
This is a multi-part article where in a series of article we will learn about Gluster File System in Linux, below are the topics we will cover:
- What is GlusterFS?
- Types of Volumes supported with GlusterFS
- Install and Configure GlusterFS Distributed Volume with RHEL/CentOS 8
- Install and Configure GlusterFS Replicated Volume with RHEL/CentOS 8
- Install and Configure GlusterFS Distributed Replicated Volume with RHEL/CentOS 8
What is GlusterFS
- Gluster is a distributed scale-out filesystem that allows rapid provisioning of additional storage based on your storage consumption needs.
- It incorporates automatic failover as a primary feature. All of this is accomplished without a centralized metadata server.
- The GlusterFS software is available as precompiled packages for several Linux distros, but as with most Free and Open Source Software (FOSS) projects, you can always download the source code, compile, and build it yourself.
- The GlusterFS network filesystem is a “no metadata” distributed filesystem, which means that it does not have a dedicated metadata server that is used to handle file location data. Instead, it uses a deterministic hashing technique to discover the file location
- GlusterFS exports a fully POSIX-compliant filesystem, which basically means you can mount, read, and write to GlusterFS from Unix and Unix-like operating systems (such as Linux).
- You can access GlusterFS storage using traditional NFS, SMB/CIFS for Windows clients, or native GlusterFS clients
- GlusterFS is a user space filesystem , meaning it doesn’t run in the Linux kernel but makes use of the FUSE module.
Type of GlusterFS Volumes
There are several ways that data can be stored inside GlusterFS. These concepts are similar to those found in RAID. Files can be stored in Gluster volumes either with or without levels of redundancy depending on your configuration options.
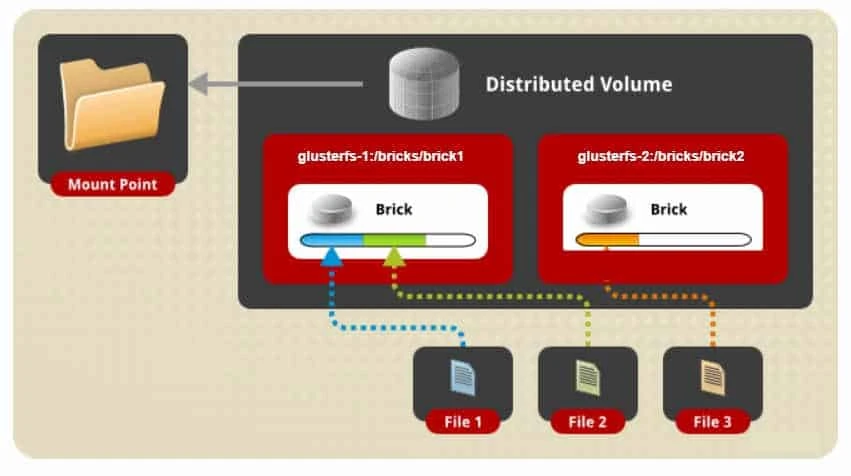
Distributed volume
- By default, if no distribution type is specified, GlusterFS creates a distributed volume .
- Here, files are distributed across various bricks in the volume. So, a file can be stored on any brick in the volume with no redundancy.
- The purpose for such a storage volume is to easily & cheaply scale the volume size.
- However this also means that a brick failure will lead to complete loss of data and one must rely on the underlying hardware for data loss protection.
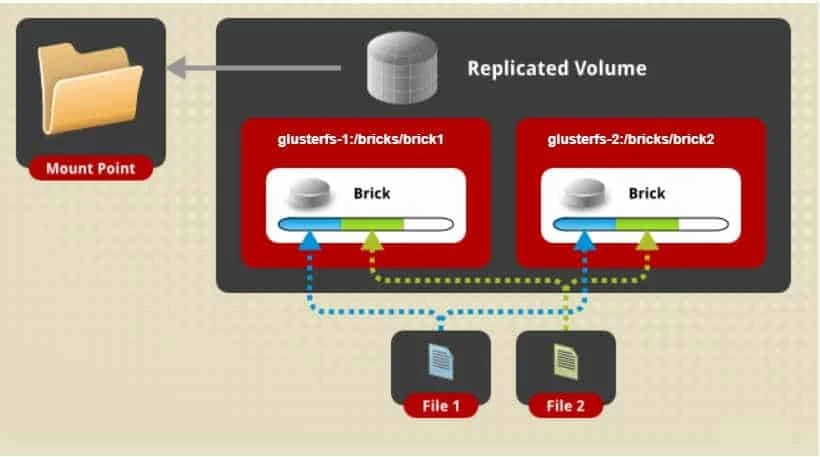
Replicated volume
- In a replicated volume setup, your files are replicated across all bricks in the volume. So we overcome the data loss problem faced in the distributed volume
- Here exact copies of the data are maintained on all bricks.
- The number of replicas in the volume can be decided by client while creating the volume.
- This requires a minimum of two bricks to create a volume with two replicas or a minimum of three bricks to create a volume of three replicas
- One major advantage of such a volume is that even if one brick fails the data can still be accessed from its replicated bricks.
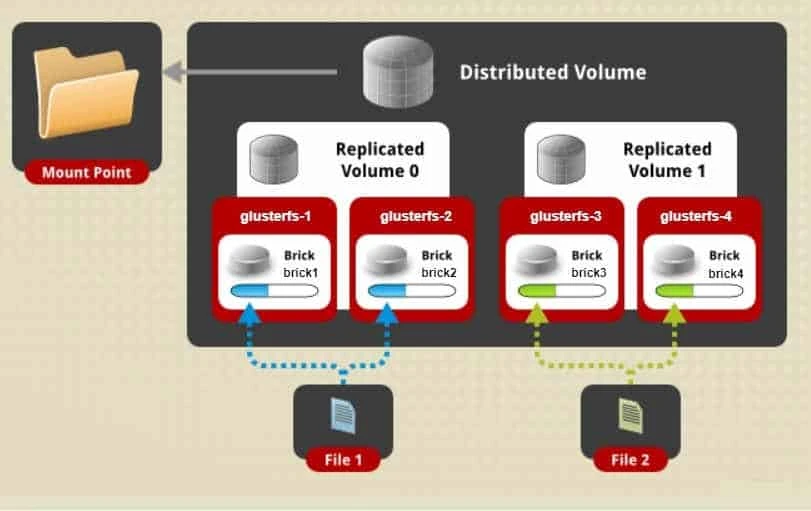
Distributed replicated volume
- Files in this configuration are stored across replicated sets of bricks.
- Here the number of bricks must be a multiple of the replica count.
- Also the order in which we specify the bricks matters since adjacent bricks become replicas of each other.
- This is a configuration for highly available file storage.
- So if there were eight bricks and replica count 2 then the first two bricks become replicas of each other then the next two and so on. This volume is denoted as 4x2.
- Similarly if there were eight bricks and replica count 4 then four bricks become replica of each other and we denote this volume as 2x4 volume.
Striped Volume and Distributed Striped Volume
Starting with GlusterFS version 6.0, stripe functionality was deprecated.
Stripe xlator, provided the ability to stripe data across bricks. This functionality was used to create and support files larger than a single brick and also to provide better disk utilization across large file IO, by spreading the IO blocks across bricks and hence physical disks.
This functionality is now provided by theshard xlator
To enable striping or sharding an existing volume you can enable features.shard, for example to enable striping on replicated_volume from my CentOS 8 node
Below are the list of volumes on my CentOS 8 node:
[root@glusterfs-1 ~]# gluster volume list
dis_rep_vol
replicated_volume
Enable striping or sharding on replicated volume
[root@glusterfs-1 ~]# gluster volume set replicated_volume features.shard enable
volume set: success
Start the volume (if not already started)
[root@glusterfs-1 ~]# gluster volume start replicated_volume
Check the info of the volume as highlighted
[root@glusterfs-1 ~]# gluster volume info replicated_volume
Volume Name: replicated_volume
Type: Replicate
Volume ID: a9740dad-0102-4131-8a08-74f3b2ec6103
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 3 = 3
Transport-type: tcp
Bricks:
Brick1: glusterfs-1:/bricks/brick1/rep_vol
Brick2: glusterfs-2:/bricks/brick2/rep_vol
Brick3: glusterfs-3:/bricks/brick3/rep_vol
Options Reconfigured:
features.shard: enable
performance.client-io-threads: off
nfs.disable: on
storage.fips-mode-rchecksum: on
transport.address-family: inet
Gluster File System Terminologies
Several concepts and terms are used in association with DFS:
peer
- A trusted pool is a network of servers operating in the GlusterFS cluster. Each server is called a peer.
- The peer commands are used to manage the Trusted Server Pool (TSP).
Brick
- A brick is a basic unit of storage for the GlusterFS. It is exported a server in the trusted pool.
- A volume is a logical collection of bricks.
- In DFS, a physical server/system whose local storage resource is contributing to the overall storage capacity of the DFS is often referred to as a “brick.”
- Clients or hosts access the file system resources stored collectively on bricks and need not know that they are accessing the data on one or multiple bricks.
Metadata
- Refers to all the other characteristics of data (or a file) except the actual data itself.
- This can include the file size, the file permissions, timestamps, filename, and other attributes that can be used to describe the file.
Fault tolerance
- This is a characteristic or feature that a DFS may or may not provide.
- It allows transparent and continued access to the shared resource of the DFS in the event of a failure.
Replication
- Replication is the process of duplication of the contents of one file system onto another location.
- It is used for ensuring consistency and fault tolerance, and for improving accessibility to data.
- Replication can happen in one of two ways: synchronously or asynchronously.
- Synchronous replication can slow things down a bit, because it requires that certain file operations (read, write, and so on) that occur on one of the servers need to be performed concurrently/completely on other servers in order to be deemed successful.
- Asynchronous replication, on the other hand, is better suited for use on slow connections, because file system operations can happen on a server and be deemed successful while the other servers in the setup sort of catch up later on.
Where can we use GlusterFS?
GlusterFS is distributed by nature and is quite different. Some of the solution where we can use GlusterFS solution with
- Kubernetes Containerization
- Proxmox Cluster: For a lower-budget virtual environment with redundancy requirements, Gluster can be an excellent option. In a two-node Gluster setup, both the nodes sync with each other and when one node becomes unavailable, the other node simply takes over.
- Create clustered Raspberry Pis to create a highly available distributed filesystem.
- You can also use GlusterFS as distributed filesystem for hadoop
Related Searches: What is glusterfs. Gluster File System. Gluster Shared Storage. Glusterfs Replication Types
