
SQL GROUP BY Statement
Data Grouping and Data Aggregation are the important concepts of SQL. There are circumstances where we need to apply aggregate function not only to a single set of rows, but also to a group of rows that have the same values, so in such a situation, the SQL GROUP BY statement is used with SQL SELECT statement.
The GROUP BY clause is part of the SQL SELECT statement. Optionally it is used in conjunction with aggregate functions to produce the resulting group of rows from the database.
SQL GROUP BY clause is placed after the WHERE clause and before the ORDER BY clause in SQL select statement.
SQL GROUP BY Statement Syntax
GROUP BY (
column-Name [ , column-Name ]* |
ROLLUP ( column-Name [ , column-Name ]* |
CUBE (column-Name [, column-Name ]* |
GROUPING SETS (column-Name [, column-Name ]*
)**column-Name:****Specifies a column or a non-aggregate calculation on a column. This column can belong to a table, derived table, or view. The column must appear in the FROM clause of the SELECT statement but is not required to appear in the SELECT list.
GROUP BY(column-Name [, column-Name] *):Groups the SELECT statement results according to the values in a list of one or more column expressions.
GROUP BYROLLUP ()
- ROLLUP is a simple extension to the SQL Group by clause, ROLLUP enables a SQL SELECT statement to calculate multiple levels of subtotals across a specified group of dimensions.
- In addition, GROUP BY ROLLUP to aggregate data and improve the data analytical capabilities in SQL Server.
GROUP BY CUBE ()
- GROUP BY CUBE is also an extension of theGROUP BYclausesimilar toGROUP BYROLLUP.GROUP BY CUBE creates groups for allpossible combinationsof columns.
- CUBEis especially valuable in queries that use columns from multiple dimensions rather than columnsrepresentingdifferent levelsof a single dimension.
- In addition to producing all the rows of aGROUP BY ROLLUP, GROUP BY CUBE adds all the “cross-tabulations” rows. Sub-total rows are rows that further aggregate whose values are derived by computing the same aggregate functions that were used to produce the grouped rows.
GROUP BY GROUPING SETS()
- GROUP BY GROUPING SETS is a powerful extension of the GROUP BY clause that allows computing multiple group-by clauses in a single statement. It is either used with ROLLUP or CUBE operator.
- The GROUPING SETS option gives you the ability to combine multiple GROUP BY clauses into one GROUP BY clause. The results are the equivalent of UNIONALLofthe specified groups.
- For example,GROUP BY ROLLUP (Country, Region)andGROUP BY GROUPING SETS(ROLLUP(Country, Region))return the same results.
- Using a single column as its argument, GROUPING returns 1 when itencountersa NULL value created by a ROLLUP or CUBE operation. That is, if the NULLindicatesthe row is a subtotal, GROUPING returns a 1. Any other type of value, including a stored NULL, will return a 0.
SQL GROUP BY Statement with SELECT Clause Syntax
SELECT clause with WHERE Condition:
SELECT [column_name | aggregate_function_name(column_name),... ]
FROM [table_name]
[WHERE conditions]
GROUP BY column_name1[, column_name2...]
[ORDER BY expression [ ASC | DESC]];SELECT clause with HAVINGCondition:
SELECT [column_name | aggregate_function_name(column_name),... ]
GROUP BY column_name1[, column_name2...]
[HAVING condition];SQL GROUP BY Statement | Aggregate Functions
Aggregate functions are functions that take a set of rows as input and return a single value. In SQL we have five aggregate functions which are also called multirow functions as follows.
SUM (): Returns the sum or total of each group.COUNT (): Returns the number of rows of each group.AVG (): Returns the average and mean of each group.MIN (): Returns the minimum value of each group.MAX (): Returns the minimum value of each group.
For examples of SQL GROUP BY Statement, here we are considering some tables of school management systems:

The Records of above tables are as follow:
Student Table
| student_id | studentname | admissionno | admissiondate | enrollmentno | date_of_birth | city | class_id | |
|---|---|---|---|---|---|---|---|---|
| 101 | reema | 10001 | 02-02-2000 | e15200002 | 02-02-1990 | [email protected] | surat | 2 |
| 102 | kriya | 10002 | 04-05-2001 | e16200003 | 04-08-1991 | [email protected] | surat | 1 |
| 103 | meena | 10003 | 06-05-1999 | e15200004 | 02-09-1989 | [email protected] | vadodara | 3 |
| 104 | carlin | 2001 | 04-01-1998 | e14200001 | 04-04-1989 | [email protected] | vapi | 1 |
| 105 | dhiren | 2002 | 02-02-1997 | e13400002 | 02-02-1987 | [email protected] | vapi | 2 |
| 106 | hiren | 2003 | 01-01-1997 | e13400001 | 03-03-1887 | [email protected] | surat | 2 |
| 107 | mahir | 10004 | 06-09-2000 | e15200003 | 07-09-1990 | [email protected] | vapi | 3 |
| 108 | nishi | 2004 | 02-04-2001 | e16200001 | 03-02-1991 | [email protected] | vadodara | 1 |
Result Table
| result_id | student_id | examname | examdate | subject | obtainmark | totalmarks | percentage | grade | status |
|---|---|---|---|---|---|---|---|---|---|
| 3001 | 101 | sem1 | 07-08-2001 | 1 | 80 | 100 | 80 | A+ | pass |
| 3002 | 101 | sem1 | 08-08-2001 | 2 | 76 | 100 | 76 | A+ | pass |
| 3003 | 102 | sem3 | 05-05-2000 | 3 | 67 | 100 | 67 | A | pass |
| 3004 | 102 | sem3 | 06-05-2000 | 4 | 89 | 100 | 89 | A+ | pass |
| 3005 | 102 | sem3 | 07-05-2000 | 5 | 90 | 100 | 90 | A+ | pass |
| 3006 | 103 | sem5 | 08-09-1998 | 6 | 55 | 100 | 55 | B | pass |
| 3007 | 103 | sem5 | 09-09-1998 | 7 | 30 | 100 | 30 | D | fail |
| 3008 | 103 | sem5 | 10-09-1998 | 8 | 34 | 100 | 34 | D | fail |
Subject Table
| subjectid | facultyname | subjectname | subjectcode |
|---|---|---|---|
| 1 | krishna | c | 1003 |
| 2 | rahul | cpp | 1004 |
| 3 | radha | asp | 1005 |
| 4 | meera | sql | 1006 |
| 5 | yasoda | cloud | 1007 |
| 6 | nadan | cg | 1008 |
SQL GROUP BY Statement | Single column Example
Count the number of students in each class using SQL GROUP BY Statement
SELECT class_id, COUNT (*) AS 'Total student'
FROM tblstudent
GROUP BY class_id;- To get the result of student count class-wise, we applied the SQL GROUP BY clause on class_id
- The COUNT function is used to make counting, count (*) counts the number of rows produced by the query.
OUTPUT:

SQL GROUP BY WITH JOIN Example | Multiple columns
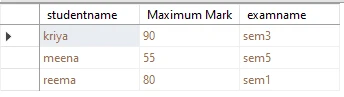
Use SQL GROUP BY Statement with join query to get detail of students who obtained maximum marks in his/her semester
SELECT tblstudent.studentname, MAX(tblresult.obtainmark) AS 'Maximum Mark', tblresult.examname
FROM tblstudent INNER JOIN
tblresult ON tblstudent.student_id = tblresult.student_id
GROUP BY tblresult.examname, tblstudent.studentname;- In the above query, we have to use the MAX function to find maximum marks from each group of records which extract using group by clause.
- INNER JOIN is used to get data from both the tables, student name from tblstudent and obtain mark and examname from tblresult.
OUTPUT:
SQL GROUP BY | INNER JOIN & WHERE Clause Example
To find the total number of passing students in each subject use SQL GROUP BY Statement with WHERE condition and INNER JOIN.
SELECT COUNT (*) AS 'total pass', tblsubject.subjectname
FROM tblsubject CROSS JOIN tblresult
WHERE (tblresult.status = 'pass')
GROUP BY tblsubject.subjectname;- In the previous query, we make use of WHERE, GROUP BY, and INNER JOIN to make a group of records of each subject we applied group by subjectname, as we want to find passing student count, we put the condition as status as pass.
OUTPUT:

SQL GROUP BY Statement | Having Clause
HAVING Clause is used as a conditional statement with GROUP BY Clause in SQL. WHERE Clause cannot be combined with aggregate results so Having clause is used which returns rows where aggregate function results matched with given conditions only.
INNER JOIN & HAVING Clause Example
Retrieve the detail of students who secure an average of more than 60 marks in each semester with the help of SQL GROUP BY and HAVING clause
SELECT AVG(tblresult.obtainmark) AS 'Average Mark', tblstudent.studentname, tblresult.examname AS semester
FROM tblresult INNER JOIN
tblstudent ON tblresult.student_id = tblstudent.student_id
GROUP BY tblresult.examname, tblstudent.studentname
HAVING (AVG(tblresult.obtainmark) > 60);- In the above query, we use AVG, INNER JOIN GROUP BY, AND HAVING Clauses, when we applied GROUP BY it will make groups of students semester wise then make inner join result table with students to retrieve detail of student, AVG function is used to calculate average obtained marks, and to check average marks more than 60 we applied HAVING clause.
OUTPUT:

SQL GROUP BY Statement | ROLLUP clause with GROUP BY clause
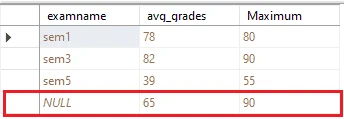
Using SQL GROUP BY Statement extract average and a maximum of obtained marks in each semester and make sub-average and sub-max of resulting set
SELECT examname, AVG(obtainmark) AS avg_grades, MAX(obtainmark) AS Maximum
FROM tblresult
GROUP BY ROLLUP (examname);- As we already study ROLLUP produces a result setcontainingthe resulting group of SQL GROUP BY clause and the subgroup of values.
- In the above example we first make a group of exam name-wise records of table results then applied AVG and MAX aggregate functions on that group, it gives another result set of AVG and MAX obtained marks student records, from which rollup will obtain sub-AVG and sub-MAX.
OUTPUT:
SQL GROUP BY Statement | CUBE Clause WITH GROUP BY
ROLLUP and CUBE will give you the same result if we applied with only one column name. To see the difference between both we need to use two columns in GROUP BY
SELECT tblresult.examname, tblsubject.subjectname, AVG(tblresult.obtainmark) AS avg_grades, MAX(tblresult.obtainmark) AS Maximum
FROM tblsubject INNER JOIN
tblresult ON tblsubject.subjectid = tblresult.subjectid
GROUP BY CUBE (tblsubject.subjectname, tblresult.examname);- In exceeding example, we applied GROUP BY with CUBE to get cross-tabulation rows of first subject name and then semester wise.
- To get the result subject name wise we also used SQL INNER JOIN in the above example.
OUTPUT:

SQL GROUP BY Statement | GROUPING & HAVING CLAUSE
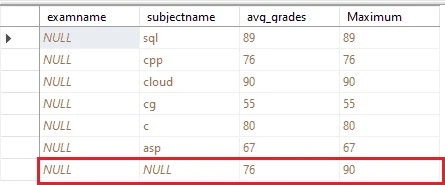
In the previous section we have learned about the use of GROUPING with GROUP BY, to filter the resulting set of CUBE AND ROLLUP, we applied the same concept in the below query
SELECT tblresult.examname, tblsubject.subjectname, AVG(tblresult.obtainmark) AS avg_grades, MAX(tblresult.obtainmark) AS Maximum
FROM tblsubject INNER JOIN tblresult ON tblsubject.subjectid = tblresult.subjectid
GROUP BY CUBE (tblsubject.subjectname, tblresult.examname)
HAVING (GROUPING(tblresult.examname) = 1)
ORDER BY tblsubject.subjectname;- In this query, we have applied GROUPING and HAVING clause with SQL GROUP BY Statement, when we cubing the result set of GROUPS BY with two columns the result we show as each column-wise Super aggregation result same in out query, we get first subject-wise and then exam name wise aggregation of AVG and MAX marks obtained data.
- So,to filter NULL result data from this we make SUB-GROUPING at one column.
OUTPUT:
Summary
The SQL GROUP BY clause and SQL HAVING clause are powerful clauses of SQL, specifically used to analyze large amounts of data. In this article, we covered SQL GROUP BY with WHERE, HAVING, ROLLUP, CUBE, GROUPING, ORDER BY, and also some examples of INNER JOIN also.
Further Reading
https://docs.microsoft.com/en-us/sql/t-sql/queries/select-group-by-transact-sql?view=sql-server-ver15








![SOLVED: SQL ambiguous column name [5 Possible Causes]](/sql-ambiguous-column-name/sql_ambigious_hu_2b325ecfd676ecdf.webp)