
Earlier I had shared an article with the steps toconfigure ceph storage cluster in OpenStack. Now let me give you some brief
overview on the nova compute architecture and how all the services
within nova compute communicate with each other. What is the role of
each service under nova compute? What is the role of nova-api,
nova-scheduler, nova-console, nova-conductor, nova-console-auth,
nova-compute service in OpenStack?

Understanding nova compute architecture (Flow Chart)
The compute service consists of various services and daemons including
the nova-api service, which accepts the API requests and forwards them
to the other components of the service.
The following diagram shows how various processes and daemons work together to form the compute service (Nova) and interlink between them:
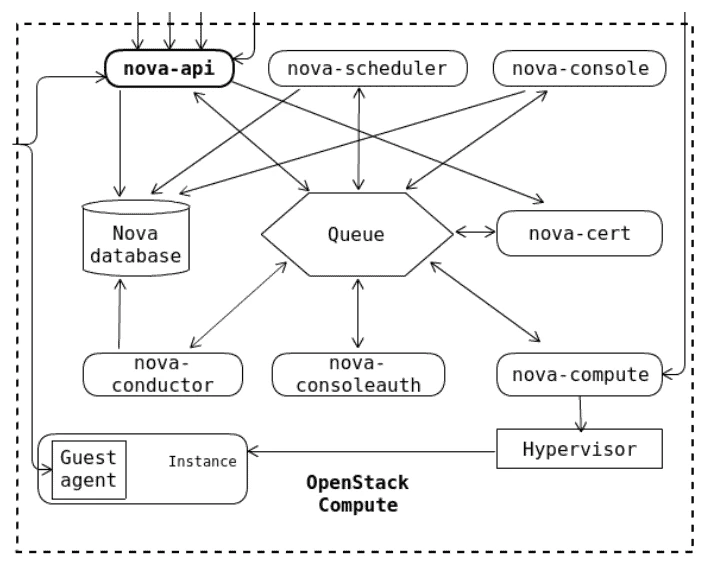
Understanding nova compute services
Below are the list of services which are part of nova compute service:
nova-api service
- All services in OpenStack have at least one API process that accepts and responds to end user API calls, pre-processes them, and passes the request to the appropriate process within the service.
- For the OpenStack compute service, we have the
nova-apiservice, which listens and responds to the end user compute API calls. Thenova-apiservice takes care of initiating most orchestration activities, such as provisioning new virtual machines.
nova-api-metadata service
- The metadata service delivers the instance-specific data to the
virtual machine instances. The instance-specific data includes
hostname, instance-id, ssh-keys, and so on. The virtual machine accesses the metadata service via the special IP address athttp://169.254.169.254.
nova-compute service
- Underneath, the entire lifecycle of the virtual machine is managed by
the hypervisors. Whenever the end user submits the instance creation
API call to the
nova-apiservice, thenova-apiservice processes it and passes the request to thenova-computeservice. The nova-compute service processes thenova-apicall for new instance creation and triggers the appropriate API request for virtual machine creation in a way that the underlying hypervisor can understand. - For example, if we choose to use the KVM hypervisor in the OpenStack
setup, when the end user submits the virtual machine creation request
via the OpenStack dashboard, the
nova-apicalls will get sent to thenova-apiservice. Thenova-apiservice will pass the APIs for instance creation to thenova-computeservice. Thenova-computeservice knows what API the underlying KVM hypervisor will support. Now, pointing to the underlying KVM hypervisor, the nova-compute will trigger thelibvirt-apifor virtual machine creation. Then, the KVM hypervisor processes thelibvirt-apirequest and creates a new virtual machine. - OpenStack has the flexibility to use multi-hypervisor environments in the same setup, that is, we could configure different hypervisors like KVM and VMware in the same OpenStack setup. The nova-compute service will take care of triggering the suitable APIs for the hypervisors to manage the virtual machine lifecycle.
nova-scheduler service
- When we have more than one compute node in your OpenStack environment,
the
nova-schedulerservice will take care of determining where the new virtual machine will provision. Based on the various resource filters, such as RAM/CPU/Disk/Availability Zone, the nova-scheduler will filter the suitable compute host for the new instance:

nova-conductor module
- The nova-compute service running on the compute host has no direct
access to the database because if one of your compute nodes is
compromised, then the attacker has (almost) full access to the
database. With the
nova-conductordaemon, the compromised node cannot access the database directly, and all the communication can only go through the nova-conductor daemon. So, the compromised node is now limited to the extent that the conductor APIs allow it. - The
nova-conductormodule should not be deployed on any compute nodes, or else the purpose of removing direct database access for thenova-computewill become invalid.
nova-consoleauth daemon
The nova-consoleauth daemon takes care of authorizing the tokens for
the end users, to access a remote console of the guest virtual machines
provided by the following control proxies:
- The
nova-novncproxydaemon provides a proxy for accessing running instances through a VNC connection. - The
nova-spicehtml5proxydaemon provides a proxy through a SPICE connection
nova-cert module
- Used to generate X509 certificates for euca-bundle-image, and only needed for the EC2 API.
The queue (AMQP message broker)
- Usually, the AMQP message queue is implemented with RabbitMQ or ZeroMQ. In OpenStack, an AMQP message broker is used for all communication between the processes and daemons of one service. However, the communication between the two different services in OpenStack uses service endpoints.
- For example, the
nova-apiandnova-schedulerwill communicate through the AMQP message broker. However, the communication between thenova-apiservice andcinder-apiservice will carry through the service endpoints.
Database
- Most of the OpenStack services use an SQL database to store the build-time, and run-time states for a cloud infrastructure, such as instance status, networks, projects, and the list goes on. In short, we could say the database is the brain of OpenStack.
- The most tested and preferable databases to use in OpenStack are MySQL, MariaDB, and PostgreSQL.
Lastly I hope this article on understanding nova compute architecture on OpenStack was helpful. So, let me know your suggestions and feedback using the comment section.
References:
OpenStack Bootcamp
