for a
particular time—for example, when it is triggered by draining a node for
maintenance or upgrade (kubectl drain), or a cluster scaling down,
rather than a node becoming unhealthy, which cannot be predicted or
controlled.
- A pod disruption budget (PDB) is an indicator of the number of disruptions that can be tolerated at a given time for a class of pods (a budget of faults).
- Whenever a disruption to the pods in service is calculated to cause the service to drop below the budget, the operation is paused until it can maintain the budget.
- The word budget is used as in error budget, in the sense that any voluntary disruption within this budget should be acceptable.
APodDisruptionBudgethas three fields:
- A label selector
.spec.selectorspecifies the set of pods to which it applies. This field is required. .spec.minAvailablewhich is a description of the number of pods from that set that must still be available after the eviction, even in the absence of the evicted pod.minAvailablecan be either an absolute number or a percentage..spec.maxUnavailable(available in Kubernetes 1.7 and higher) which is a description of the number of pods from that set that can be unavailable after the eviction. It can be either an absolute number or a percentage.
Minimum available (minAvailable)
In the following example, we set
a<span class="orm-highlight">PodDisruptionBudget</span> to handle a
minimum available to 2 for app: zookeeper.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: zookeeperIn this example, the PodDisruptionBudget specifies that for the zookeeper app there must always be 2 replica pods available at any given time. In this scenario, an eviction can evict as many pods as it wants, as long as two are available.
Maximum Unavailable (maxUnavailable)
Starting with Kubernetes 1.7, the PodDisruptionBudget resource also
supports the maxUnavailable field, which you can use instead of
min-Available . In the next example, we set a PodDisruptionBudget to
handle a maximum unavailable to 2 replicas for the zookeeper app:
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
maxUnavailable: 2
selector:
matchLabels:
app: zookeeperIn this example, the PodDisruptionBudget specifies that no more
than 2 replica pods can be unavailable at any given time. In this
scenario, an eviction can evict a maximum of 2 of pods during a
voluntary disruption.
When specifying a pod disruption budget as a percentage, it might not
correlate to a specific number of pods. For example, if your application
has seven pods and you specify maxAvailable to 50%, it’s not clear
whether that is three or four pods. In this case, Kubernetes rounds up
to the closest integer, so the maxAvailable would be four pods.
You cannot specify both maxUnavailable and minAvailable fields, and
PodDisruptionBudget typically applies only to Pods managed by a
controller
You can create or update the PDB object using kubectl.
$ kubectl apply -f mypdb.yaml
Use kubectl to check that your PDB is created.Assuming you don't
actually have pods matchingapp: zookeeperin your namespace, then
you'll see something like this:
$ kubectl get poddisruptionbudgets
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
zk-pdb 2 N/A 0 7s
If there are matching pods (say, 3), then you would see something like this:
$ kubectl get poddisruptionbudgets
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
zk-pdb 2 N/A 1 7s
The non-zero value forALLOWED DISRUPTIONSmeans that the disruption controller has seen the pods, counted the matching pods, and updated the status of the PDB.
You can get more information about the status of a PDB with this command:
$ kubectl get poddisruptionbudgets zk-pdb -o yaml
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
annotations:
…
creationTimestamp: "2020-03-04T04:22:56Z"
generation: 1
name: zk-pdb
…
status:
currentHealthy: 3
desiredHealthy: 2
disruptionsAllowed: 1
expectedPods: 3
observedGeneration: 1Exploring PodDistributionBudget in Action
For example, if we wanted to create a pod disruption budget where we always want at least 1 Nginx pod to be available for our example deployment, we will apply the following config:
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: nginx-pdb
spec:
minAvailable: 1
selector:
matchLabels:
app: nginxThis indicates to Kubernetes that we want at least 1 pod that matches
the labelapp: nginxto be available at any given time. Using
this, we can induce Kubernetes to wait for the pod in one drain request
to be replaced before evicting the pods in a second drain request.
For the sake of simplicity, we will ignore any presto hooks, readiness probes, and service requests in this example. We will also assume that we want to do a one-to-one replacement of the cluster nodes. This means that we will expand our cluster by doubling the number of nodes, with the new nodes running the new image.
So starting with our original cluster of two nodes:
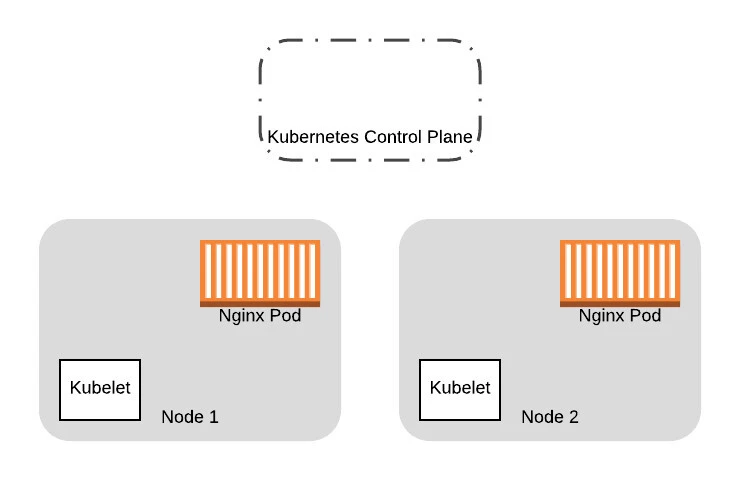
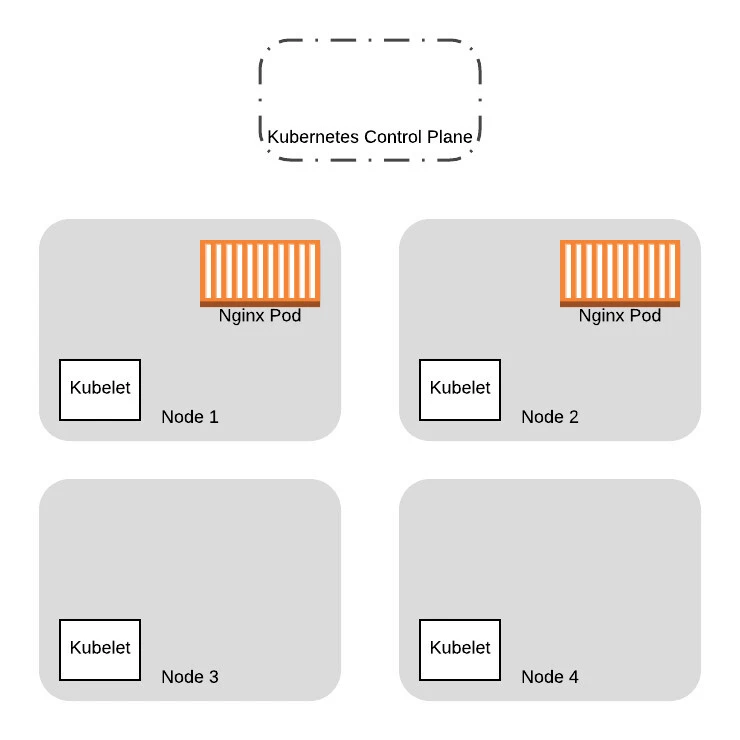
We provision two additional nodes here running the new VM images. We will eventually replace all the Pods on the old nodes with the new ones:
To replace the Pods, we will first need to drain the old nodes. In this example, let’s see what happens when we concurrently issue the drain command to both nodes that were running our Nginx pods. The drain request will be issued in two threads (in practice, this is just two terminal tabs), each managing the drain sequence for one of the nodes.
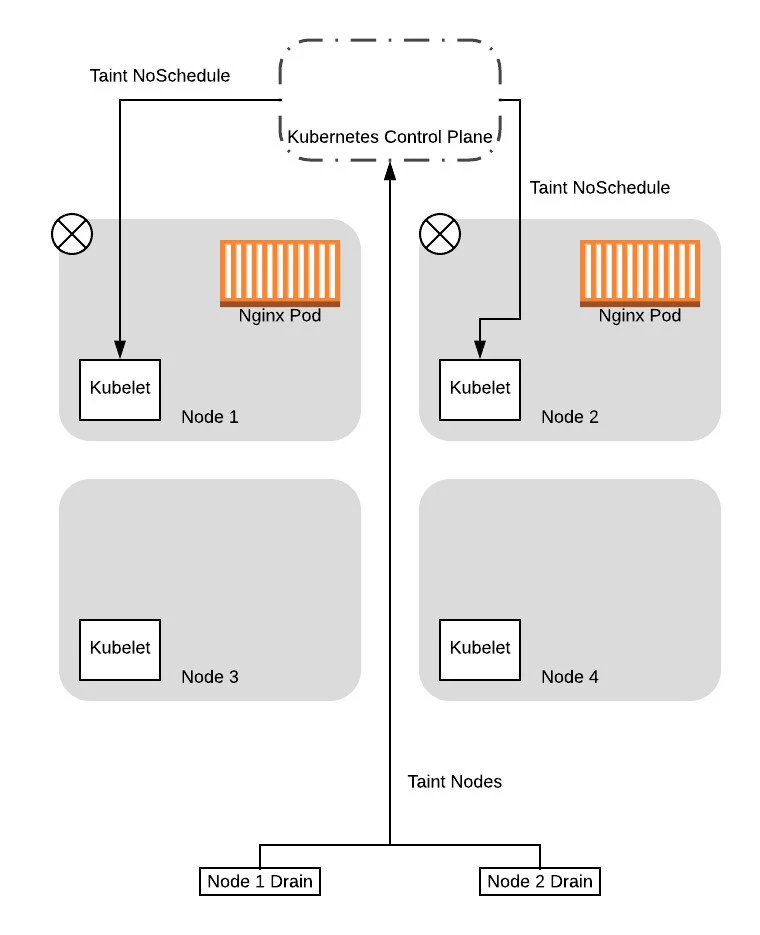
Note that up to this point we were simplifying the examples by assuming that the drain command immediately issues an eviction request. In reality, the drain operation involves tainting nodes (with theNoScheduletaint) first so that new pods won’t be scheduled on the nodes. For this example, we will look at the two phases individually.
So to start, the two threads managing the drain sequence will taint the nodes so that new pods won’t be scheduled:
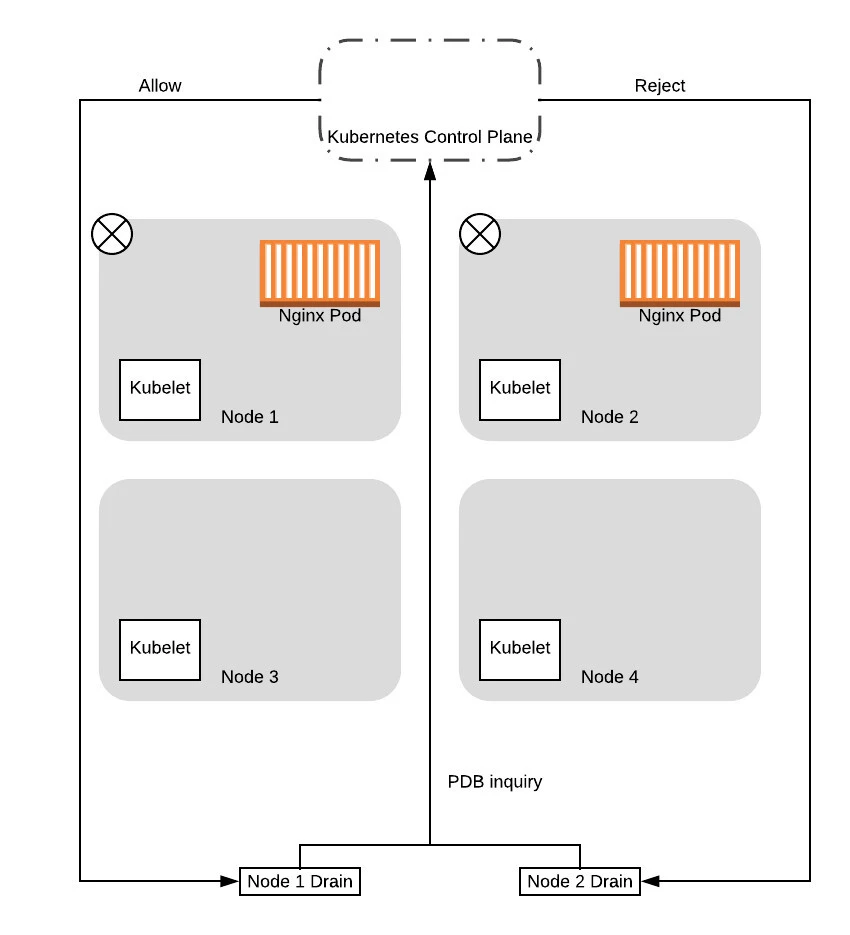
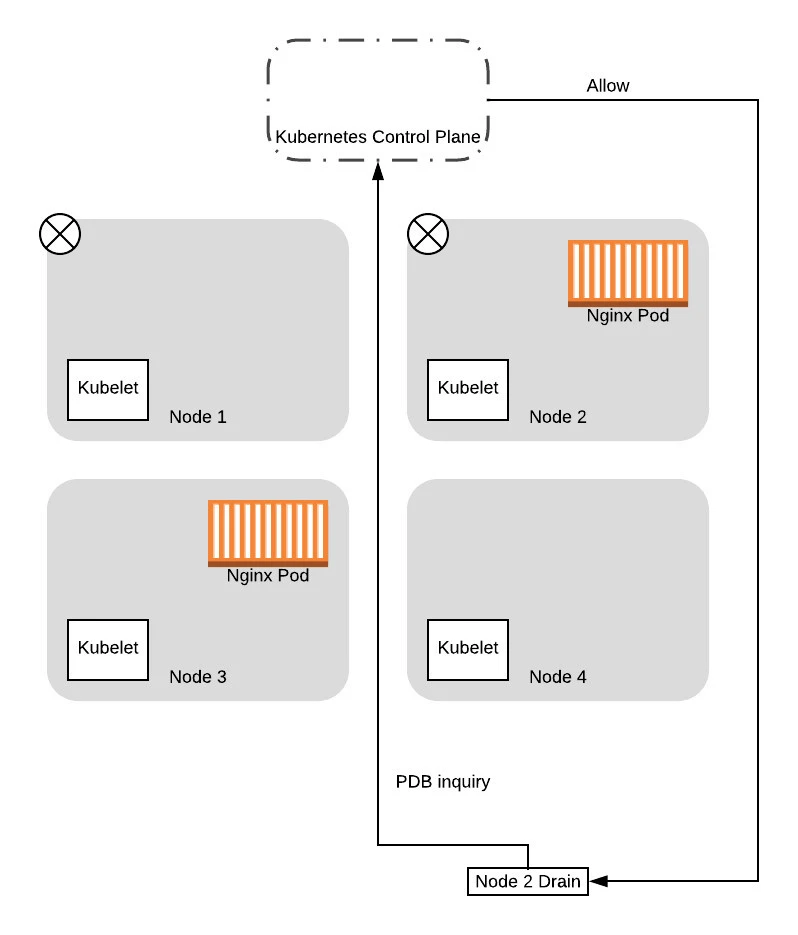
After the tainting completes, the drain threads will start evicting the pods on the nodes. As part of this, the drain thread will query the control plane to see if the eviction will cause the service to drop below the configured Pod Disruption Budget (PDB).
Note that the control plane will serialize the requests, processing one PDB inquiry at a time. As such, in this case, the control plane will respond to one of the requests with a success, while failing the other. This is because the first request is based on 2 pods being available. Allowing this request would drop the number of pods available to 1, which means the budget is maintained. When it allows the request to proceed, one of the pods is then evicted, thereby becoming unavailable. At that point, when the second request is processed, the control plane will reject it because allowing that request would drop the number of available pods down to 0, dropping below our configured budget.
Given that, in this example, we will assume that node 1 was the one that got the successful response. In this case, the drain thread for node 1 will proceed to evict the pods, while the drain thread for node 2 will wait and try again later:
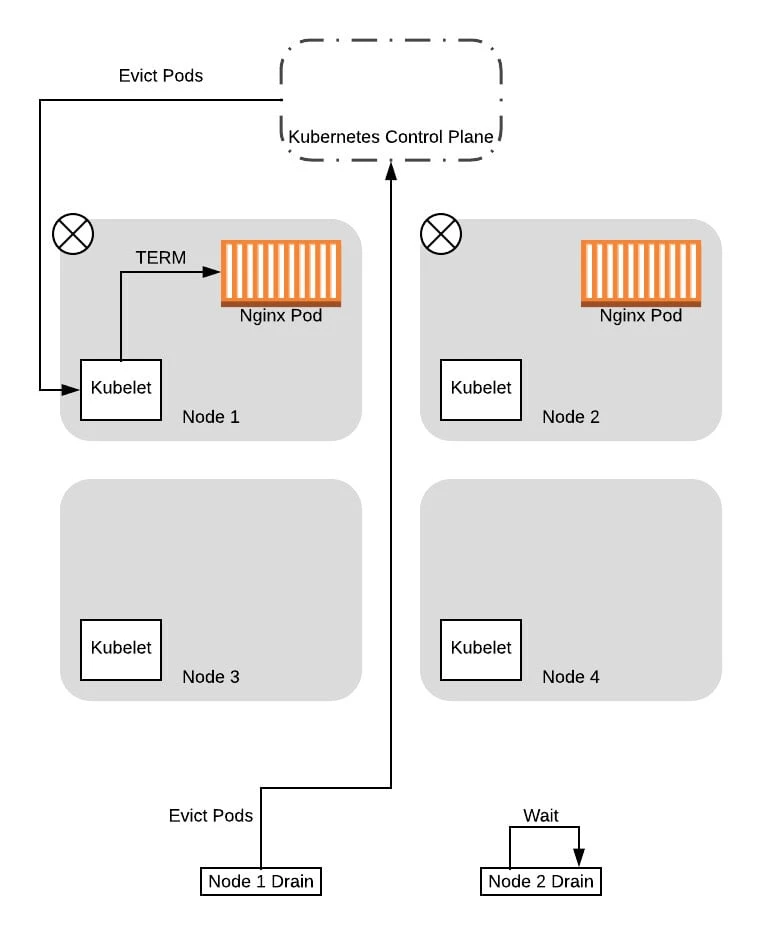
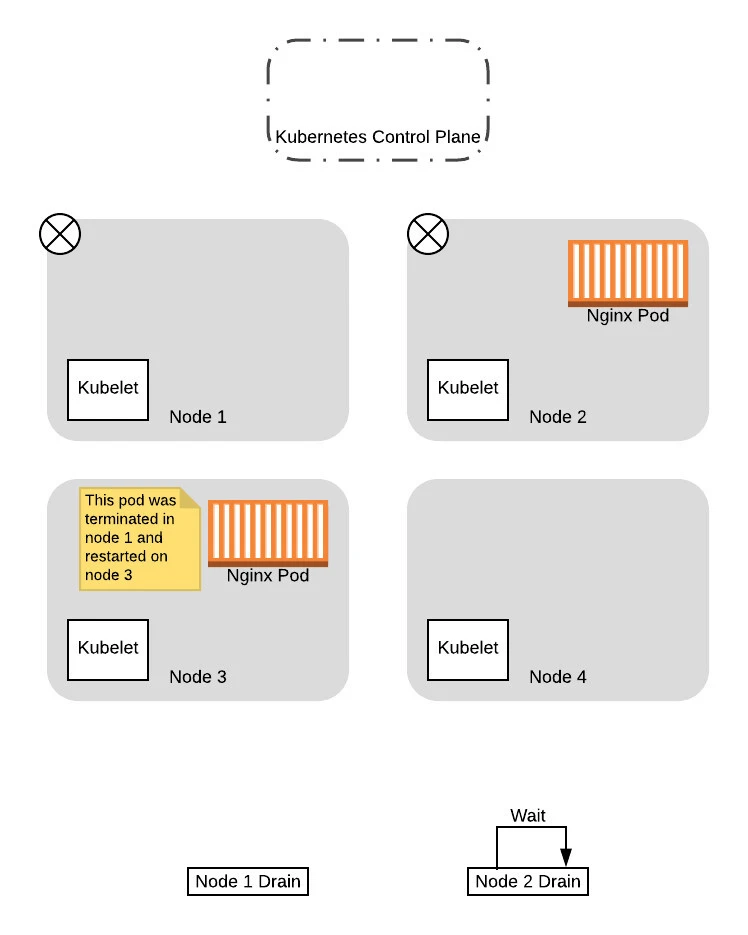
At this point, now that the pod has been replaced successfully on the new node and the original node is drained, the thread for draining node 1 completes.
From this point on, when the drain thread for node 2 tries again to query the control plane about the PDB again, it will succeed. This is because there is a pod running that is not in consideration for eviction, so allowing the drain thread for node 2 to progress further won’t drop the number of available pods down below the budget. So the thread progresses to evict the pods and eventually completes the eviction process:
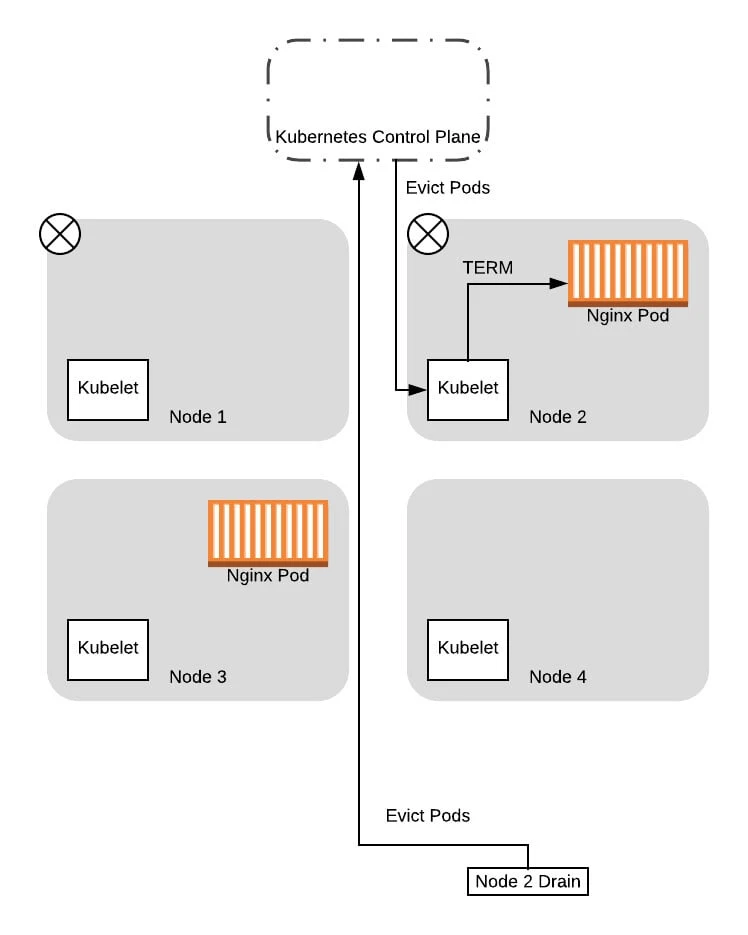
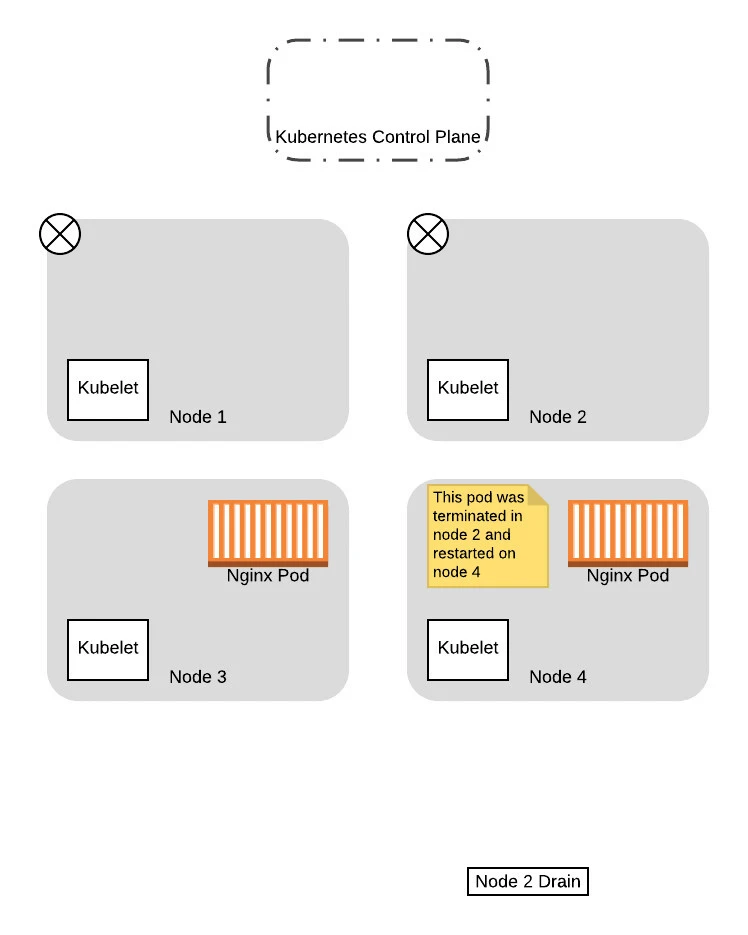
With that, we have successfully migrated both pods to the new nodes, without ever having a situation where we have no pods to service the application. Moreover, we did not need to have any coordination logic between the two threads, as Kubernetes handled all that for us based on the config we provided!
Summary
PodDisruptionBudget is quite important for Resource Management. Granted, it is not absolutely mandatory as discussed before - if the cluster you manage has enough spare capacity in CPU/memory, the rollout can uneventfully finish without impacting the workload more often than not. Nevertheless, it is still a recommended approach to have control in the event of voluntary disruption.
Reference
For more details: Kubernetes website
