
This is a multi part Elasticsearch Tutorial where we will cover all the related topics on ELK Stack using Elasticsearch 7.5
- Install and Configure ElasticSearh Cluster 7.5 with 3 Nodes
- Enable HTTPS and Configure SSS/TLS to secure Elasticsearch Cluster
- Install and Configure Kibana 7.5 with SSL/TLS for Elasticsearch Cluster
- Configure Metricbeat 7.5 to monitor Elasticsearch Cluster Setup over HTTPS
- Install and Configure Logstash 7.5 with Elasticsearch
Brief Overview on ELK Stack
Elastic Stack or ELK Stack components have a variety of practical use cases, and new use cases are emerging as more plugins are added to existing components. As mentioned earlier, you may use a subset of the components for your use case. The following list of example use cases is by no means exhaustive, but highlights some of the most common ones:
- Log and security analytics
- Product search
- Metrics analytics
- Web searches and website searches
Elasticsearch
Elasticsearch is a distributed and scalable data store from which Kibana will pull out all the aggregation results that are used in the visualization. It's resilient by nature and is designed to scale out, which means that nodes can be added to an Elasticsearch cluster depending on the needs, in a very simple way.
Elasticsearch is a highly available technology, which means the following:
- First, data is replicated across the cluster so that if there is a failure, then there is still at least one copy of the data
- Secondly, thanks to its distributed nature, Elasticsearch can spread the indexing and searching load over the various elasticsearch node types, to ensure service continuity and respect to your SLAs
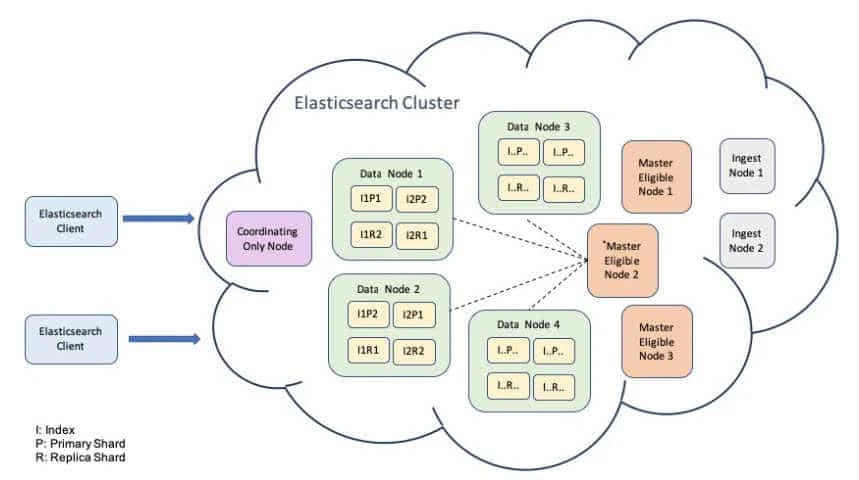
Credits: Advanced Elasticsearch 7.X Elasticsearch Cluster Architecture
We will discuss the different types of elasticsearch node types later in this article.
Elasticsearch common terms
The following are the most common terms that are very important to know before you configure elasticsearch cluster:
- Node: A single instance of Elasticsearch running on a machine.
- Cluster: A cluster is the single name under which one or more nodes/instances of Elasticsearch are connected to each other.
- Document: A document is a JSON object that contains the actual data in key value pairs.
- Index: A logical namespace under which Elasticsearch stores data, and may be built with more than one Lucene index using shards and replicas.
- Doc types: A doc type in Elasticsearch represents a class of similar documents. A type consists of a name, such as a user or a blog post, and a mapping, including data types and the Lucene configurations for each field. (An index can contain more than one type.)
- Shard: Shards are containers that can be stored on a single node or multiple nodes and are composed of Lucene segments. An index is divided into one or more shards to make the data distributable.
- Replica: A duplicate copy of the data living in a shard for high availability.
Lab Environment
I have installed Oracle VirtualBox on Linux Server where I have four virtual machines. All these VMs are running with 20GB disk, 8GB RAM and 4vCPU. Below are other details about these VMs
| Parameters | VM1 | VM2 | VM3 | VM4 |
|---|---|---|---|---|
| Hostname | server1 | server2 | server3 | centos-8 |
| FQDN | server1.example.com | server2.example.com | server3.example.com | centos-8.example.com |
| IP Address | 192.168.0.11 | 192.168.0.12 | 192.168.0.13 | 192.168.0.14 |
| Cluster Node type | master node | ingest node | data node | Kibana Logstash Filebeat |
| OS | CentOS 7.6 | CentOS 7.6 | CentOS 7.6 | CentOS 8 |
| Storage | 20 GB | 20 GB | 20 GB | 20 GB |
| RAM | 8 GB | 8 GB | 8 GB | 8 GB |
| vCPU | 4 | 4 | 4 | 4 |
Update hosts file
Update the hosts file on all the nodes of elasticsearch cluster setup. Alternatively you can also configure DNS Server to resolve hostname.
# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.0.11 server1 server1.example.com
192.168.0.12 server2 server2.example.com
192.168.0.13 server3 server3.example.com
192.168.0.14 centos-8 centos-8.example.com
Installing Java
Perform the steps from this chapter on all the nodes to configure elasticsearch cluster setup.In order to configure Elasticsearch Cluster, the first step is to make sure that a Java SE environment is installed properly. Elasticsearch requires Java Version 6 or later to run. You can download it from official Oracle distribution. Alternatively you can also use OpenJDK.
Since I am using CentOS environment I will install java using yum.
# yum -y install java-1.8.0-openjdk-devel.x86_64
I am using Java OpenJDK 1.8 for this article.
List installed packages with rpm -qa; the rpm command explains query filters and piping into grep.
# rpm -qa | grep openjdk
java-1.8.0-openjdk-devel-1.8.0.232.b09-0.el7_7.x86_64
java-1.8.0-openjdk-headless-1.8.0.232.b09-0.el7_7.x86_64
java-1.8.0-openjdk-1.8.0.232.b09-0.el7_7.x86_64
Verify the java version
# java -version
openjdk version "1.8.0_232"
OpenJDK Runtime Environment (build 1.8.0_232-b09)
OpenJDK 64-Bit Server VM (build 25.232-b09, mixed mode)
Install Elasticsearch
Perform the steps from this chapter on all the nodes to configure elasticsearch cluster setup. There are various ways to install elasticsearch, we will just download the elasticsearch rpm and install it manually.
After editing unit files, run systemctl daemon-reload before enable or restart; the systemctl command covers reload order and failed-unit checks.
[root@server3 ~]# rpm -ivh https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.5.1-x86_64.rpm
Retrieving https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.5.1-x86_64.rpm
warning: /var/tmp/rpm-tmp.RhUwqE: Header V4 RSA/SHA512 Signature, key ID d88e42b4: NOKEY
Preparing... ################################# [100%]
Creating elasticsearch group... OK
Creating elasticsearch user... OK
Updating / installing...
1:elasticsearch-0:7.5.1-1 ################################# [100%]
### NOT starting on installation, please execute the following statements to configure elasticsearch service to start automatically using systemd
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service
### You can start elasticsearch service by executing
sudo systemctl start elasticsearch.service
Created elasticsearch keystore in /etc/elasticsearch
During installation, a user and a group with the
elasticsearch name are created by default. Elasticsearch does not get
started automatically just after installation. It is prevented from an
automatic startup to avoid a connection to an already running node with
the same cluster name.
[root@server3 ~]# rpm -qa | grep elasticsearch
elasticsearch-7.5.1-1.x86_64
Configure Elasticsearch Cluster
Step by step tutorial to configure elasticsearch custer. Learn all about different types of elasticsearch node types with example. ELK Stack Elasticsearch tutorial. Get elasticsearch cluster health status. elasticsearch get cluster nodes
Since I only have three nodes to configure elasticsearch cluster, I will
use all the three nodes as master, data and ingest node. Although I will
disable other elasticsearch node types as those are not required in this
article. Open the elasticsearch.yml file, which contains most of the
Elasticsearch configuration options
The configuration file is in the YAML format and the following sections are some of the parameters that can be configured.
cluster.name
- cluster name should be the same for all the nodes in the cluster.
- A node can only join a cluster when it shares its cluster.name with all the other nodes in the cluster.
- Make sure that you don’t reuse the same cluster names in different environments, otherwise you might end up with nodes joining the wrong cluster.
- The colon (
:) is not a valid character for the cluster name anymore due to cross-cluster search support.
cluster.name: my-cluster
node.name
- Elasticsearch uses node.name as a human readable identifier for a particular instance of Elasticsearch so it is included in the response of many APIs.
- It defaults to the hostname that the machine has when Elasticsearch starts but can be configured explicitly in elasticsearch.yml
- Depending on your application needs, you can add and remove nodes (servers) on the fly.
- Adding and removing nodes is seamlessly handled by Elasticsearch.
node.name: server1
network.host
- Elasticsearch binds to the
localhostor127.0.0.1by default, which works great for development. - You can also bind Elasticsearch to
0.0.0.0. In the context of a server,0.0.0.0means all IPv4 addresses available. - For example, if a server has two IP addresses,
192.168.0.1and192.168.0.2, the Elasticsearch instance can be reached via both the IP addresses. When you bind to0.0.0.0, it is also accessible via127.0.0.1locally. - If you need more than one node in the cluster, you need to bind Elasticsearch to an external address so that other nodes in the cluster can communicate.
network.host: 192.168.0.11
discovery.seed_hosts (discovery.zen.ping.unicast.hosts)
- This setting was previously known as
discovery.zen.ping.unicast.hosts. - Provides a list of master-eligible nodes in the cluster.
- Each value has the format host:port or host, where port defaults to the setting transport.profiles.default.port.
discovery.seed_hosts: ["192.168.0.11", "192.168.0.12", "192.168.0.13"]
cluster.initial_master_nodes
- Starting an Elasticsearch cluster setup for the very first time requires the initial set of master-eligible nodes to be explicitly defined on one or more of the master-eligible nodes in the cluster. This is known as cluster bootstrapping.
- This is only required the first time a cluster starts up: nodes that have already joined a cluster store this information in their data folder for use in a full cluster restart, and freshly-started nodes that are joining a running cluster obtain this information from the cluster’s elected master.
- It is technically sufficient to set
cluster.initial_master_nodeson a single master-eligible node in the cluster, and only to mention that single node in the setting’s value, but this provides no fault tolerance before the cluster has fully formed.
cluster.initial_master_nodes: ["192.168.0.11", "192.168.0.12", "192.168.0.13"]
Different elasticsearch node types
There are different elasticsearch node types, you must also choose the respective node type for elasticsearch cluster setup
- master-eligible nodes: A Master node is responsible for cluster management, which includes index creation/deletion and keeping track of the nodes that are part of the cluster, which makes it eligible to be elected as the master node, which controls the cluster.
- data node: Data nodes contain the actual index data. They handle all the index and search operations on the documents
- ingest node: A node that has
node.ingestset to true (default). Ingest nodes are able to apply an ingest pipeline to a document in order to transform and enrich the document before indexing. - Tribe node: Tribe node can read and write to multiple clusters at a time
- machine learning node: A node that has xpack.ml.enabled and node.ml set to true, which is the default behavior in the Elasticsearch default distribution.
- co-ordinating nodes: Coordinating node is the node receiving a request. It sends the query to all the shards the query needs to be executed on, gathers the results, and sends them back to the client
- voting-only master-eligible nodes: A voting-only master-eligible node is a node that participates in master elections but which will not act as the cluster’s elected master node.
- voting-only node can serve as a tiebreaker in elections.
Sample elasticsearch configure file (elasticsearch.yml)
Below is my sample elasticsearch configuration
(/etc/elasticsearch/elasticsearch.yml) from my elasticsearch cluster
setup nodes
First cluster node - server1
[root@server1 ~]# sed '/^#/d' /etc/elasticsearch/elasticsearch.yml
cluster.name: my-cluster
node.name: server1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.0.11
discovery.seed_hosts: ["192.168.0.11", "192.168.0.12", "192.168.0.13"]
cluster.initial_master_nodes: ["192.168.0.11"]
node.master: true
node.voting_only: false
node.data: false
node.ingest: false
node.ml: false
xpack.ml.enabled: true
cluster.remote.connect: false
Second cluster node - server2
[root@server2 ~]# sed '/^#/d' /etc/elasticsearch/elasticsearch.yml
cluster.name: my-cluster
node.name: server2
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.0.12
discovery.seed_hosts: ["192.168.0.11", "192.168.0.12", "192.168.0.13"]
node.master: true
node.voting_only: false
node.data: true
node.ingest: true
node.ml: false
xpack.ml.enabled: true
cluster.remote.connect: false
Third cluster node - server3
[root@server3 ~]# sed '/^#/d' /etc/elasticsearch/elasticsearch.yml
cluster.name: my-cluster
node.name: server3
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.0.13
discovery.seed_hosts: ["192.168.0.11", "192.168.0.12", "192.168.0.13"]
node.master: true
node.voting_only: false
node.data: true
node.ingest: true
node.ml: false
xpack.ml.enabled: true
cluster.remote.connect: false
Configure Firewall
Elasticsearch will start on two ports, as follows:
- 9200: This is used to create HTTP connections
- 9300: This is used to create a TCP connection through a JAVA client and the node's interconnection inside a cluster
Open the listener port with firewall-cmd --add-port and reload; the firewalld shows --permanent pairs and zone selection.
# firewall-cmd --add-port={9200,9300-9400}/tcp --permanent
success
# firewall-cmd --reload
success
Start Elasticsearch Service
With RHEL/CentOS 7 and 8 we have systemd based services by default instead of SysV. So we will use systemctl to restart elasticsearch service
To start the elasticsearch service
# systemctl start elasticsearch
Also enable the service to auto start post reboot
# systemctl enable elasticsearch
Created symlink from /etc/systemd/system/multi-user.target.wants/elasticsearch.service to /usr/lib/systemd/system/elasticsearch.service.
Check elasticsearch cluster status
Learn about elasticsearch cluster node types with examples. Steps to configure elasticsearch cluster in RHEL/CentOS 7 and 8 Linux. With elasticsearch 7 now discovery.zen.ping.unicast.hosts is replaced by discovery.seed_hosts. Elasticsearch tutorial. ELK Stack Overview
Once you start the elasticsearch service on all the master nodes, check the elasticsearch cluster status for the respective IP/hostname.
Use curl to verify the endpoint before continuing — the curl command covers status codes, headers, and timing options.
[root@server1 ~]# curl -XGET server1:9200
{
"name" : "server1",
"cluster_name" : "my-cluster",
"cluster_uuid" : "J1gcH5S6S52VAq7iJtQDqg",
"version" : {
"number" : "7.5.1",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "3ae9ac9a93c95bd0cdc054951cf95d88e1e18d96",
"build_date" : "2019-12-16T22:57:37.835892Z",
"build_snapshot" : false,
"lucene_version" : "8.3.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
_na_ here, then it means that elasticsearch
failed to form cluster. The elasticsearch log files would be available
under the location defined by path.logs in elasticsearch.yml. For
example here in my elasticsearch cluster setup the log files would be
generated in /var/log/elasticsearch/my-cluster.log where
"my-cluster" is the name of my elasticsearch cluster setup.
If the cluster uuid is properly generated, proceed with the start of other elasticsearch service on other cluster data nodes.
Next check the elasticsearch cluster status on data nodes using respective server ip or hostname using the below API request
# curl -XGET server1:9200
# curl -XGET server2:9200
# curl -XGET server3:9200
Get Elasticsearch Cluster Health Status
To retrieve cluster health status information, we need to run the
following query through the _cluster endpoint.
[root@server1 ~]# curl -XGET 192.168.0.11:9200/_cluster/health?pretty
{
"cluster_name" : "my-cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 19,
"active_shards" : 38,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
The preceding expression shows the cluster health output of Elasticsearch Cluster setup. Here, we can see the various details of the cluster, such as the name of the cluster, status, whether it has timed out, the number of nodes, the number of data nodes, the number of active primary shards, the number of active shards, the number of initializing shards, the number of pending tasks, and more.
Check elasticsearch cluster state
The cluster state retrieves information about the comprehensive state of the elasticsearch cluster setup.
[root@server1 ~]# curl -XGET 192.168.0.10:9200/_cluster/state?pretty |less
<Output trimmed>
"nodes" : {
"w3gQLlyVT0-xN77BUTCxPQ" : {
"name" : "server3",
"ephemeral_id" : "lOtXNcGgRyW-lOTH0N89MA",
"transport_address" : "192.168.0.13:9300",
"attributes" : {
"xpack.installed" : "true"
}
},
"F4FKqWIbT8WnPrv84y9_gA" : {
"name" : "server1",
"ephemeral_id" : "XqbaxLswQ_ixAJKqBDIDpQ",
"transport_address" : "192.168.0.11:9300",
"attributes" : {
"xpack.installed" : "true"
}
},
"GnAN94xeTnC47W8PrCWbCA" : {
"name" : "server2",
"ephemeral_id" : "B_0RRXv1RH-ZjbtKLIxryA",
"transport_address" : "192.168.0.12:9300",
"attributes" : {
"xpack.installed" : "true"
}
}
<Output trimmed>
Check elasticsearch cluster stats
After you configure elasticsearch cluster you can use the
_cluster stats APIs retrieve information from the overall cluster.
They retrieve basic index metrics, such as memory usage,
shard numbers, and information about the nodes in the cluster (including
the number of nodes, the installed plugins, and the operating system).
We can see the cluster statistics using the following command:
# curl -XGET 192.168.0.12:9200/_cluster/stats?pretty
Get elasticsearch cluster node details
The cluster nodes API _cat/nodes returns information about the
elasticsearch node types in the cluster.
[root@server1 ~]# curl -XGET server1:9200/_cat/nodes
192.168.0.13 13 97 1 0.23 0.13 0.11 dim - server3
192.168.0.11 35 97 2 0.19 0.11 0.12 dim - server1
192.168.0.12 14 98 2 0.07 0.07 0.06 dim * server2
Here,
- m means master-eligible node
- d means data node
- i means ingest node
With <strong>*</strong> we know that server1 is the current master
node in the cluster.
Get elasticsearch cluster master node
After you configure elasticsearch cluster, you can use master API to
get elasticsearch cluster master node, including the ID, bound IP
address, and name of the elasticsearch cluster setup.
[root@server1 ~]# curl -XGET server1:9200/_cat/master
GnAN94xeTnC47W8PrCWbCA 192.168.0.12 192.168.0.12 server2
[root@server1 ~]# curl -XGET server1:9200/_cat/master?v
id host ip node
GnAN94xeTnC47W8PrCWbCA 192.168.0.12 192.168.0.12 server2
Additional configuration for production elasticsearch cluster setup
Some additional points to note to configure elasticsearch cluster setup in production environment
Avoid Split brain
-
The presence of two master nodes in a cluster can cause what is called split brain. In elastic search there is a master node and then there is master eligible node which can become a master node should the master node fails.
-
In the event of master node failure it is important that the majority of the master eligible nodes agree which master is elected. Split brain occurs when two different part of the cluster elects a different master node which can be problematic node by adjusting the minimum master setting you can prevent split brain.
-
The formula for setting the correct number is
(total number of master eligible nodes in the cluster/2)+1 -
This should be considered when you configure elasticsearch cluster for setting minimum number of master nodes or master eligible nodes in the elasticsearch cluster setup.
Memory Configuration
The more memory available to Elasticsearch Cluster Setup, the more memory it can use for caching, which improves the overall performance. Also, to run aggregations on your data, there are memory considerations. When you configure elasticsearch cluster for production, it important to make sure Elasticsearch has enough memory.
1. Disable Swapping
Swapping is very bad for performance, for node stability, and should be avoided at all costs. It can cause garbage collections to last for minutes instead of milliseconds and can cause nodes to respond slowly or even to disconnect from the cluster.
Usually Elasticsearch is the only service running on a box, and its memory usage is controlled by the JVM options. There should be no need to have swap enabled. To disable swap
# swapoff -a
This doesn’t require a restart of Elasticsearch.
To permanently disable swap, modify /etc/fstab and comment/remove the
line that contain file system type as "swap"
2. Configure swappiness
Another option available on Linux systems is to ensure that the sysctl reload
value vm.swappiness is set to 1. This reduces the kernel’s tendency
to swap and should not lead to swapping under normal circumstances,
while still allowing the whole system to swap in emergency conditions.
3. Set JVM Memory
By default, when you start Elasticsearch, the heap size of the JVM is
1GB. You can monitor the heap usage and garbage collections using the
node stats API. After you configure elasticsearch cluster you should
also configure the JVM settings, such as heap size, garbage collection,
and so on in the /etc/elasticsearch/jvm.options file.
Let's look at the elasticsearch cluster setup memory usage using the node stats API as shown next:
[root@server1 ~]# curl -XGET 'http://server1:9200/_nodes/server1/stats/jvm?pretty&human'
<Output trimmed>
"jvm" : {
"timestamp" : 1577313710573,
"uptime" : "5.8h",
"uptime_in_millis" : 21209043,
"mem" : {
"heap_used" : "299.1mb",
"heap_used_in_bytes" : 313702368,
"heap_used_percent" : 30,
<Output trimmed>
You can increase the heap size by setting the -Xms and -Xmx
settings. In the jvm.options file, under the JVM Heap Size section,
set the following:
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms1g
-Xmx1g
Once you make these changes, restart your Elasticsearch instance and use the node stats API to verify heap size.
4. Enable bootstrap.memory_lock
Another option is to use mlockall on Linux/Unix systems to try to lock
the process address space into RAM, preventing any Elasticsearch memory
from being swapped out when you configure elasticsearch cluster.
To enable bootstrap.memory_lock
- The systemd service file
(
/usr/lib/systemd/system/elasticsearch.service) contains the limits that are applied by default. - To override them, add a file called
/etc/systemd/system/elasticsearch.service.d/override.conf(alternatively, you may runsystemctl edit elasticsearchwhich opens the file automatically inside your default editor) - Add below content in this file
[Service]
LimitMEMLOCK=infinity
- Once finished, run the following command to reload units:
# systemctl daemon-reload
- Next add this line to the
/etc/elasticsearch/elasticsearch.ymlfile:
bootstrap.memory_lock: true
After starting Elasticsearch, you can see whether this setting was
applied successfully by checking the value of mlockall in the output
from this request:
[root@server1 ~]# curl -XGET 'http://server1:9200/_nodes?pretty&filter_path=**.mlockall'
{
"nodes" : {
"w3gQLlyVT0-xN77BUTCxPQ" : {
"process" : {
"mlockall" : true
}
},
"F4FKqWIbT8WnPrv84y9_gA" : {
"process" : {
"mlockall" : true
}
},
"GnAN94xeTnC47W8PrCWbCA" : {
"process" : {
"mlockall" : true
}
}
}
}
Configure file descriptors
- A file descriptor is nothing but a handler to the file assigned by the operating system.
- Once a file is opened, a file descriptor, which is an integer, is assigned to the file.
- Also, Elasticsearch uses a lot of file descriptors for network communications as the nodes need to communicate with each other.
- Elasticsearch recommends 65,536 or higher.
- You can either set the descriptors by running the following command as root before starting Elasticsearch:
# ulimit -n 655356
- Alternatively, you can set the limit permanently by editing the /etc/security/limits.conf and setting the no file for the user running Elasticsearch.
elasticsearch - nofile 65535
Troubleshooting Error Scenarios
Error: master not discovered yet, this node has not previously joined a bootstrapped (v7+) cluster
[server1] master not discovered yet, this node has not previously joined a bootstrapped (v7+) cluster, and [cluster.initial_master_nodes] is empty on this node: have discovered [{server1}
Explanation:
The node names used in the cluster.initial_master_nodes list must
exactly match the node.name properties of the nodes. If you use a mix of
fully-qualified and bare hostnames, or there is some other mismatch
between node.name and cluster.initial_master_nodes, then the cluster
will not form successfully and you will see log messages like the
following.
[master-a.example.com] master not discovered yet, this node has not previously joined a bootstrapped (v7+) cluster, and this node must discover master-eligible nodes [master-a, master-b] to bootstrap a cluster: have discovered [{master-b.example.com}{...
This message shows the node names master-a.example.com and
master-b.example.com as well as the cluster.initial_master_nodes
entries master-a and master-b, and it is clear from this message
that they do not match exactly.
I ended up with the same error while bringing up my elasticsearch cluster. Here as you see the cluster uuid is different on these nodes.
[root@server3 ~]# curl -XGET localhost:9200/_cat/nodes
192.168.0.12 7 22 34 0.59 0.18 0.06 dilm * server2
[root@server3 ~]# curl -XGET localhost:9200/_cat/nodes
192.168.0.13 26 24 0 0.00 0.01 0.05 dilm * server3
192.168.0.11 10 22 0 0.00 0.01 0.05 dilm - server1
Solution:
Shut down elasticsearch service on all the cluster nodes.
# systemctl stop elasticsearch
Completely wipe each node by deleting the contents of their data folders
on all the cluster nodes. The data folder is defined using path.data in
elasticsearch.yml. We are using the default path.data value
/var/lib/ealsticsearch
# rm -rf /var/log/elasticsearch/*
Next configure elasticsearch cluster with your elasticsearch.yml file
properly this time
Restart all the nodes and verify that they have formed a single cluster.
# systemctl start elasticsearch
Verify with an API request to make sure all the nodes are part of the same cluster
# curl -XGET server1:9200/_cat/nodes
192.168.0.12 29 96 1 0.05 0.04 0.05 dim * server2
192.168.0.13 31 97 0 0.08 0.09 0.13 dim - server3
192.168.0.11 15 79 0 0.00 0.01 0.05 dim - server1
- Enable HTTPS and Configure SSS/TLS to secure Elasticsearch Cluster
- Install and Configure Kibana 7.5 with SSL/TLS for Elasticsearch Cluster
- Configure Metricbeat 7.5 to monitor Elasticsearch Cluster Setup over HTTPS
- Install and Configure Logstash 7.5 with Elasticsearch
Lastly I hope the steps from this article to configure elasticsearch cluster with examples in CentOS/RHEL 7/8 Linux was helpful. So, let me know your suggestions and feedback using the comment section.
References:
Configure elasticsearch system
settings
Mastering Elasticsearch (ELK Stack)
