![Using SQL GROUP BY with Multiple Columns [SOLVED]](/sql-group-by-multiple-columns/sql-group-by-multiple-columns.webp)
Introduction - Using SQL GROUP BY Multiple Columns
Welcome to this comprehensive tutorial on SQL GROUP BY multiple columns,
an essential feature in the world of database management and data
analysis. Whether you're dealing with sales data, customer behavior, or
any other relational data, grouping your results by multiple columns can
offer invaluable insights into your dataset. Not only does this powerful
SQL feature enable you to simplify complex data into more manageable forms, but it also
paves the way for intricate data analysis using aggregate functions. If
you're looking to become proficient in SQL, mastering the art of using
the GROUP BY clause with multiple columns is indispensable. Read on to
learn the ins and outs of this fundamental SQL operation.
Let's Start with Basic Syntax
Understanding the syntax is the first crucial step in mastering any SQL operation. In this section, we will delve into the basic syntax of the SQL GROUP BY clause, followed by its more advanced form—SQL GROUP BY multiple columns.
1. SQL GROUP BY Syntax
The GROUP BY clause is used to group rows in a table based on one or more columns, commonly used with SQL functions to count, sum, average, etc., the data in those columns. The basic syntax is:
SELECT column1, aggregate_function(column2)
FROM table
GROUP BY column1;Here, aggregate_function could be SUM, COUNT, AVG, MIN, MAX,
etc., and column1 is the column by which we are grouping the data.
2. SQL GROUP BY Multiple Columns: Syntax
When you need to group by more than one column, the syntax becomes a little more complex but remains quite intuitive. To group data by multiple columns, you simply separate the column names with commas in the GROUP BY clause:
SELECT column1, column2, aggregate_function(column3)
FROM table
GROUP BY column1, column2;In this extended form of SQL GROUP BY multiple columns, column1 and
column2 are the columns by which the data is grouped, and column3 is
the column that the aggregate function operates on.
Sample Tables for Demonstration
For the topic of SQL GROUP BY multiple columns, let's consider two
simple tables: Orders and Customers.
Orders Table
Assume that you have an Orders table with the following columns and
some sample data:
OrderID(Unique identifier for each order)CustomerID(Identifier for the customer who placed the order)Product(Name of the product ordered)OrderDate(Date on which the order was placed)Amount(Amount spent on the order)
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
Product VARCHAR(50),
OrderDate DATE,
Amount INT
);
INSERT INTO Orders (OrderID, CustomerID, Product, OrderDate, Amount)
VALUES
(1, 1, 'Laptop', '2021-01-01', 1000),
(2, 1, 'Phone', '2021-01-15', 500),
(3, 2, 'TV', '2021-02-01', 1500),
(4, 3, 'Camera', '2021-02-15', 800),
(5, 3, 'Laptop', '2021-03-01', 1200),
(6, 1, 'Camera', '2021-03-10', 900);Customers Table
Next, consider a Customers table with these columns and sample data:
CustomerID(Unique identifier for each customer)FirstName(First name of the customer)LastName(Last name of the customer)
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50)
);
INSERT INTO Customers (CustomerID, FirstName, LastName)
VALUES
(1, 'John', 'Doe'),
(2, 'Jane', 'Smith'),
(3, 'Emily', 'Johnson');Time to start with Basic Usage
After understanding the syntax and setting up our sample tables, let's
move on to basic usage of the GROUP BY clause. We'll start with some
straightforward examples using a single column and then introduce the
concept of SQL GROUP BY multiple columns.
Simple Examples with Single Column GROUP BY
The primary purpose of using GROUP BY with a single column is to
consolidate rows that share the same value in that column into summary
rows. Here are some examples using the Orders and Customers tables:
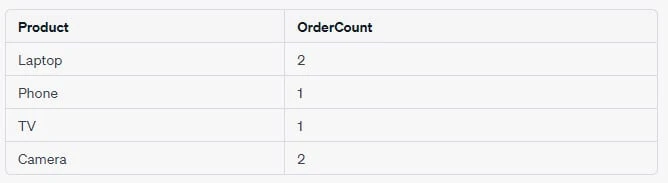
Example 1: Count Orders Per Product
To count the number of orders for each product, we can use the following SQL query:
SELECT Product, COUNT(*) AS OrderCount
FROM Orders
GROUP BY Product;This query will group the records in the Orders table by the Product
column and count the number of orders for each group.
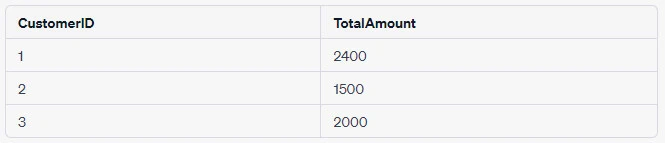
Example 2: Sum Amount Spent by Each Customer
Here, we will sum the amount spent by each customer:
SELECT CustomerID, SUM(Amount) AS TotalAmount
FROM Orders
GROUP BY CustomerID;This query will group records by the CustomerID and then sum up the
Amount for each group.
Introduction to GROUP BY with Multiple Columns
When you need to perform more complex data analysis that involves multiple dimensions, you'll find the SQL GROUP BY multiple columns feature incredibly useful. This allows you to group data based on combinations of multiple columns.
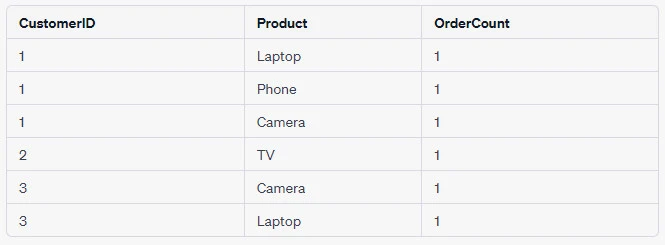
Example 3: Count Orders Per Customer for Each Product
For instance, let's count the number of orders placed by each customer for each product:
SELECT CustomerID, Product, COUNT(*) AS OrderCount
FROM Orders
GROUP BY CustomerID, Product;This query will group the records in the Orders table by both the
CustomerID and Product columns, and then count the number of orders
for each combination.
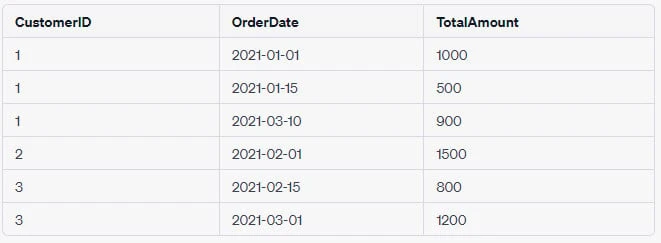
Example 4: Sum Amount Spent by Each Customer on Each Order Date
SELECT CustomerID, OrderDate, SUM(Amount) AS TotalAmount
FROM Orders
GROUP BY CustomerID, OrderDate;Here, the records are grouped by both CustomerID and OrderDate, and
the total amount spent by each customer on each date is summed up.
Using HAVING with GROUP BY with Multiple Columns
In SQL, the HAVING clause is used alongside GROUP BY to filter the
groups based on some condition. When you're working with SQL GROUP BY
multiple columns, HAVING can further refine your result sets based on
aggregate functions.
What is the HAVING Clause?
The HAVING clause is like a WHERE clause for groups. It is applied
after the GROUP BY operation and filters groups based on an aggregate
condition. For example, you might want to filter out groups that have a
total amount spent less than a certain value.
Difference between WHERE and HAVING
WHERE: Filters rows before theGROUP BYoperation.HAVING: Filters groups after theGROUP BYoperation.
The basic syntax for using the HAVING clause with GROUP BY in SQL is
as follows:
SELECT column1, column2, aggregate_function(column3)
FROM table_name
GROUP BY column1, column2
HAVING aggregate_function(column3) condition;Here, column1, column2, and column3 represent the columns in your
table, and table_name is the name of the table.
aggregate_function(column3) could be any aggregate function like
SUM, COUNT, AVG, etc., and condition is the condition you want
the groups to meet.
Example 1: Filter Customers with Total Amount Spent Greater than 1500
SELECT CustomerID, SUM(Amount) AS TotalAmount
FROM Orders
GROUP BY CustomerID
HAVING TotalAmount > 1500;Output Table:

Example 2: Filter Orders by Multiple Columns and Having Condition
SELECT CustomerID, Product, COUNT(*) AS OrderCount
FROM Orders
GROUP BY CustomerID, Product
HAVING OrderCount >= 1;Output Table:
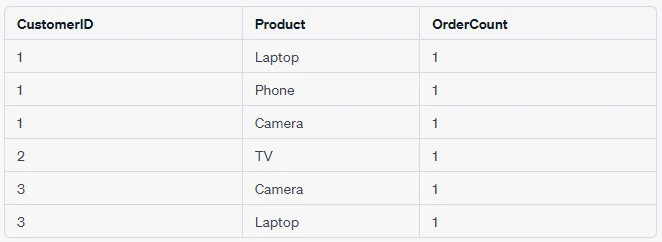
Example 3: Orders with Same Product More Than Once
SELECT Product, COUNT(*) AS OrderCount
FROM Orders
GROUP BY Product
HAVING OrderCount > 1;Output Table:

Using ORDER BY with GROUP BY with Multiple Columns
When working with GROUP BY in SQL, you may often find it useful to
sort the grouped results for better readability or analysis. This is
where the ORDER BY clause comes in. The ORDER BY clause sorts the
result set based on one or more columns, and it works seamlessly with
GROUP BY even when multiple columns are involved.
Syntax for Using ORDER BY with GROUP BY
The basic SQL syntax for using ORDER BY with GROUP BY is:
SELECT column1, column2, aggregate_function(column3)
FROM table_name
GROUP BY column1, column2
HAVING aggregate_function(column3) condition
ORDER BY column1 [ASC|DESC], column2 [ASC|DESC];Here, [ASC|DESC] denotes the sorting order: Ascending (ASC) or
Descending (DESC).
Example Syntax with Explanation
Suppose you want to group records by CustomerID and Product, count
them, and then order the result set by CustomerID in ascending order
and Product in descending order. The SQL query could look something
like this:
SELECT CustomerID, Product, COUNT(*) AS OrderCount
FROM Orders
GROUP BY CustomerID, Product
ORDER BY CustomerID ASC, Product DESC;Let's assume we have our sample data, and we execute the above query. The output could look like:
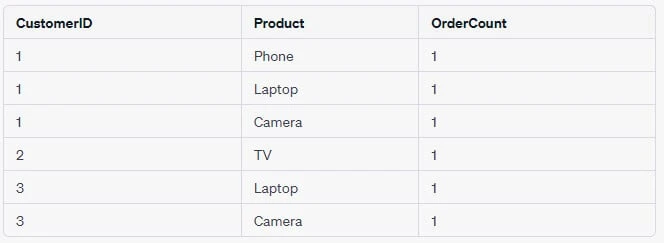
In the above table, you can see that the results are grouped by
CustomerID and Product as specified by the GROUP BY clause.
Additionally, the ORDER BY clause sorts these grouped results by
CustomerID in ascending order and by Product in descending order.
Using GROUP BY with Joins
Combining GROUP BY with joins in SQL allows you to perform aggregation
on the result set of a joined query. This enables you to summarize
complex datasets that are sourced from multiple tables. Let's go over
how to use GROUP BY in the context of SQL joins.
Syntax for Using GROUP BY with Joins
The syntax for using GROUP BY with joins can be generalized as
follows:
SELECT t1.column1, t2.column2, aggregate_function(t1.column3)
FROM table1 t1
JOIN table2 t2 ON t1.columnX = t2.columnY
GROUP BY t1.column1, t2.column2;In this syntax, t1 and t2 are aliases for table1 and table2
respectively. You join these tables based on some condition
(t1.columnX = t2.columnY), and then group the resulting dataset by
columns from both tables (t1.column1, t2.column2).
Example: Total Amount Spent by Each Customer on Each Product
Let's consider two tables: Orders and Customers.
- Orders: Contains OrderID, CustomerID, Product, and Amount
- Customers: Contains CustomerID, CustomerName
We'll try to find out the total amount spent by each customer on each product.
SELECT c.CustomerName, o.Product, SUM(o.Amount) AS TotalAmount
FROM Orders o
JOIN Customers c ON o.CustomerID = c.CustomerID
GROUP BY c.CustomerName, o.Product
ORDER BY TotalAmount DESC;Assuming we have the same sample data, executing the above query could give us the following output:
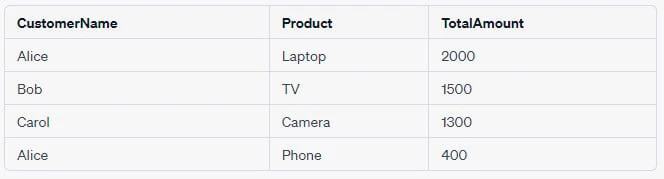
In this example, the JOIN
combines rows from Orders and Customers based on matching CustomerID values.
Then, the GROUP BY clause groups the joined dataset by CustomerName
and Product. Finally, SUM(o.Amount) sums up the amounts for these
groups.
Using Nested GROUP BY with Multiple Columns
The concept of "nesting" a GROUP BY clause within another doesn't directly exist in SQL as it does in some other programming constructs. However, you can achieve similar outcomes by using subqueries or by using advanced SQL window functions.
Here, I'll explain a way to mimic "nested" GROUP BY operations using a
subquery.
Syntax for a "Nested" GROUP BY with Multiple Columns
The syntax for a "nested" GROUP BY using a subquery could look like
this:
SELECT column1, aggregate_function2(column2)
FROM (
SELECT column1, column2, aggregate_function1(column3)
FROM table
GROUP BY column1, column2
) AS subquery
GROUP BY column1;Example: Average Sales for Each Category, by Each Store
Let's consider a table named Sales with the following columns:
StoreIDCategoryIDAmount
We first want to find the total sales for each category within each store. Then we want to find the average total sales for each store.
SELECT StoreID, AVG(TotalAmount) AS AvgAmount
FROM (
SELECT StoreID, CategoryID, SUM(Amount) AS TotalAmount
FROM Sales
GROUP BY StoreID, CategoryID
) AS SubQuery
GROUP BY StoreID;The output table:
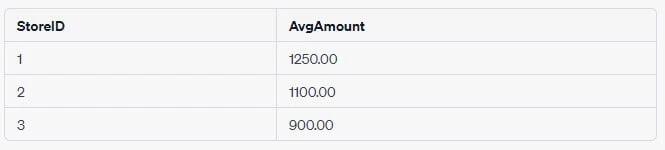
In this example, the subquery first groups the sales data by both
StoreID and CategoryID, calculating the TotalAmount for each group
using SUM(Amount). Then, the outer query takes this result and groups
it by StoreID again, this time calculating the average total amount
(AvgAmount) for each store using AVG(TotalAmount).
Using GROUP BY with ROLLUP and CUBE
In SQL, GROUP BY can be extended with the ROLLUP and CUBE
operators to provide subtotals and grand totals within the result set.
These operators generate multiple grouping sets that enable more complex
data analysis.
1. GROUP BY with ROLLUP
ROLLUP is used to create subtotals that roll up from the most detailed
level to a grand total, following the grouping list from left to right.
Syntax:
SELECT column1, column2, aggregate_function(column3)
FROM table_name
GROUP BY ROLLUP (column1, column2);Assuming we have a table Sales with columns Region and Product,
and Amount, you can find the total sales for each product in each
region, as well as subtotals for each region and a grand total like
this:
SELECT Region, Product, SUM(Amount) as TotalAmount
FROM Sales
GROUP BY ROLLUP (Region, Product);Output Table:
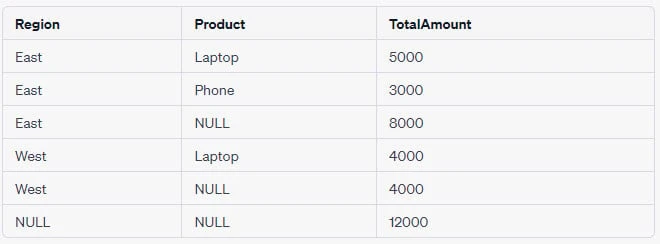
2. GROUP BY with CUBE
CUBE generates a result set that represents aggregates for all
combinations of values in the selected columns.
Syntax:
SELECT column1, column2, aggregate_function(column3)
FROM table_name
GROUP BY CUBE (column1, column2);Example:
To generate a result set that shows all the possible combinations of
Region and Product totals, you can use:
SELECT Region, Product, SUM(Amount) as TotalAmount
FROM Sales
GROUP BY CUBE (Region, Product);Output Table:
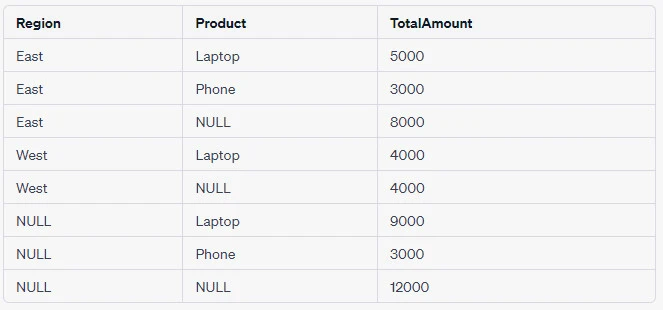
3. GROUP BY in Subqueries
Subqueries can use the GROUP BY clause to generate summary rows that
can then be used in the outer query for further processing or filtering.
Syntax:
SELECT column1, aggregate_function(subquery_column)
FROM (
SELECT column1, aggregate_function(column2)
FROM table_name
GROUP BY column1
) AS subquery
GROUP BY column1;Example:
Let's assume you want to find the average order amount for customers who have an average order amount greater than 1000.
Firstly, you would have a subquery to identify the CustomerIDs who
have an average order amount greater than 1000:
SELECT CustomerID
FROM Orders
GROUP BY CustomerID
HAVING AVG(Amount) > 1000;Based on the sample data, the subquery will return the CustomerIDs
with an average order amount greater than 1000.
Using GROUP BY with Partitioning Functions
SQL window functions can be used to perform calculations across sets of
table rows that are related to the current row within the same result
set. This is referred to as a "partition," and often you'll find it used
with over the GROUP BY clause.
Syntax:
SELECT column1, aggregate_function() OVER (PARTITION BY column2)
FROM table_name;Example:
If you have a Salaries table with EmployeeID and Salary columns,
and you want to find the maximum salary for each department without
actually reducing the number of rows, you could use:
SELECT EmployeeID, Department, Salary, MAX(Salary) OVER (PARTITION BY Department)
FROM Salaries;Output Table:
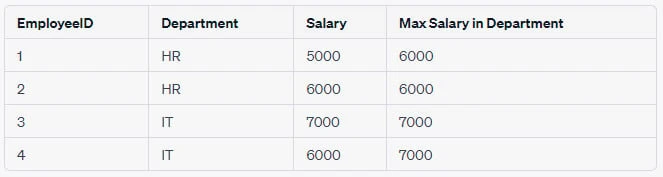
In this example, the MAX(Salary) OVER (PARTITION BY Department) part
calculates the maximum salary for each department and adds that as a new
column in the result set. It does this without reducing the number of
rows returned, unlike what would happen with a regular GROUP BY.
Practical Examples and Exercises
Example 1: Simple GROUP BY with Two Columns
-- Sample Data
CREATE TABLE Employee (
Department VARCHAR(50),
Gender VARCHAR(10),
Salary INT
);
INSERT INTO Employee VALUES
('HR', 'Male', 5000),
('HR', 'Female', 6000),
('IT', 'Male', 7000),
('IT', 'Female', 8000),
('IT', 'Male', 6000),
('HR', 'Female', 7000);
-- Query
SELECT Department, Gender, AVG(Salary) AS AvgSalary
FROM Employee
GROUP BY Department, Gender;Output Table:
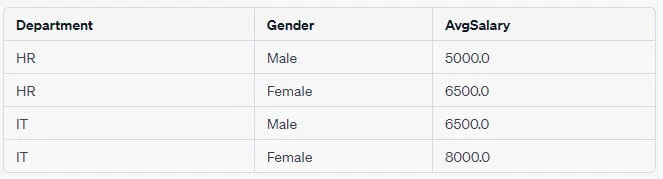
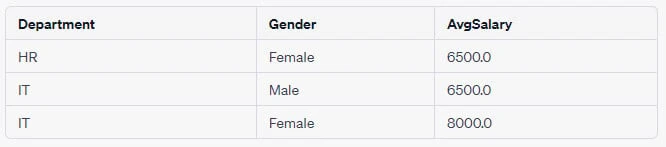
Example 2: Using GROUP BY with HAVING
-- Query
SELECT Department, Gender, AVG(Salary) AS AvgSalary
FROM Employee
GROUP BY Department, Gender
HAVING AVG(Salary) > 6000;Output Table:
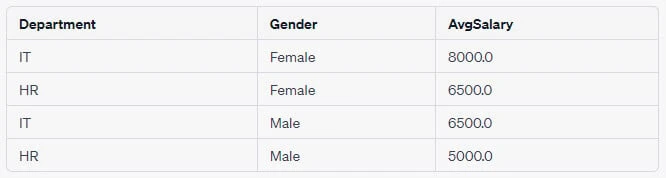
Example 3: Using GROUP BY with ORDER BY
-- Query
SELECT Department, Gender, AVG(Salary) AS AvgSalary
FROM Employee
GROUP BY Department, Gender
ORDER BY AVG(Salary) DESC;Output Table:
Summary
In this tutorial, we've dived into the intricacies of using SQL's GROUP BY clause with multiple columns. Starting with the basic syntax, we explored how to combine grouping across various columns to aggregate data in sophisticated ways. We touched upon the usage of additional SQL clauses like HAVING and ORDER BY to fine-tune our grouped results further. Practical examples and exercises were provided to deepen your understanding and offer hands-on practice.
Here's a quick recap of what we covered:
- Basic Syntax: How to write a simple GROUP BY clause and its extension to multiple columns.
- Sample Tables for Demonstration: Provided concrete examples using sample tables to illustrate the queries.
- HAVING with GROUP BY: Filtering grouped results based on aggregated data.
- Using ORDER BY: Sorting grouped data for easier analysis.
- Advanced Techniques: Covered nested queries, usage with JOINs, and other advanced techniques like ROLLUP and CUBE.
- Practical Examples and Exercises: Hands-on tasks to solidify your learning.
Additional Resources
For those who want to delve deeper into the subject, here are some recommended resources:
- Documentation
- Online Tutorials
- Interactive Learning Platforms
