
Linux memory management is a very vast topic and it is not possible to cover all the areas in single article. I will try to give you an overview on major areas and will help you understand important terminologies related to memory management in Linux.
Overview on Linux Memory Management
- The central part of the computer is CPU and RAM is the front end portal to CPU
- Everything that is going to CPU will go through RAM
- For example, if we have a process which is loading, the process will first be loading in RAM and the CPU will get process data from RAM
- But to make it faster, the CPU has level one, level two, level three cache. That is like RAM, but on the CPU
- There's very small amounts of cache on the CPU, because it's very expensive, and it's also not very useful for all the instructions.
- So the process information will be copied from RAM to CPU and the CPU will build its cache.
- Here cache plays an important part of memory management on Linux as well.
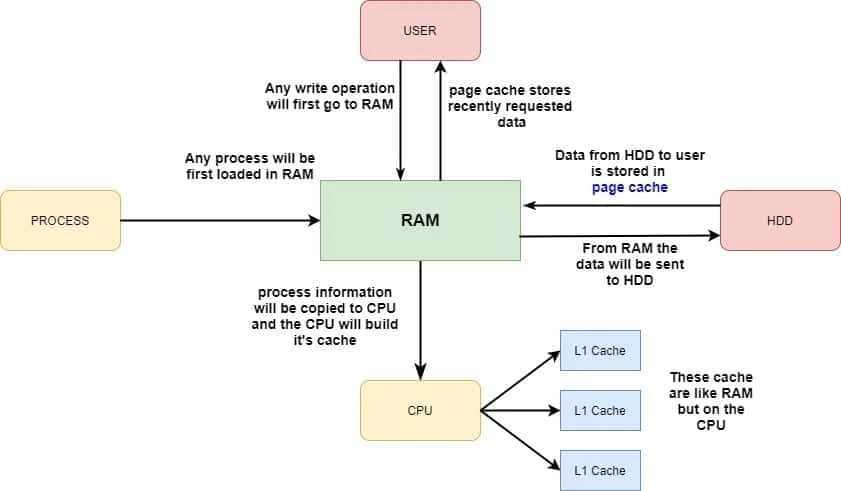
- If a user is requesting information from hard disk, it is copied to RAM, and the user will be served from RAM.
- And while the information is copied from hard disk, it is placed in what you call the page cache.
- So the page cache stores recently requested data to make it faster if the same data is needed again.
- And if the user starts modifying data, it will go to RAM as well, and from RAM it will be copied to the hard disk, but that will only happen if the data has been sitting in RAM long enough.
- Data won't be written immediately from RAM to hard disk, but to optimize write to the hard disk, Linux works with the concept of dirty cache.
- It tries to buffer as much as data in order to create an efficient write request.
- So as you can see in this small diagram, everything that happens on your computer goes through RAM.
- So using RAM on a Linux computer is essential for the well working of the Linux operating system.
Now we will discuss the individual part of Linux memory management and understand different terminologies related to this flow.
Understanding Virtual Memory
When analysing Linux memory usage, you should know how Linux uses Virtual and Resident Memory. Virtual Memory on Linux is to be taken literally: it is a non-existing amount of memory that the Linux kernel can be referred to.
Currently my RHEL 7 Linux has 128GB of Total Physical Memory
# grep MemTotal /proc/meminfo
MemTotal: 131906708 kB
But as you see this node also has 32TB of Virtual Memory
# grep VmallocTotal /proc/meminfo
VmallocTotal: 34359738367 kB
- Now the idea is that if in Linux, when a process is loading, this process needs memory pointers, and these memory pointers don't really have to refer to actual physical RAM, and that is why we are using virtual memory.
- Virtual Memory is used by the Linux kernel to allow programs to make a memory reservation.
- After making this reservation, no other application can reserve the same memory.
- Making the reservation is a matter of setting pointers and nothing else. It doesn’t mean that the memory reservation is also actually going to be used.
- When a program has to use the memory it has reserved, it is going to
issue a
mallocsystem call, which means that the memory is actually going to be allocated. At that moment, we’re talking about resident memory.
What is memory over-allocation (over-commitment) and OOM?
- In top command command we can see the virt column and the res column.
- The
VIRTis for Virtual Memory. That's the amount of kilobytes that currently the process has allocated. - And
RESis for Resident, that is what it is really using. - I have sorted the output to show processes with most memory consumption.
I have written another article with the difference between RES and VIRT and also proper ways to check the memory utilisation of individual process.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2317 postgres 20 0 280800 41440 40336 S 0.0 0.0 0:13.47 postgres
6250 dbmrun 20 0 22.4g 4.8g 24208 S 5.6 3.8 167:11.36 java
3394 postgres 20 0 280908 24680 23512 S 0.0 0.0 0:10.72 postgres
5350 ne3suser 20 0 7230864 633448 18368 S 0.0 0.5 9:04.33 jsvc
950 root 20 0 56612 15884 15504 S 0.0 0.0 0:33.89 systemd-journal
2462 ssrun 20 0 7386468 570392 14964 S 0.3 0.4 7:34.72 jsvc
2421 ne3suser 20 0 9786720 455580 14732 S 0.3 0.3 22:02.68 jsvc
3559 ssrun 20 0 34.9g 4.0g 14280 S 0.3 3.2 19:22.59 jsvc
- We can see in the
VIRTsection that huge amount of memory is allocated to the process such as for java 22.4GB of virtual memory is allocated while only 4.8GB is used - If you add all of these
VIRTmemory to one another, you are getting far beyond the total of 128GB of physical RAM that is available in this system. - That is what we call memory over-allocation.
- To tune the behavior of over committing memory, you can write to
the
/proc/sys/vm/overcommit_memoryparameter. This parameter can have some values. - The default value is0, which means that the kernel checks if it still has memory available before granting it. If that doesn’t give you the performance you need,
- The value 1, means that the system thinks there is enough memory in all cases. This is good for performance of memory-intensive tasks but may result in processes getting killed automatically.
- The value of 2, means that the kernel fails the memory request if there is not enough memory available.
Let us understand in layman's terms
- This means that when any application or process requests for memory, kernel will always honour that request and "give".
- Please NOTE, that kernel gives certain amount of memory but this memory is not marked as "used".
- Instead this is considered as "virtual memory" and only when the application or process tries to write some data into the memory, kernel will mark that section of memory as "used".
- So if suddenly one or some process would start using more resident memory (RES), the kernel needs to honour that request, and the result is that you can reach a situation where there is no more memory available.
- That is called OOM (Out Of Memory) situation when your system is running low on memory, and it is getting out of memory
- In such case the out of memory killer becomes active, and it will kill the process that least requires to have the memory, and that is kind of a random situation, so you'll get a random process killed if your system is running out of memory.
Read More: Kernel Documentation to configure memory over commitment with sysctl and man page of proc (overcommit_memory)
Understanding and Monitoring Page Cache
Above we learned about Virtual Memory and how this is important for the working of Linux environment. Another item that is quite important is the Page Cache.
Buffers vs Page cache
- RAM that is NOT used to store application data is available for buffers and page cache. So, basically, page cache and buffer are anything in RAM that's not used for anything else.
- When your system wants to do anything with data, which are written on a hard-disk, it firstly needs to read the data from the disk and store them in RAM. The memory allocated for these data is calledpagecache.
- A cache is the part of the memory which transparently stores data so that future requests for that data can be served faster. This memory is utilized by the kernel to cache disk data and improve I/O performance.
- When any kind of file/data is requested then the kernel will look for a copy of the part of the file the user is acting on, and, if no such copy exists, it will allocate one new page of cache memory and fill it with the appropriate contents read out from the disk.
- Caches are considered as system memory and they are reported as freeablebecause they can be easily shrunk or reclaimed as a system's workload demands.
- Buffers are the disk block representation of the data that is stored under the page caches.
- Buffers contains the metadata of the files/data which resides under the page cache.
Let us take an example to
understand this clearly:
When there is a request of any data which is present in the page
cache, first the kernel checks the data in the buffers which
contain the metadata which
points to the actual files/data contained in the page caches.
Once from the metadata the actual block address of the file is known, it
is picked up by the kernel for processing.
Read more: What is difference between page cache and buffer?
How does kernel perform disk read write operation?
We discussed this topic briefly in the starting of this article using a diagram for Linux memory management, now we will follow the flow of disk read and write operations with page cache between user (kernel) ⇔ memory ⇔ disk
Reading from disk:
- In most cases, the kernel refers to the page cache when reading from or writing to disk.
- New pages are added to the page cache to satisfy User Mode processes's read requests.
- If the page is not already in the cache, a new entry is added to the cache and filled with the data read from the disk.
- If there is enough free memory, the page is kept in the cache for an indefinite period of time and can then be reused by other processes without accessing the disk.
Writing to disk:
- Similarly, before writing a page of data to a block device, the kernel verifies whether the corresponding page is already included in the cache;
- If not, a new entry is added to the cache and filled with the data to be written on disk.
- The I/O data transfer does not start immediately: the disk update is delayed for a few seconds, thus giving a chance to the processes to further modify the data to be written (in other words, the kernel implements deferred write operations).
Read More:Understanding the Linux Kernel
Kernel read and write operations operate on main memory. Whenever any read or write operation is performed, the kernel first needs to copy the required data into memory:
Read operation:
- go to disk and search for data
- write the data from disk into memory
- perform read operation
Write Operation:
- go to disk and search for data
- write the data from disk into memory
- perform write operation
- copy the modified data back to disk
Read More:What is cache in "free -m" output and why is memory utilization high for cache?
What is the advantage of keeping page cache?
In other words we can also frame this question as, why we should not clear the buffers and page cache so frequently?
To demonstrate this in Linux memory management, we will take a very simple example: I will create a small file with some random text:
[root@centos-8 ~]# echo "Understanding Linux memory management" > my_file
Next we will synchronize cached writes to persistent storage
[root@centos-8 ~]# sync
Next we will clear the buffers and cache.
WARNING: This will clear all the existing buffers and cache from your
Linux system so you must use this cautiously and should be avoided on
production environment, especially with heavy I/O Operations
[root@centos-8 ~]# echo 3 > /proc/sys/vm/drop_caches
Now since the caches are clear, we see that it takes around 0.031 seconds to read the file from the disk
[root@centos-8 ~]# time cat my_file
Understanding Linux memory management
real 0m0.031s
user 0m0.000s
sys 0m0.003s
Now since we have read the file once, it will also be available in our page cache so if we try to read the same file again, it should be picked from the page cache.
[root@centos-8 ~]# time cat my_file
Understanding Linux memory management
real 0m0.001s
user 0m0.000s
sys 0m0.001s
As you see now the read time is hardly 0.001 second which is much faster compared to our earlier result.
Understanding Dirty Page
As we know, the kernel keeps filling the page cache with pages
containing data of block devices. So whenever a process modifies some
data, the corresponding page is marked as dirty -that is, its
PG_dirty flag is set.The dirty writeback thresholds based on
dirty_ratio and dirty_background_ratio parameters also take HugePages into
account.The final threshold is calculated as a percentage ofdirty-able
memory(memory which can be potentially allocated for pagecache and get
ditried).
A dirty page might stay in main memory until the last possible moment - that is, until system shutdown. However, pushing the delayed-write strategy to its limits has two major drawbacks:
- If a hardware or power supply failure occurs, the contents of RAM can no longer be retrieved, so many file updates that were made since the system was booted are lost.
- The size of the page cache, and hence of the RAM required to contain it, would have to be huge - at least as big as the size of the accessed block devices.
Therefore, dirty pages are flushed (written) to disk also known as dirty writebackunder the following conditions:
- The page cache gets too full and more pages are needed, or the number of dirty pages becomes too large.
- Too much time has elapsed since a page has stayed dirty.
How dirty pages are flushed or written back to disk?
There are several parameters with sysctl which control when and how this disk writeback is performed.
Most significant are:
- dirty_bytes / dirty_ratio
- dirty_background_bytes / dirty_background_ratio
- dirty_writeback_centisecs
- dirty_expire_centisecs
/proc/sys/vm/. The kernel uses only one of the
respectiveratio/bytesparameters, the other is set to 0.
The writeback can be generally divided into 3 stages
First Stage: Periodic
- The kernel threads responsible for flushing dirty data are
periodically woken (period based on
dirty_writeback_centisecs) to flush data, which are dirty for at least or longer thandirty_expire_centisecs.
Second Stage: Background
- Once there is enough dirty data to cross threshold based on
dirty_background_*parameters, the kernel will try to flush as much as possible or at least enough to get under the background threshold. - Note that this is done asynchronously in kernelflusherthreads and while creating some overhead, it doesn't necessarily impact other application's workflow. (hence the name:background)
Third Stage: Active
- If the threshold based on
dirty_*parameters (usually reasonably higher thanbackgroundthreshold) is crossed, it means that applications are producing more dirty data faster than the flusher threads manage to writeback in time. - In order to prevent running out of memory, the tasks which produce
dirty data are blocked in the
write()system-call (and similar),actively waitingfor the data to be flushed.
Read More: Kernel Documentation
Understanding Translation Lookaside Buffers (TLB)
- When accessing memory pages, the TLB is used to find where these pages as referred to in virtual memory reside.
- They can be in physical memory. If they are already in physical memory, we call it a TLB hit, and the page can be served pretty fast.
- In case of a TLB miss, a page walk is issued to find where the memory page is, and it is loaded. This is also referred to as a minor page fault.
- A major page fault is something different. That occurs if a memory page needs to be fetched from swap.
- The TLB contains administration for all memory pages, and for that reason can grow rather big.
- The entire TLB by itself is in RAM, and the most frequently used pieces can be stored in CPU cache to speed up the process of allocating the correct memory pages.
Read More:Memory Allocation and Demand Paging
Understanding Active and Inactive Memory
- Active memory is memory that is really being used for something, and inactive memory is memory that's just sitting there and not being used for something.
- The essence of the difference between the two of them is in case there is a memory shortage, the Linux kernel can do something with the inactive memory.
- You can easily monitor the difference between the two of them through
/proc/meminfo. Here we can see six lines referring to active and inactive memory.
# grep -i active /proc/meminfo
Active: 13486424 kB
Inactive: 480856 kB
Active(anon): 11579352 kB
Inactive(anon): 88424 kB
Active(file): 1907072 kB
Inactive(file): 392432 kB
- Here we have a total of 12GB Active Memory, 450MB of Inactive Memory
- The
/proc/meminfoalso makes a difference between Active Anonymous and Active File Memory. - Anon (anonymous) memory refers to memory that is allocated by programs.
- Anonymous File memory refers to memory that is used as cache or buffers.
- On any Linux system, these two kinds of memory can be flagged as Active or Inactive. Inactive file memory typically exists on a server that doesn’t need the RAM for anything else.
- If memory pressure arises, the kernel can clear this memory immediately to make more RAM available.
- Inactive Anon Memory is memory that has to be allocated. However, as it hasn’t been used actively, it can be moved to a slower kind of memory. That exactly is what swap is used for.
- If in swap there’s only inactive anon memory, swap helps optimizing the memory performance of a system.
- By moving out these inactive memory pages, more memory becomes available for caching, which is good for the overall performance of a server.
- Hence, if a Linux server shows some activity in swap, that is not a bad sign at all.
Different types of swapping scenarios and risks
- If swap space is used, you should also have a look at the
/proc/meminfofile, to relate the use of swap to the amount of inactive anon memory pages. - If the amount of swap that is used is larger than the amount of anon
memory pages that you observe in
/proc/meminfo, it means that active memory is being swapped. That is bad news for performance, and if that happens, you must install more RAM. - If the amount of swap that is in use is smaller than the amount of
inactive anon memory pages in
/proc/meminfo, there’s no problem, and you’re good. - If, however, you have more memory in swap than the amount of inactive anonymous pages, you’re probably in trouble, because active memory is being swapped. That means that there’s too much I/O traffic, which will slow down your system.
Read More: What is swappiness and how do we change its value?
Conclusion
Lastly I hope the this article on Linux memory management and understanding it's terminologies was helpful. In this tutorial guide we learned about different areas of Memory used by Linux kernel to enhance and optimize system performance. This is not a complete guide of Linux memory Management but this will help you kickoff and know the basics of Linux memory. So, let me know your suggestions and feedback using the comment section.
If you run workloads in Docker or Kubernetes, the same virtual-memory ideas apply, but hard caps and many “memory used” metrics come from cgroups, not from a smaller fake machine. For how limits map to memory.max / memory.stat, why kubectl top or docker stats can disagree with process RSS, and how to triage OOMKilled, read Linux memory limits in containers (cgroups, Docker, and Kubernetes).
References
I have used below external references for this tutorial guide:
Understanding
dirty pagecache in sysctl
The Definitive Guide to SUSE
Linux Enterprise Server 12
