![Supervised Learning Algorithms Explained [Beginners Guide]](/supervised-learning-algorithms/supervisord_lerarning_algo.jpg)
Introduction to Supervised Learning Algorithms
An algorithm is a set of instructions for solving a problem or accomplishing a task. In this tutorial, we will learn about supervised learning algorithms within the broader types of machine learning landscape. For a hands-on regression walkthrough in Python, see simple linear regression; for a Python ML primer, see introduction to Python for machine learning. We will discuss two main categories of supervised learning algorithms including classification algorithms and regression algorithms. We will cover linear classifier, KNN, Naive Bayes, decision tree, logistic regression, and support vector machine learning algorithm under classification. At the same time, we will briefly discuss some of the regressions algorithms as well including linear regression,and polynomial regression. In a nutshell, this tutorial will briefly describe different types of popular supervised learning algorithms.
Getting Started with Supervised learning algorithms
Supervised learning is a subcategory of machine learning. It is defined by its use of labeled datasets to train algorithms to classify data or predict outcomes accurately. As input data is fed into the model, it adjusts its weights until the model has been fitted appropriately, which occurs as part of the cross-validation process. You can learn more about supervised learning from the article on types of machine learning
Basically there are two types of supervised algorithms,Classification and Regression as shown in the diagram below:

In the upcoming sections, we will discuss classification algorithms and regression algorithms in more detail.
Classification algorithms
Classification is a term used to describe any situation in which a specified type of class label is predicted from a given field of data. The output is usually a category or a discrete number. Some of the famous classification problems are email filtering, face recognition, handwritten recognition, classifying animals into the same categories, and many more problems where the output is categorical. There are various types of classification algorithms that can be used to predict the output class based on the problem. In the upcoming sections, we will discuss some of the classification algorithms briefly.
Supervised learning algorithms-1 Linear Classifier
A linear classifier does a classification decision based on the value of a linear combination of the characteristics. It works best when the given problem is linearly separable. See the diagram below:
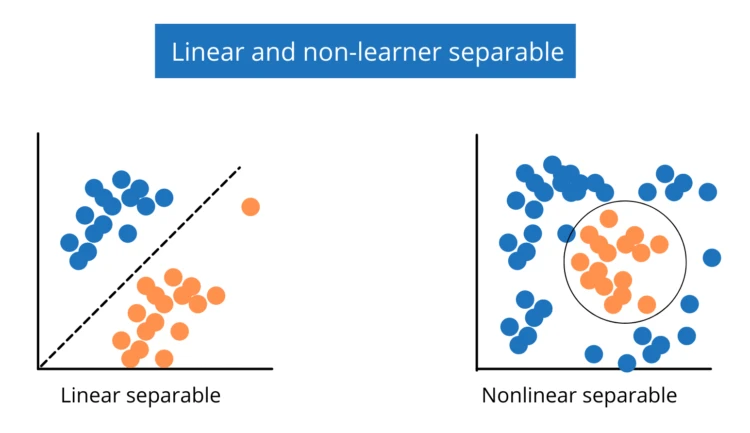
The following is the simple formula used to train our model in the linear classifier. See below:
f(x,W,b)=∑j(Wjxj)+b
where x is the input vector, W is the weight matrix and b is the bias vector. The linear classifier can also be used to classify a classification problem having multiple output possibilities. See the diagram below:
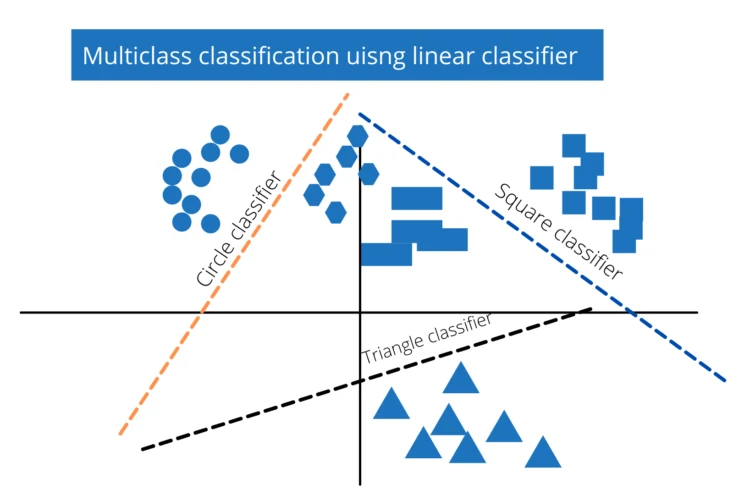
Every class that has to be classified will have one row, and each element(feature) of x will have one column in the weight matrix. Each line in the diagram above will be represented by a row in our weight matrix.
Supervised learning algorithms-2 KNN classification
The KNN(K-nearest neighbor) algorithm assumes that similar things exist in close proximity. In other words, similar things are near to each other. By computing the distance between the test data and all of the training points, KNN tries to predict the proper class for the test data. Then choose the K number of points that are close to the test data. The KNN algorithm analyzes the likelihood of test data belonging to each of the 'K' training data classes, and the class with the highest probability is chosen.

The KNN algorithm finds the distances from the test point to all other points and takes the K number of the nearest point and based on those points, it classifies the test point.
Supervised learning algorithms-3 Naive Bayes algorithm
It's a classification method based on Bayes' Theorem and the assumption of predictor independence. A Naive Bayes classifier, in simple terms, assumes that the existence of one feature in a class is unrelated to the presence of any other feature. We usually use this algorithm in classification problems when the classes/features are not related or independent of each other. For example, if the fruit is red, round, and roughly 3 inches in diameter, it is considered an apple. Even if these characteristics are reliant on one another or on the presence of other characteristics, they all add to the probability that this fruit is an apple, which is why it is called 'Naive.' The following is the formula which is used in naive Bayes algorithm to predict the output class.
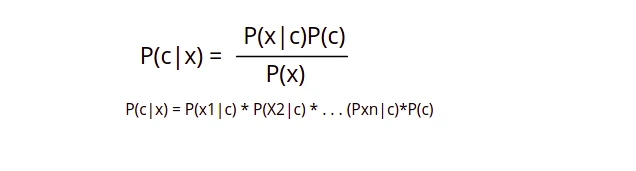
- P(c|x) is the posterior probability ofclass(c,target) givenpredictor(x,attributes).
- P(c) is the prior probability ofclass.
- P(x|c) is the likelihood which is the probability ofpredictorgivenclass.
- P(x) is the prior probability ofpredictor.
Supervised learning algorithms-4 Decision Tree
The most powerful and widely used tool for categorization and prediction is the decision tree. A decision tree is a flowchart-like tree structure in which each internal node represents an attribute test, each branch reflects the test's outcome, and each leaf node (terminal node) stores a class label. The simple form of decision looks like this:

The following are some of the terms used in the decision tree:
- **Root Nodes:**It is the node present at the beginning of a decision tree from this node the population starts dividing according to various features.
- Decision Nodes: The nodes we get after splitting the root nodes are called Decision Node
- Leaf Nodes: The nodes where further splitting is not possible are called leaf nodes or terminal nodes
- Sub-tree: Just like a small portion of a graph is called a sub-graph similarly a sub-section of this decision tree is called a sub-tree.
Supervised learning algorithms-5 Support vector machine
The Support Vector Machine, or SVM, is a popular Supervised Learning technique that may be used to solve both classification and regression issues. However, it is mostly utilized in Machine Learning for classification problems. The SVM algorithm's purpose is to find the optimum line or decision boundary for categorizing n-dimensional space into classes so that additional data points can be readily placed in the correct category in the future. This best decision boundary is called a hyperplane.

SVM chooses the extreme points/vectors that help in creating the hyperplane. These extreme cases are called support vectors, and hence algorithm is termed a Support Vector Machine.
Supervised learning algorithms-6 Logistic Regression
The method of modeling the probability of a discrete result given an input variable is known as logistic regression. The most frequent logistic regression models have a binary outcome, which might be true or false, yes or no, and so on. Multinomial logistic regression can be used to model situations with more than two discrete outcomes. This type of analysis can help you predict the likelihood of an event happening or a choice being made. For example, you may want to know the likelihood of a visitor choosing an offer made on your website. Logistic regression models help you determine the probability of what type of visitors are likely to accept the offer. As a result, you can make better decisions about promoting your offer or make decisions about the offer itself.
Regression Algorithms
Regression analysis is a statistical method to model the relationship between dependent (target) and independent (predictor) variables with one or more independent variables. More specifically, Regression analysis helps us to understand how the value of the dependent variable is changing corresponding to an independent variable when other independent variables are held fixed. It predicts continuous/real values such as temperature, age, salary, price, etc. There are various machine learning algorithms that are used for regression problems. Some of which we will cover in this section.
Supervised learning algorithms-7 Linear Regression
Linear regression analysis is used to predict the value of a variable based on the value of another variable. The variable you want to predict is called the dependent variable. The variable you are using to predict the other variable's value is called the independent variable. This type of analysis involves one or more independent variables that best predict the value of the dependent variable in order to estimate the coefficients of the linear equation. Linear regression creates a straight line or surface that reduces the difference between expected and actual output values. The following diagram shows the visual form of linear regression.

There can be one or more inputs values depending on the type of problem and there is always one predicted output.
Supervised learning algorithms-8 Polynomial regression
Polynomial Regression is derived using the same concept of Linear regression with few modifications to increase accuracy. linear regression algorithm only works when the relationship between the data is linear But suppose if we have non-linear data then Linear regression will not capable to draw a best-fit line and It fails in such conditions. in such situations, polynomial regression helps us to overcome this problem, which identifies the curvilinear relationship between independent and dependent variables. For example, see the visual problem where we can use polynomial regression below:
We use a polynomial regression algorithm when there is no linear relation between input and output classes.
Summary
Classification and regression are two main kinds of categories in supervised machine learning. We discussed different types of classification algorithms briefly including KNN, Naive Bayes, Decision tree, logistic regression, and SVM. At the same time, we discussed the regression algorithms as well including linear and polynomial regression algorithms. To summarize, this tutorial briefly introduces different kinds of supervised learning algorithms.
Further Reading
scikit-learn Modules
sklearn module documentation
Keras module
documentation
