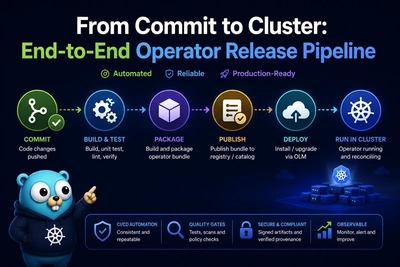
Every Kubernetes Operator built with Kubebuilder or Operator SDK eventually comes down to one function: Reconcile. The behavior users feel in production—fast recovery, slow storms, or “stuck for an hour”—is often decided by how you combine ctrl.Result, Requeue, RequeueAfter, and the error return path.
This guide is the focused companion to the full pipeline story in the Kubernetes reconcile loop explained and the machinery underneath it in controller-runtime architecture. Read those for informers, caches, and workqueues; read this page when you are choosing what to return from Reconcile and debugging retry behavior.
The Reconcile contract in one minute
In controller-runtime, reconciliation implements:
func (r *MyReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error)The framework hands you a key (req.NamespacedName). It does not hand you a guaranteed-up-to-date object; you Get, observe, mutate, update status, then return.
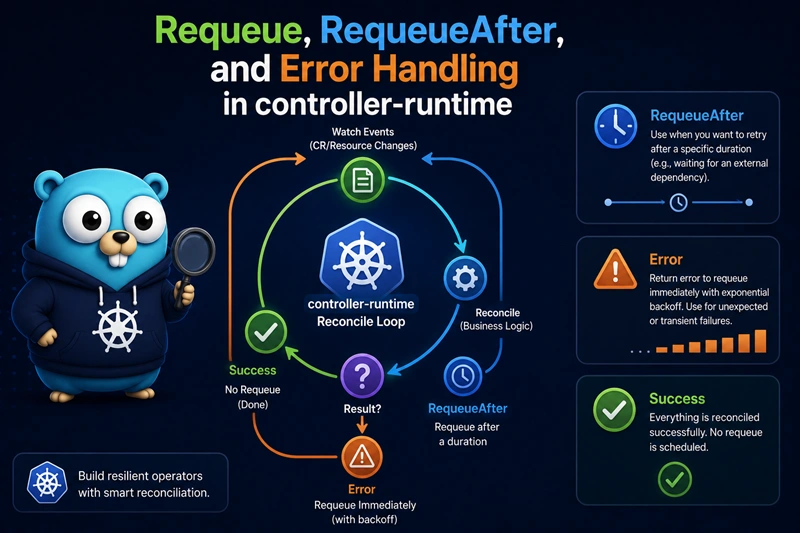
ctrl.Result vs error: two different signals
ctrl.Resultanswers: “Assuming my logic ran as intended, when should this key be processed again?”erroranswers: “Something went wrong; please apply the failure retry policy.”
Those channels are independent in the type system but interact in operator behavior: a non-nil error always implies a requeue with exponential backoff, regardless of what you put in Result.
What the workqueue does with each combination
Under the hood, controller-runtime uses client-go’s rate limiting workqueue (see controller-runtime architecture). In practice:
| Return | Typical effect |
|---|---|
Result{}, nil |
Success. Backoff counter resets. The key is forgotten until a new watch event, resync, or an explicit Requeue / RequeueAfter you returned earlier fires. |
Result{Requeue: true}, nil |
Immediate requeue; still subject to the rate limiter for that key. |
Result{RequeueAfter: d}, nil |
Schedule the same key after d; bypasses the failure backoff timer (still not a license to spin hot). |
Result{}, err |
Failure path: log, increment backoff, re-add the key with exponential delay. |
Exact tuning (QPS, bucket rate limiter defaults) can shift between versions; treat the table as the mental model operators rely on.
Decision guide: which return should I use?
Summary table (scenario → return → what happens next)
| Scenario | Recommended return | Why |
|---|---|---|
| Object converged; nothing to do until the world changes | ctrl.Result{}, nil |
Lets watches and resync drive the next wake-up. |
| Healthy “not ready yet” (external API, certificate pending) | ctrl.Result{RequeueAfter: d}, nil |
You pick d; you avoid poisoning backoff with benign “errors”. |
| Need another pass quickly after a benign local decision | ctrl.Result{Requeue: true}, nil |
Immediate requeue under rate limiting—use sparingly. |
| Unexpected failure (network, RBAC, bug you cannot classify) | ctrl.Result{}, err |
Lets the workqueue backoff protect the apiserver. |
| User error that will never succeed without a spec edit | ctrl.Result{}, nil after status update (or reconcile.TerminalError) |
Stops infinite retry noise; see terminal errors. |
When not to use return err for “try again later”
If the cluster is fine but time must pass, prefer:
return ctrl.Result{RequeueAfter: 30 * time.Second}, nilinstead of:
return ctrl.Result{}, fmt.Errorf("still waiting")Errors should mean “this reconcile attempt failed,” not “come back in thirty seconds.” Misusing error inflates backoff, hides intent in logs, and makes SLO dashboards look like your Operator is failing when it is actually waiting.
Steady state: finish without forcing another reconcile
return ctrl.Result{}, nil
This is the happy path once .spec (and any derived child resources you own) match your intent and you have written status if needed. Returning nil error tells the framework: this attempt succeeded.
Operators should reach this state often. If you never return Result{}, nil, you may be over-requeueing or leaking work.
When the next run happens anyway (watches, resync)
Even after Result{}, nil, Reconcile will run again when:
- A watch delivers an event for the primary object or something you
Owns/Watches. - The shared informer resyncs (periodic full relist behavior—depends on configuration and predicates).
That is why reconciliation must be idempotent: the same key can arrive many times without you asking. See watches, events, and predicates to avoid reconcile storms from status-only churn.
Success with an explicit follow-up
Requeue: true (immediate requeue and rate limiting)
Requeue: true means “enqueue again as soon as the workqueue allows,” not “run again in the same goroutine.” It still passes through the rate limiter, so it is safer than a raw loop but can still amplify load if combined with noisy watches.
Use it when you deliberately need another pass soon, but not on a fixed clock— for example right after a write where you expect a child object to appear quickly and you want to re-read before declaring phase complete.
RequeueAfter (scheduled requeue and typical use cases)
RequeueAfter is the idiomatic timer for polling and backoff you control:
- Waiting on an external SaaS API quota window.
- Rechecking a TLS certificate that will not flip to Ready until the CA responds.
- Throttling noisy checks while still faster than global error backoff.
Because it bypasses failure backoff, pair it with sane durations and with predicates so unrelated object updates do not drown the queue.
Choosing a delay (jitter, ceilings, avoiding thundering herds)
Production tips:
- Add small jitter when many objects might line up on the same delay.
- Cap extremely large
RequeueAftervalues with domain sense (a daily check does not need sub-second precision). - If every replica of your controller hits the same external system on the same cadence, stagger via hashing the object UID into a few-second spread.
Failure path: return ctrl.Result{}, err
Exponential backoff and logging
When you return a non-nil error, controller-runtime logs the error and requeues with exponential backoff (per-key). That protects the apiserver when etcd is slow, RBAC is wrong, or a webhook is temporarily down.
This path is ideal for transient infrastructure problems: timeouts, 429 Too Many Requests, unexpected 500 from aggregated APIs, and similar.
Transient failures that belong on the error path
Good error candidates:
- Network blips talking to the Kubernetes API.
- Errors you truly cannot classify without another full attempt.
- Temporary admission webhook outages affecting creates/updates.
Bad error candidates:
- “Replicas still not ready” when that is normal rollout progress—use
RequeueAfterand/or rely onOwnson Pods. - Validation failures the user must fix in the spec—treat as terminal; see below.
Picking one signal when Result and error both feel tempting
If you return both a non-nil error and a RequeueAfter, the failure path wins: the error handling path is authoritative. Do not rely on combining them; choose either a controlled timer (RequeueAfter, nil) or an error for backoff.
Terminal errors: stop infinite retry on bad input
Status, events, and returning success with no requeue
When .spec is invalid in a way no amount of retry will fix (bad image name format, contradictory fields), the operator should:
- Write a condition or phase on the status subresource.
- Emit a Kubernetes event if your pattern includes user-visible hints.
- Return
ctrl.Result{}, nil.
That pattern stops the workqueue from hammering the same broken object forever and matches how mature projects communicate “user must change the CR.”
reconcile.TerminalError (version note)
On supported controller-runtime versions, reconcile.TerminalError(err) wraps an error so the manager logs it once and does not apply the usual failure requeue behavior—useful when you still want rich error context in logs but not infinite backoff loops.
Check your go.mod version and the upstream sigs.k8s.io/controller-runtime/pkg/reconcile documentation before relying on this API; behavior evolved across minor releases.
Validation failures vs reconciliation failures
- Validation failure (spec does not satisfy CRD OpenAPI, or your own semantic checks): user action required → terminal pattern.
- Reconciliation failure (cannot reach apiserver): infrastructure →
return err.
Admission webhooks blur the line; see mutating and validating webhooks for how denied requests surface.
Special API errors every reconciler should handle
NotFound and client.IgnoreNotFound
At the top of Reconcile, after Get:
if err := r.Get(ctx, req.NamespacedName, &obj); err != nil {
return ctrl.Result{}, client.IgnoreNotFound(err)
}IgnoreNotFound maps NotFound to nil, which becomes Result{}, nil—the object is gone, so the desired state for that key is vacuously satisfied from the controller’s point of view. This pairs naturally with finalizers when you still have cleanup work before the object disappears; once the object is truly gone, NotFound is success.
Optimistic concurrency and Conflict
Update can fail with Conflict when resourceVersion changed between read and write—common in busy clusters or when multiple writers touch the same object.
Patterns:
- RequeueAfter short delay with
nilerror for benign races. - Switch hot paths to patch or Server-Side Apply to reduce contention when field ownership is clear.
After conflict: requeue vs patch strategy (pointers to deeper guides)
If conflicts are frequent, your reconcile may be doing read-modify-write on large objects. Consider:
- Narrower patches (only fields you own).
- SSA with a dedicated field manager (see SSA in operators).
- Reviewing whether status updates should use
Status().Patch/ SSA subresource flows described in status and conditions.
Idempotency checklist (same key, many runs)
Side effects and ordering
Reconcile must tolerate N runs for the same resourceVersion or equivalent logical state. External side effects (S3 buckets, DNS records, billing calls) should be guarded by:
- deterministic names,
- compare-and-create patterns,
- or finalizer-gated cleanup (see finalizers explained).
Write, re-read, and cache assumptions
After a write, the in-memory object can be stale. Either re-fetch, use the returned object from Create/Patch, or rely on the next event—but do not assume fields you did not set stayed untouched.
Status writes and reconcile noise (link to predicates)
Writing status on every pass can create watch noise. Combine careful diffing (only patch when status changed) with predicates such as generation-based filters so .status updates do not fan out into full spec reconciles unless you intend that.
Anti-patterns and production surprises
Using errors for normal “waiting” states
This is the most common beginner bug: it turns “waiting for rollout” into “exponential backoff climbing to minutes.” Prefer RequeueAfter or child-resource watches.
Tight RequeueAfter loops
Sub-second RequeueAfter everywhere can still overload the apiserver if cardinality is high. Combine with shared work, batching, or higher-level coordination when reconciling thousands of objects.
Masking bugs with infinite retry
If logic is wrong, backoff only slows the failure—it does not fix it. Investigate reconciliation logs, object events, and diff of managed children.
Logging volume and cardinality on hot paths
Every return err may log a stack or message each backoff cycle. For known benign states, downgrade to debug logs inside a branch that returns RequeueAfter instead.
Putting it together: a small skeleton Reconcile
Ordered phases (get → validate → mutate → status → return)
func (r *MyReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
logger := log.FromContext(ctx)
var cr myv1alpha1.MyKind
if err := r.Get(ctx, req.NamespacedName, &cr); err != nil {
return ctrl.Result{}, client.IgnoreNotFound(err)
}
// Terminal validation example
if err := validateSpec(&cr); err != nil {
// update status / event, then:
return ctrl.Result{}, nil
}
if err := r.ensureChildren(ctx, &cr); err != nil {
if apierrors.IsConflict(err) { // k8s.io/apimachinery/pkg/api/errors
return ctrl.Result{RequeueAfter: time.Second}, nil
}
return ctrl.Result{}, err // transient
}
if !r.ready(&cr) {
return ctrl.Result{RequeueAfter: 10 * time.Second}, nil
}
if err := r.patchStatusReady(ctx, &cr); err != nil {
return ctrl.Result{}, err
}
logger.Info("steady state", "name", cr.Name)
return ctrl.Result{}, nil
}Commented returns for each branch
IgnoreNotFound: deleted object → success, no requeue.- Validation branch: user must fix spec → success, no requeue (terminal pattern).
Conflict: shortRequeueAfter, not necessarily an error signal.- Generic
err: infrastructure / unknown → backoff viareturn err. readyfalse: controlled polling viaRequeueAfter.- Final
nil: converged until watches fire again.
Adapt naming to your APIs; the structure is what matters in review.
Frequently Asked Questions
Does returning Result{Requeue: true}, nil replace watches?
No. Watches should still be your primary driver. Requeue: true is for edge cases where you know another pass is needed before external events will arrive.
Should multi-resource operators always use RequeueAfter?
Not by default. Prefer Owns / Watches for child objects (see multi-resource reconciliation) so the queue wakes on real changes instead of timers.
How does this relate to drift detection?
Drift checks often add periodic verification; align timers with drift detection patterns instead of hammering error returns.
Further reading
Related articles
- The Kubernetes reconcile loop explained
- controller-runtime architecture
- Watches, events, and predicates
- Status subresource and conditions
- Server-Side Apply in operators
- Go Kubernetes Operator SDK tutorial
Upstream references
- controller-runtime
Reconcilerinterface - client-go workqueue rate limiting
- Kubebuilder reconciliation reference
Bottom line: treat error as “this attempt broke” and RequeueAfter as “this attempt succeeded but the world is not ready yet.” Steady convergence returns Result{}, nil. Classify NotFound and Conflict explicitly, keep Reconcile idempotent, and use predicates so retries reflect real cluster change—not noise.