The whole reason Kubernetes operators exist is to fight drift. Somewhere in your cluster, a human just ran kubectl edit deployment and changed the replica count back to what they prefer. Another controller just injected a sidecar your operator did not request. A botched upgrade rolled back a label change you made yesterday. Without drift correction, every operator in production decays into "the state we started with plus six months of accumulated chaos."
The good news: drift detection is mostly free with controller-runtime — the reconcile loop is itself a drift check that runs on every event. The remaining problem is detecting drift you cannot see through normal watches: external systems, missed events on flaky networks, and the rare-but-loud case of a human re-editing a child object faster than the operator notices.
This guide is part of the Advanced Capabilities chapter. If you have not yet read the reconcile loop primer, desired state vs actual state, or watches, events, and predicates, start there — drift detection is the practical payoff of all three.
What Is Drift in Kubernetes Operator?
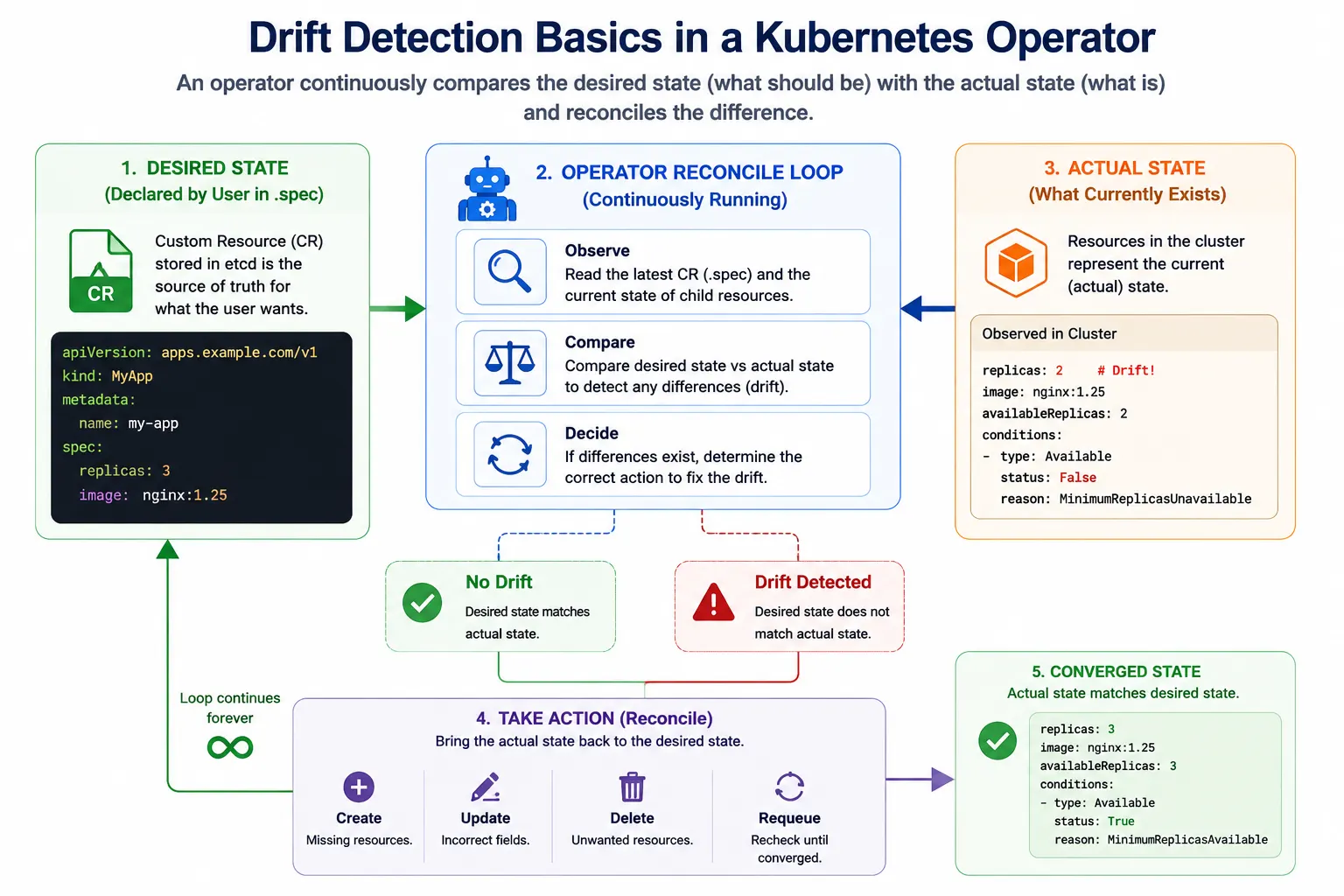
Drift occurs whenever the actual state of a system no longer matches the desired state declared by the operator.
For example:
Desired state:
spec:
replicas: 3Actual state:
status:
replicas: 2The difference between those two states is drift.
The operator's job is not to create resources once and exit. Its job is to continuously detect drift and reconcile the system back to the desired state.
The 60-second answer
A Kubernetes operator detects drift in four ways, often combined:
- Watch-based reconciliation — controller-runtime fires Reconcile whenever a primary or owned secondary resource changes. This catches 95% of drift for free. Whoever edited a Deployment, your operator gets a watch event within milliseconds.
- Periodic resync — controller-runtime's
SyncPeriodre-enqueues every watched object on a timer (default ~10 hours). This catches the case where a watch missed an event (network blip, API server restart). - Spec diffing with three-way merge — comparing your desired spec to the cluster state and applying only the difference.
client.Patch(ctx, obj, client.MergeFrom(old))or Server-Side Apply do this for you. - External drift detection — polling unowned systems (Cloudflare, AWS, external database) on a timer and enqueuing the CR when drift is found. You implement this yourself; controller-runtime gives you the requeue primitive.
The right answer is almost always "all four, layered." Watches are the firehose. SyncPeriod is the safety net. Patch-based writes ensure you only fight drift on fields you actually care about. External polling fills the gap for resources outside Kubernetes' watch model.
You're already using drift detection every day
Every built-in Kubernetes controller is a drift-detection engine. You've been relying on this since your first kubectl apply, even if you've never written an Operator.
Consider a Deployment with replicas: 3.
- A node crashes and one Pod disappears.
- The Deployment controller notices the actual state is now 2 Pods running.
- The desired state is still 3 Pods.
- The controller automatically creates a new Pod.
The Deployment controller detected drift and corrected it.
Similarly, if a Pod fails its liveness probe:
- Kubernetes detects the container is unhealthy.
- The actual state no longer matches the desired healthy state.
- The kubelet automatically restarts the container.
Again, drift was detected and corrected.
An Operator works exactly the same way, except it manages your application-specific resources instead of generic Kubernetes resources.
| Kubernetes Built-in Controller | What Drift Was Detected? | Automatic Correction |
|---|---|---|
| Deployment Controller | Running Pods < Desired Replicas | Create new Pods |
| ReplicaSet Controller | Pod deleted manually | Recreate Pod |
| StatefulSet Controller | Missing Stateful Pod | Recreate Pod with same identity |
| Job Controller | Job not completed | Start replacement Pod |
| Kubelet + Liveness Probe | Container unhealthy | Restart container |
| Horizontal Pod Autoscaler | Metrics exceed threshold | Increase replicas |
| Custom Operator | Application-specific state differs from desired state | Reconcile resources |
The key idea is simple:
Every Kubernetes controller is fundamentally a drift-detection engine.
A Deployment reconciles Pods.
A StatefulSet reconciles Stateful Pods.
An HPA reconciles replica counts.
An Operator reconciles your application's desired state.
The reconciliation pattern is identical; only the resources being managed are different.
Where Drift Actually Comes From
In real clusters, drift rarely comes from the operator itself.
The most common drift sources are:
| Drift Source | Example |
|---|---|
| Manual changes | kubectl edit deployment changes image or replicas |
| Emergency hotfixes | Engineer patches a ConfigMap during an outage |
| Other controllers | HPA updates replica count |
| Admission webhooks | Sidecar injection adds containers or labels |
| External systems | DNS records, databases, cloud resources change |
| Helm upgrades | Values change and resources are re-rendered |
| Failed rollbacks | Cluster state partially reverts |
The operator's job is not simply to create resources.
Its job is to continuously compare:
Desired State (what should exist)
vs
Actual State (what currently exists)
and reconcile the difference.
Pattern 1 — Watch-based reconciliation (the default)
Controller-runtime sets this up for you automatically when you write something like the following — the Memcached type comes from the Operator-SDK quickstart CRD used as the running example throughout this series:
return ctrl.NewControllerManagedBy(mgr).
For(&cachev1alpha1.Memcached{}).
Owns(&appsv1.Deployment{}).
Owns(&corev1.Service{}).
Complete(r)Three things happen:
- A watch is registered on the primary resource. Every CREATE, UPDATE, and DELETE of a
MemcachedCR enqueues a reconcile request for that CR. - A watch is registered on each owned secondary. When the operator-owned Deployment changes (someone edited it with
kubectl edit), the cache fires an event. controller-runtime traces the owner reference back to the Memcached CR and enqueues that CR for reconcile. See owner references and garbage collection for why this works. - Predicates filter the firehose. Most operators add
GenerationChangedPredicate{}to ignore status-only writes — see watches, events, and predicates for the full catalogue.
This is the cheapest and fastest drift detection mechanism. A human ran kubectl edit deployment memcached-sample and changed the image — within milliseconds your Reconcile is called with the original CR, your code compares desired spec to actual Deployment spec, and you write the original image back.
Limits of pure watch-based detection:
- Watches can miss events. API server restarts, network blips, and cache resyncs can drop a notification. You will catch the next change, but the missed window is real.
- You can only watch resources you have RBAC for. Anything outside the cluster is invisible.
- You cannot watch yourself. If your operator is the only writer for a field, a missed watch on that field would never be caught — there is no other writer to trigger a re-read.
That is why every production operator layers something on top.
Pattern 2 — Periodic resync with SyncPeriod
SyncPeriod is controller-runtime's safety net for missed events. Once per period, every object in the cache is re-enqueued for reconcile — as if a synthetic UPDATE event had fired.
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Cache: cache.Options{
SyncPeriod: ptr.To(10 * time.Minute),
},
})The default is 10 * time.Hour with ±10% jitter per replica, which is correct for almost every operator. Set it shorter only if you have a specific reason:
- You depend on detecting drift from a system that does not emit Kubernetes watch events.
- You operate in an environment where watch resyncs happen frequently and you want a faster safety net.
Do not set it to "1 minute" because you want "fast drift correction" — every reconcile costs CPU, etcd writes (if you update status), and possibly external API calls. A 10-minute SyncPeriod on 1000 CRs means 1000 reconciles every 10 minutes whether or not anything is happening. With a 1-minute period, that becomes 60,000 reconciles per 10 minutes — which is how operator pods get themselves OOMKilled in production.
Pattern 3 — Spec diffing with client.Patch (three-way merge)
When you write r.Update(ctx, dep), you are sending the entire Deployment spec. If someone else (admission webhook, HPA, manual edit) changed a field, you overwrite it.
When you write r.Patch(ctx, dep, client.MergeFrom(original)), controller-runtime computes the diff between the original (what you read from the cache) and the current (what you mutated in memory). Only fields you actually changed are sent to the API server. Fields touched by other writers are left alone.
// Three-way diff using MergeFrom — the modern minimum.
dep := &appsv1.Deployment{}
if err := r.Get(ctx, key, dep); err != nil {
return err
}
patch := client.MergeFrom(dep.DeepCopy())
dep.Spec.Template.Spec.Containers[0].Image = "memcached:1.6.18"
if err := r.Patch(ctx, dep, patch); err != nil {
return err
}This is drift-aware writing: your operator corrects drift on containers[0].image but does not stomp on spec.replicas even if an HPA changed it. The same effect, scaled up, is what Server-Side Apply provides through metadata.managedFields and FieldOwner — covered in Server-Side Apply in operators.
Two quick rules:
- Use
client.StrategicMergeFromfor built-in Kubernetes types (Deployment, Service, StatefulSet) — it knows thatcontainersis a list-by-name, not a list-by-index. - Use
client.MergeFromfor your own CRDs (and for any object without strategic merge semantics) — it does plain JSON merge.
Pattern 4 — External drift detection
This is the pattern you write yourself. The operator manages a resource that is not a Kubernetes object — a cloud DNS record, an S3 bucket policy, a row in an external database. Watches do not work; you must poll.
The mechanism is: a background goroutine on a timer that calls the external API, compares the result to the desired state in the CR, and enqueues the CR for reconcile if drift is detected.
// In main.go or a setup method.
go func() {
ticker := time.NewTicker(2 * time.Minute)
defer ticker.Stop()
for {
select {
case <-ctx.Done():
return
case <-ticker.C:
var crList cachev1alpha1.MemcachedList
if err := mgr.GetCache().List(ctx, &crList); err != nil {
continue
}
for _, cr := range crList.Items {
if r.externalDriftDetected(ctx, &cr) {
r.enqueueCR(cr.GetName(), cr.GetNamespace())
}
}
}
}
}()A few practical notes:
- Use the controller-runtime cache for the List (not the API client). The cache is up to date, lock-free, and free — the API client costs an HTTP round trip per call.
- Enqueue, do not reconcile in-place. The goroutine should drop a key into the workqueue. The actual Reconcile runs on the worker pool with all the normal protections (rate limiting, backoff, leader election).
- Pick a polling interval that fits the external system. Cloud APIs typically rate-limit at 10–50 req/sec across all clients in an account; a 2-minute poll for 1000 CRs is 8.3 req/sec for that one operator alone.
- Log every drift detection. Drift events on external systems are operationally interesting — somebody clicked a console button. Emit a Kubernetes Event so the incident is visible in
kubectl describe.
Annotation-based drift signalling (the "stale CR" pattern)
A useful additional pattern: when reconcile successfully writes the desired state, record what it wrote in an annotation. Next time, compare. This gives you a cheap drift signal without re-listing everything:
const lastAppliedAnnot = "memcached-operator.example.com/last-applied-spec"
specHash := hashMemcachedSpec(cr.Spec)
if cr.GetAnnotations()[lastAppliedAnnot] != specHash {
// CR spec changed since last reconcile — proceed with full reconcile.
if err := r.reconcileChildren(ctx, &cr); err != nil {
return err
}
annotations := cr.GetAnnotations()
if annotations == nil {
annotations = map[string]string{}
}
annotations[lastAppliedAnnot] = specHash
cr.SetAnnotations(annotations)
if err := r.Update(ctx, &cr); err != nil {
return err
}
}This is the same idea as kubectl.kubernetes.io/last-applied-configuration but scoped to your operator's view of what it owns. It is useful when:
- Your reconcile is expensive (talks to many external systems).
- Your CR has fields that change frequently for reasons unrelated to spec (e.g. status timestamps).
- You want a "did this reconcile do anything?" signal for metrics.
A word of caution: never use this as the only drift signal. The annotation tells you "the CR spec did not change", not "nothing in the cluster changed". You still need watch-based reconciliation for child resources.
Layering the patterns together
These four patterns are not alternatives. Production-grade operators layer them on top of each other, because each one closes a different class of drift that the others cannot see:
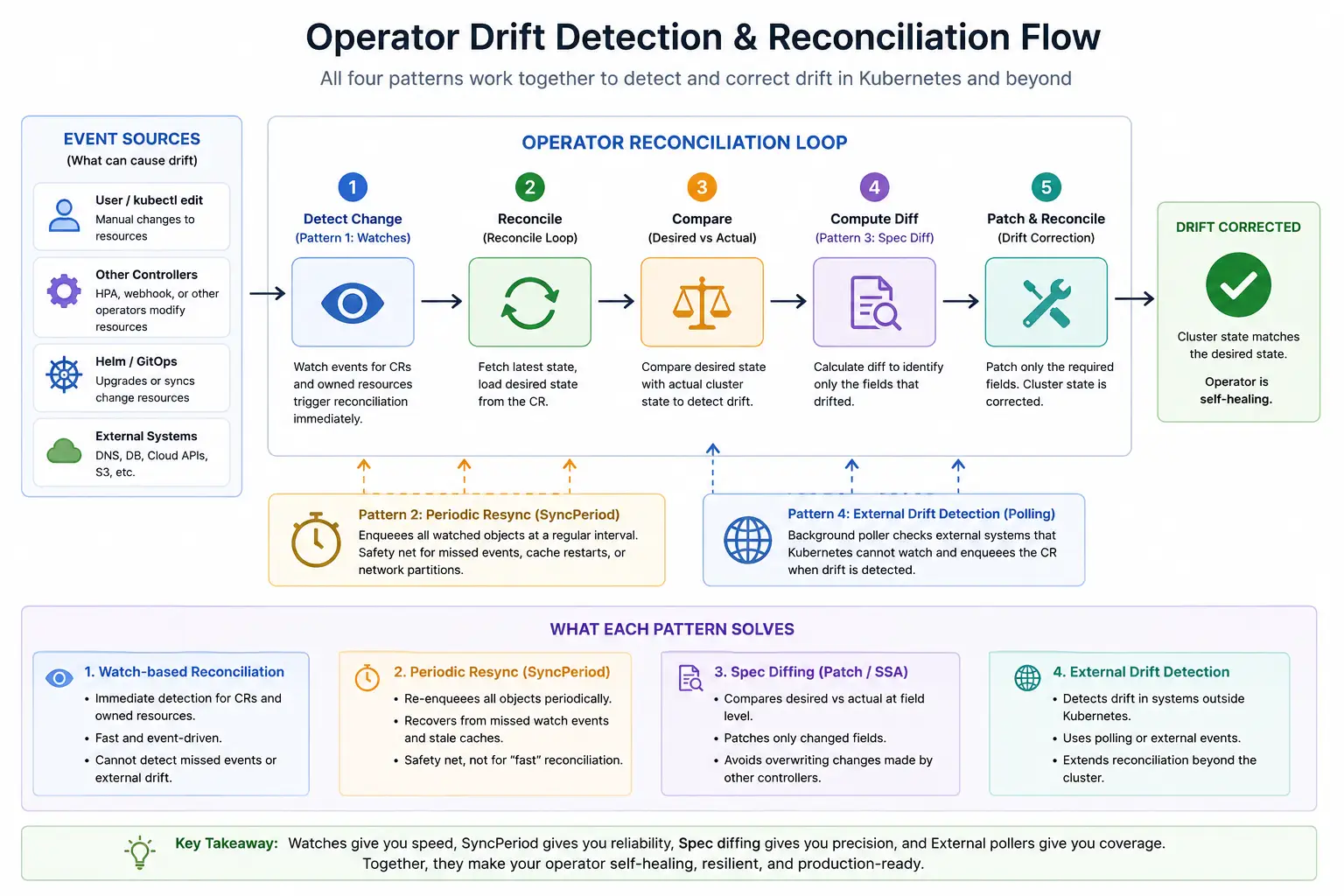
| Pattern | Catches | When it fires |
|---|---|---|
| Watch-based reconciliation | In-cluster drift on the CR and owned secondaries | Within milliseconds of any CREATE/UPDATE/DELETE |
Periodic resync (SyncPeriod) |
Drift the watch dropped (API server restart, network blip, cache resync) | Every ~10 hours by default, per object |
Spec diffing (Patch, SSA) |
Drift on the fields you own — without stomping on other writers' fields | On every write |
| External drift detection | Drift in systems Kubernetes can't watch (cloud APIs, DNS, external DBs) | On a timer you control |
The combined flow is simple to describe and powerful in practice:
- Something changes — inside or outside the cluster.
- The operator finds out through a watch event, a SyncPeriod tick, or an external poller.
- Reconcile loads the latest desired state from the CR and observes actual state in the cluster.
- A diff is computed; only the drifted fields are written back, using
Patchor Server-Side Apply so other controllers' fields stay intact.
Watches do roughly 95% of the work. Everything else exists to cover the long tail.
Common pitfalls
Pitfall 1 — Tightening SyncPeriod to "fix" missing reconciles.
If a particular CR is not being reconciled when you expect, the bug is almost never that the SyncPeriod is too long. It is usually a predicate filter that is too aggressive, a watch that is not registered, or an owner reference that is missing. Cranking SyncPeriod down to 1 minute hides the real bug behind brute force and quadruples your reconciler CPU usage.
Pitfall 2 — Reconciling on every watch event without diff.
A common pattern: receive watch event → re-read CR → write child Deployment unconditionally → child Deployment fires its own watch event → goto receive watch event. This is a hot loop. Always compare desired spec to actual spec before writing:
desired := r.deploymentFor(&cr)
existing := &appsv1.Deployment{}
if err := r.Get(ctx, depKey, existing); err == nil {
if apiequality.Semantic.DeepEqual(existing.Spec, desired.Spec) {
return ctrl.Result{}, nil // no drift, no write
}
}
// ... apply updateThe fix is to predicate-filter status-only events with GenerationChangedPredicate and to deep-equal the spec before writing — see watches, events, and predicates for the full predicate catalogue.
Pitfall 3 — Drift detection on .status.
.status is owned by your operator; nothing else writes it. Comparing observed status to desired status to detect drift is a category error — they are by construction equal. Detect drift on .spec only.
Pitfall 4 — Using time.Sleep in a goroutine for external polling.
time.Sleep does not respect context cancellation, so on operator shutdown the goroutine keeps polling for the rest of the sleep period. Use time.NewTicker combined with select { case <-ctx.Done(): } so the goroutine exits cleanly when the manager receives SIGTERM. Controller-runtime's Manager.Start(ctx) will cancel that context for you on shutdown — never use context.Background() inside an operator goroutine.
Pitfall 5 — Drift correction that fights an authoritative writer.
If an HPA owns spec.replicas and your operator also writes it, every reconcile is a fight. The HPA wins, then your operator wins, then the HPA wins again. Drift detection here is correct — your spec says replicas=3, the cluster says 5 — but the correct response is to stop writing the field, not to keep correcting it. Switch to Server-Side Apply with a strict FieldOwner contract.
Pitfall 6 — Forgetting that DELETE events also fire watches.
A user runs kubectl delete deployment on an operator-owned child. The watch fires, your reconcile runs, you see the Deployment is gone, you re-create it. Good. But if the CR itself was being deleted at the same time and the Deployment delete came from cascade GC, you must not re-create — check cr.GetDeletionTimestamp() before reconciling child state. See Kubernetes finalizers for the full pattern.
Further reading
- Kubernetes: The Kubernetes controller pattern
- controller-runtime Manager options:
Options.SyncPeriod - API machinery:
apiequality.Semantic.DeepEqual - Internal: · · · · ·
Frequently Asked Questions
1. What is drift in a Kubernetes operator?
kubectl edit, another controller mutated a field (an HPA changed replicas, an admission webhook injected a label), or a manual rollback during an incident. Detecting drift is the central job of an operator — the reconcile loop is literally a diff + reconcile pass run repeatedly.2. Does an operator need explicit drift detection if it already watches its resources?
3. What is `SyncPeriod` and should I set it?
SyncPeriod is a controller-runtime Manager option that forces every watched object to be re-enqueued at a regular interval (default ~10 hours, randomised ±10% across replicas). It guarantees that a missed watch event eventually triggers a reconcile. For most operators the default is correct — leave it alone. Override it only if you depend on drift detection against an external system (then a shorter period catches external drift faster) or if your test cluster has flaky network and watches reset frequently.4. How is drift different from a normal reconcile?
SyncPeriod or an external timer when nothing visible has happened. The reconcile code is the same; only the dispatcher differs.5. What is the three-way diff and when do I need it?
kubectl apply and Server-Side Apply. Most operators do not need to implement it themselves — using client.Patch with MergeFrom (or Server-Side Apply) gets the same semantics for free.6. Why does my operator keep reconciling the same CR even when nothing changed?
.status on every pass, which fires a status watch event, which re-enqueues the CR. The fix is to compare conditions before writing — only call Status().Update when the conditions actually changed. Use apiequality.Semantic.DeepEqual to short-circuit identical writes. This is the most common controller "hot loop" pattern, and predicates such as GenerationChangedPredicate filter most of the noise away — see watches, events, and predicates.7. How do I detect drift on resources my operator does not own?
Watches() on a Source with a custom EventHandler that maps the watched object back to your CR. For external systems (cloud APIs, external databases), poll on a timer in a background goroutine and enqueue the CR when you detect drift. The same SyncPeriod mechanism is reused — but you implement the polling yourself.8. What is the difference between watch-based reconciliation and SyncPeriod?
9. How often should a Kubernetes operator reconcile?
SyncPeriod at the controller-runtime default of ~10 hours unless you have a specific reason to lower it. For external systems you have to poll, pick an interval that fits the external API's rate limits (typically minutes, not seconds) and multiply by the number of CRs to make sure you stay under the limit cluster-wide.Summary
Drift detection is not a separate feature you add to an operator — it is the operator's reason to exist. The reconcile loop is a drift-detection-and-correction loop running on every event. Most of the work is done for you by controller-runtime: watches catch in-cluster changes within milliseconds, SyncPeriod provides a safety net for missed events, and Patch writes leave other controllers' fields alone.
What is left for you to add is exactly two things:
- Make your reconcile cheap and idempotent. Diff before writing, use Server-Side Apply where multiple controllers co-own a resource, and never re-update status that has not changed.
- Add external pollers only for resources you cannot watch. A goroutine on a ticker, enqueueing CRs into the workqueue — never reconciling in-place, and always tied to the manager's context so it shuts down cleanly on SIGTERM.
An Operator is not a new kind of system; it extends the same reconciliation model that already powers the Deployment controller, the kubelet's liveness probes, and the HPA — applied to your own application domain.
