![Different Types of Machine Learning Explained [Beginners Guide]](/types-of-machine-learning/machine_learning_types.jpg)
Introduction to different types of machine learning
Machine Learning is the subfield of Artificial Intelligence where machines/computers learn from their past experiences and improve their skills with the passage of time and experience. In this article, we are going to discuss the main types of Machine Learning. Although there are many types of Machine Learning, here will try to cover only four main types.
We will briefly talk about Supervised, Unsupervised, Semi-supervised, and Reinforcement Machine Learning. Moreover, we will take various examples of each of these types. In a nutshell, this tutorial will contain all the necessary details about the types of machine learning.
Getting started with different types of machine learning
Machine Learning being the subset of Artificial Intelligence is about making intelligent computers/machines in a way that they can learn from their experiences. Mostly in Machine Learning, we are training the computers using data and later we test them by giving them data. computers/machines can be trained in different ways.
For instance, in one way we are training our computer by feeding some data, and later we are tested by giving data. We are showing different types of apples to a young lad and telling him that these are apples and when the lad is trained enough then we are testing him/her by showing various apples so that he/she can recognize them.
In other ways, we are not training our computer instead we are letting the computer learn by itself and later we are testing it by feeding some data. In this way, Machine Learning is divided into many subparts. The following diagrams show the sub-categories of machine learning.
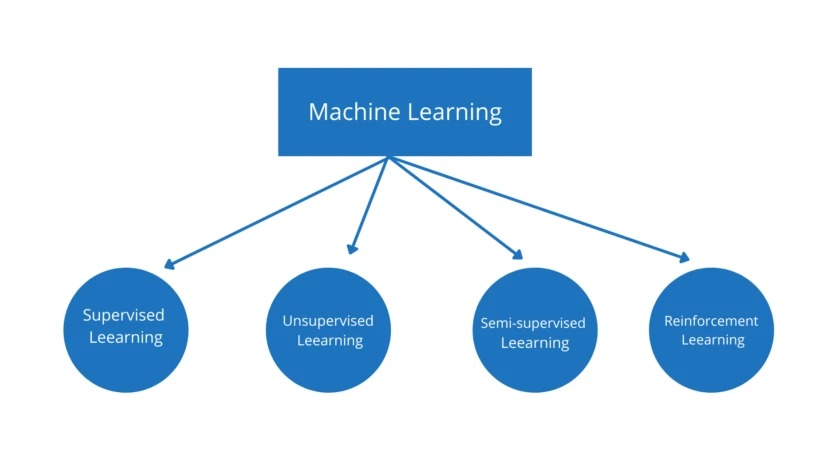
Now let us discuss briefly each of these categories of machine learning.
1. Supervised Machine Learning
Dictionary meaning of supervised is to observe and direct the execution of a task. Supervised means working under the supervision of someone or something. In Supervised Machine Learning, a machine/computer is working under the supervision of something.
The computer/machine is first trained by providing labelled data and then the machine is let to predict the results. Supervised machine learning algorithms are designed to learn by examples. The name “supervised” learning originates from the idea that training this type of algorithm is like having a teacher supervise the whole process.
When training a supervised learning algorithm, the training data will consist of inputs paired with the correct outputs. During training, the algorithm will search for patterns in the data that correlate with the desired outputs. After training, a supervised learning algorithm will take in new unseen inputs and will determine which label the new inputs will be classified as based on prior training data.
The objective of a supervised learning model is to predict the correct label for newly presented input data. At its most basic form, a supervised learning algorithm can be written simply as:
Y = f(x)
Where <i>Y </i>is the predicted output that is determined by a mapping
function that assigns a class to an input value <i>x</i>. The function
used to connect input features to a predicted output is created by the
machine learning model during training.
Basically supervised learning is when we teach or train the machine using data that is well labeled. Which means some data is already tagged with the correct answer. After that, the machine is provided with a new set of examples(data) so that the supervised learning algorithm analyses the training data(set of training examples) and produces a correct outcome from labeled data.
1.1 How does supervised machine learning work?
As we have already discussed that Supervised Machine Learning uses the training data to train the model. See the diagram below which shows how supervised machine learning works.
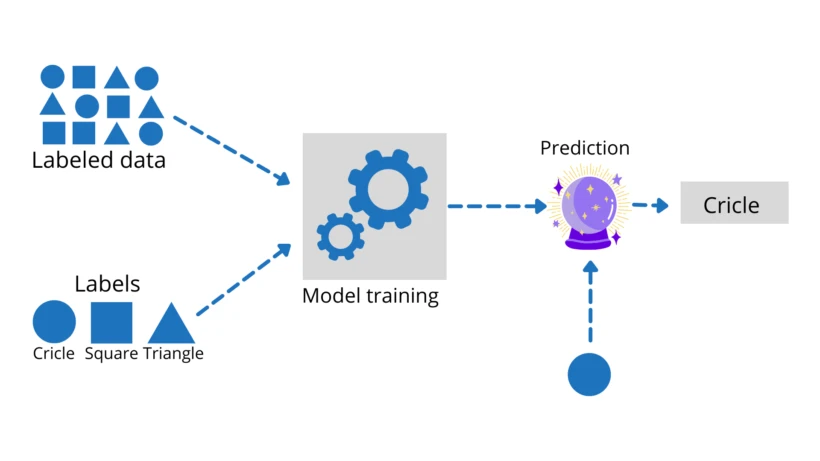
In the above figure, we can see that first, we have a collection of items like squares, circles, triangles, etc. We are providing those figures to our machine and telling their names in the label part. When we provide our machine with the names of all the figures then it remembers their names and trains itself for the test. After training the machine, we are providing testing data.
In the above figure, we can see that we have given one circle as testing data. After the prediction. Based on the training data, our machine predicts the input and gives any of the labels as an output or the predicted value. In the above case, it is a circle.
1.2 Types of Supervised machine learning
There are two basic sorts of Supervised Machine Learning: Classification and Regression.
Classification problems, the machine classifies or categories are given input data. The job of a classification algorithm is to then take an input value and assign it a class, or category, that it fits into based on the training data provided. The most common example of classification is determining if an email is spam or not. With two classes to choose from (spam, or not spam), this problem is called a binary classification problem.
Regression is a predictive statistical process where the model attempts to find the important relationship between dependent and independent variables. The goal of a regression algorithm is to predict a continuous number such as sales, income, and test scores.
2. Unsupervised Machine Learning
The dictionary meaning of unsupervised is not done or acting under supervision. Unlike supervised learning, Unsupervised Machine Learning infers from unlabeled data, a function that describes hidden structures in data. It uses machine learning algorithms to analyze and cluster unlabeled datasets. These algorithms discover hidden patterns or data groupings without the need for human intervention. Its ability to discover similarities and differences in information makes it the ideal solution for exploratory data analysis, cross-selling strategies, customer segmentation, and image recognition. Unsupervised learning cannot be directly applied to a regression or classification problem because, unlike supervised learning, we have the input data but no corresponding output data. The goal of unsupervised learning is to find the underlying structure of the dataset, group that data according to similarities, and represent that dataset in a compressed format.
2.1 How does unsupervised machine learning work?
As we already discussed that the machine takes the input data without any output and based on similarities, it divides that data and provides the output. See the following diagram, which shows the working of unsupervised machine learning.
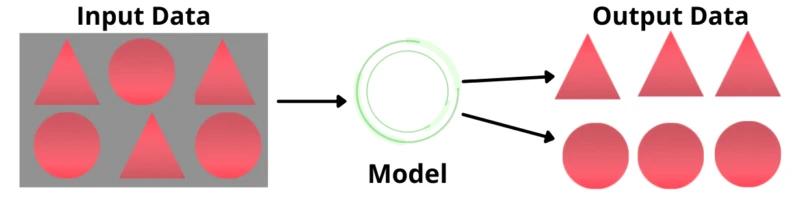
In the above figure, we are not giving the labeled data to the machine. We are providing some data and letting the machine identify. We have some input data which consists of some triangles and some circles. The machine applies Unsupervised Machine Learning techniques and identities all the triangles and circles based on their similar features.
2.2 Types of unsupervised machine learning
There are two types of Unsupervised Machine Learning: Clustering and Association.
Clustering: Clustering is a method of grouping the objects into clusters such that objects with the most similarities remain in a group and have fewer or no similarities with the objects of another group. Cluster analysis finds the commonalities between the data objects and categorizes them as per the presence and absence of those commonalities.
Association: An association rule is an unsupervised learning method that is used for finding the relationships between variables in a large database. It determines the set of items that occur together in the dataset. Association rule makes marketing strategy more effective. Such as people who buy X items (suppose bread) are also tend to purchase Y (Butter/Jam) items. A typical example of the Association rule is Market Basket Analysis.
3. Reinforcement machine learning
Reinforcement Learning is a feedback-based Machine learning technique in which an agent learns to behave in an environment by performing the actions and seeing the results of actions. For each good action, the agent gets positive feedback, and for each bad action, the agent gets negative feedback or a penalty. Here the agent learns automatically using feedback without any labeled data, unlike Supervised Machine Learning. Since there is no labeled data, so the agent is bound to learn by its experience only. The agent interacts with the environment and explores it by itself. The primary goal of an agent in reinforcement learning is to improve performance by getting the maximum positive rewards. The agent learns with the process of hit and trial, and based on the experience, it learns to perform the task in a better way.
3.1 How does reinforcement machine learning work?
As we have already discussed that the reinforcement machine learning is based on the reward and punishment principle. See the diagram below which explains the working of reinforcement machine learning.
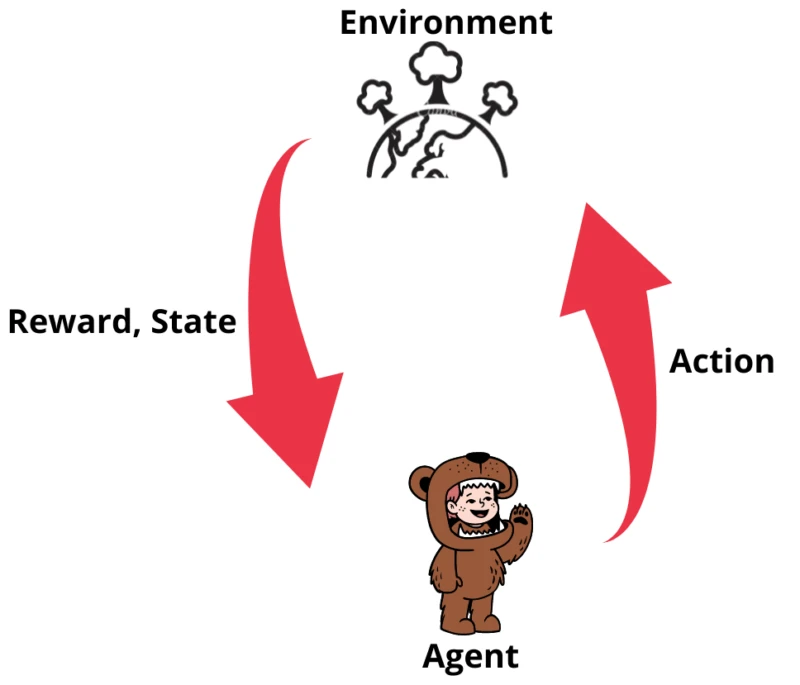
The agent learns what actions lead to positive feedback or rewards and what actions lead to negative feedback penalties. As a positive reward, the agent gets a positive point, and as a penalty, it gets a negative point.
4. Semi-supervised Machine Learning
Semi-Supervised Machine Learning uses a small amount of labeled data and a large amount of unlabeled data, which provides the benefits of both supervised and unsupervised machine learning while avoiding the challenges of finding a large amount of labeled data. Semi-supervised machine learning is a combination of supervised and unsupervised learning. It uses a small amount of labeled data and a large amount of unlabeled data, which provides the benefits of both unsupervised and supervised learning while avoiding the challenges of finding a large amount of labeled data. That means you can train a model to label data without having to use as much labeled training data.
4.1 How does semi-supervised machine learning work?
Semi-supervised learning is an approach to machine learning that combines a small amount of labeled data with a large amount of unlabeled data during training. Unlabeled data, when used in conjunction with a small amount of labeled data, can produce considerable improvement in learning accuracy. See the following diagram.

Summary
In this article, we have briefly discussed the types of Machine Learning. We have talked about Supervised Machine Learning, its types and we have given examples and demonstrated how it works. We have also briefly discussed Unsupervised Machine Learning, its types, and how it works. We have demonstrated its working using a diagram which makes it more clear.
In our tutorial, we also covered Reinforcement Machine Learning and we have also mentioned its working and demonstrated using a simple model which makes it easy to understand. In the last part of this article, we learned about Semi-Supervised Machine Learning. Moreover, we have briefly mentioned its working and demonstrated using a simple model. In a nutshell, this tutorial discussed four different types of machine learning.
Further Reading
Machine Learning in azure
AWS machine learning
Machine learning modules

![Simple Linear Regression Using Python Explained [Tutorial]](/simple-linear-regression-using-python/linear_regression_hu_327cf0bd56814cc9.webp)
![Supervised Learning Algorithms Explained [Beginners Guide]](/supervised-learning-algorithms/supervisord_lerarning_algo_hu_386069bc51a3ccd4.webp)



![FIX: No such file or directory in Python [6 Reasons]](/no-such-file-or-directory-in-python/python-no-such-file-or-directory_hu_26f7c1a713400433.webp)

