If you have ever wondered what actually happens between a kubectl apply and
your Operator changing the cluster, the answer is one phrase: the reconcile
loop. It is the heartbeat of every Kubernetes controller, and once you
internalise how it works, every other Operator concept — finalizers, status
conditions, leader election, drift detection — falls into place.
This guide walks the full pipeline end to end, covers the three Reconcile()
return paths, and shows the anti-patterns that cause the hot loops you will
see in real production clusters.
If you have not yet read What is a Kubernetes Operator? or Operator vs Controller vs CRD, start there — both articles set up the vocabulary we use below.
TL;DR — the reconcile loop in 30 seconds
The Kubernetes reconcile loop (a.k.a. Kubernetes reconciliation loop or Kubernetes controller loop) is the control loop that:
- Watches the API server for changes to one or more resource types.
- Stores the latest version of every watched object in an in-memory cache.
- Enqueues the namespace/name key of changed objects into a workqueue.
- Pops keys off the queue, fetches the latest state from the cache, and
calls your
Reconcile(ctx, req)function. - Acts - your code reads
.spec, compares it to actual state, and issues create / update / delete operations to close the gap. - Requeues the item if anything went wrong, with exponential backoff.
The defining property is that the loop is level-triggered - it reacts to the current state of an object, not to individual events. That single design choice is why Kubernetes survives missed events, network partitions, and controller restarts.
A quick analogy: think of it as your GPS
Before we dive into watchers and workqueues, picture this everyday situation: you are driving and your GPS app says "turn right in 200 metres." You miss the turn. What happens next?
The GPS does not crash. It does not say "please rewind 200 metres so I can resend the instruction." It simply looks at where you are right now, recalculates, and gives you the next best instruction. If you take a wrong turn again, it recalculates again. It never tries to remember every wrong turn you made — it just keeps looking at your current location and the destination, and tells you the next step.
That is exactly how the Kubernetes reconcile loop works. The loop does not
care about the history of changes ("the user first set replicas to 3,
then to 5, then to 4 — let me apply those in order"). It only cares about
the current desired state in .spec versus the current actual
state in the cluster, and it computes the next best action.
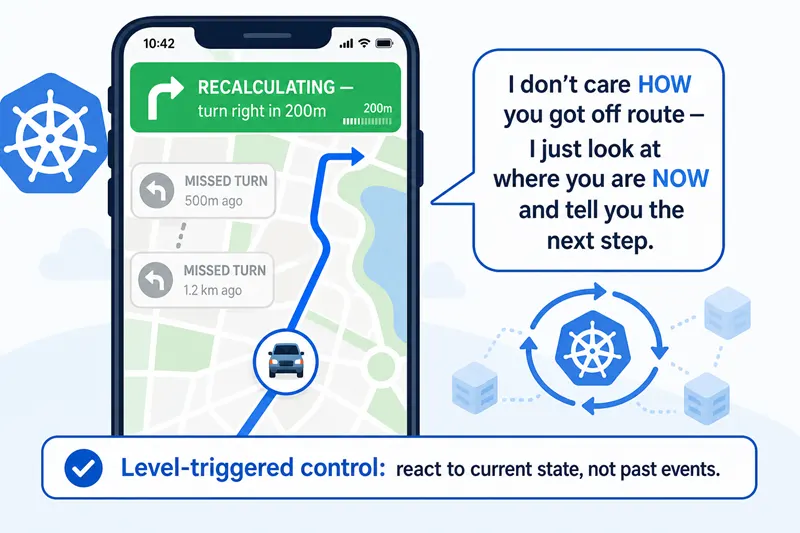
This style of control is called level-triggered, and it is the single most important property of every Kubernetes controller. We will come back to it in a minute.
Why the reconcile loop matters
Three reasons it is worth investing the time to truly understand this one pattern, rather than treating it as one tool among many:
1. It is the contract every Operator inherits
You do not get to opt out of the loop. The moment you build an Operator with
controller-runtime, kubebuilder, or Operator SDK, your code becomes a
Reconcile() function that the framework will call — possibly thousands of
times per object, possibly while another instance of you is shutting down.
Most of the
design patterns you will use
(Singleton, Capability, Lifecycle, Auto-Pilot) are just different shapes of
what to do inside that one function. Get the loop wrong and every pattern
built on top of it is wrong.
2. It dictates your API surface
A level-triggered controller drives every decision about how .spec and
.status are shaped. .spec must describe the desired state, never an
imperative action ("upgrade now"), because the loop will read it again next
hour and again next day. .status must be computable from observation,
because the controller may restart and lose every cached fact about what it
last did. Users see the consequences of the loop in the API every time they
write a CR.
3. The same primitive runs everything
Deployment, ReplicaSet, Job, StatefulSet, Ingress, HPA — every
one of them is a level-triggered reconcile loop, written against the same
workqueue and the same informer cache. Understand this article and you have
understood kube-controller-manager. Every Operator you ever ship and every
controller you ever debug uses the same six bullet points from the TL;DR
above.
Level-triggered, not edge-triggered
Almost every misunderstanding about controllers starts here. Two ways a control system can react to change:
| Model | Reacts to | What happens if an event is lost? |
|---|---|---|
| Edge-triggered | A transition ("replicas changed from 3 to 5") | The action is lost forever. Recovery requires replaying the event log. |
| Level-triggered | The current state ("replicas is now 5") | Safe. The next reconcile sees the same level and acts the same way. |
A concrete example: imagine you have a Deployment asking for 3 replicas. Then 100 things happen in 1 second — a Pod crashes, a node goes OOMKilled, you scale up to 5, the autoscaler scales back to 4. An edge-triggered controller would have to replay all 100 events in order to know what to do. A level-triggered controller does not care about any of them — it just looks at the cluster right now and asks: "are there 4 healthy Pods?" If yes, done. If no, create or delete enough Pods to make it so.
Kubernetes is level-triggered. The watch stream from the API server triggers your reconciler, but the reconciler does not consume the event payload — it asks the cache for the latest state of the object and works from there.
The official Kubernetes controller documentation puts it crisply:
"The controller tracks at least one Kubernetes resource type ... Other control loops can use that core information to perform additional steps; for example, the kube-controller-manager makes use of these information for deployments."
The SIG API Machinery controllers.md
document
is the canonical primary source if you want the design rationale in depth.
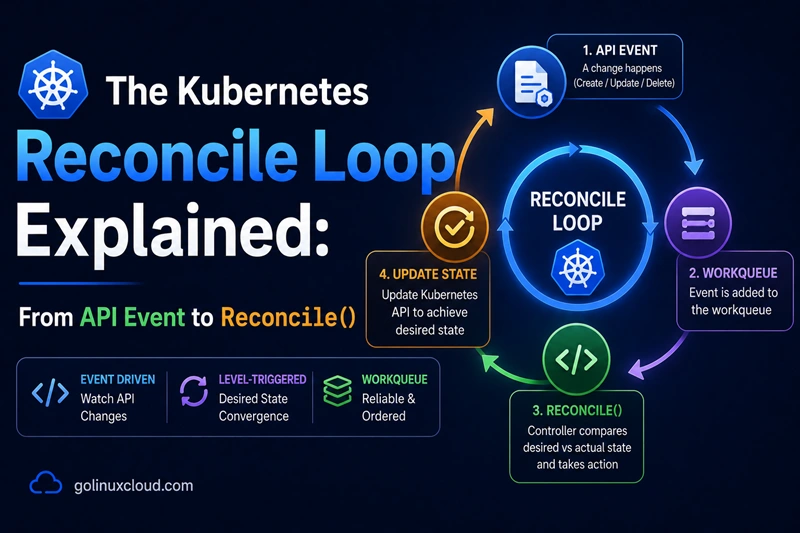
The full pipeline - API Server to Reconcile()
The diagram below shows the complete path from a user action to your controller's Reconcile() function.
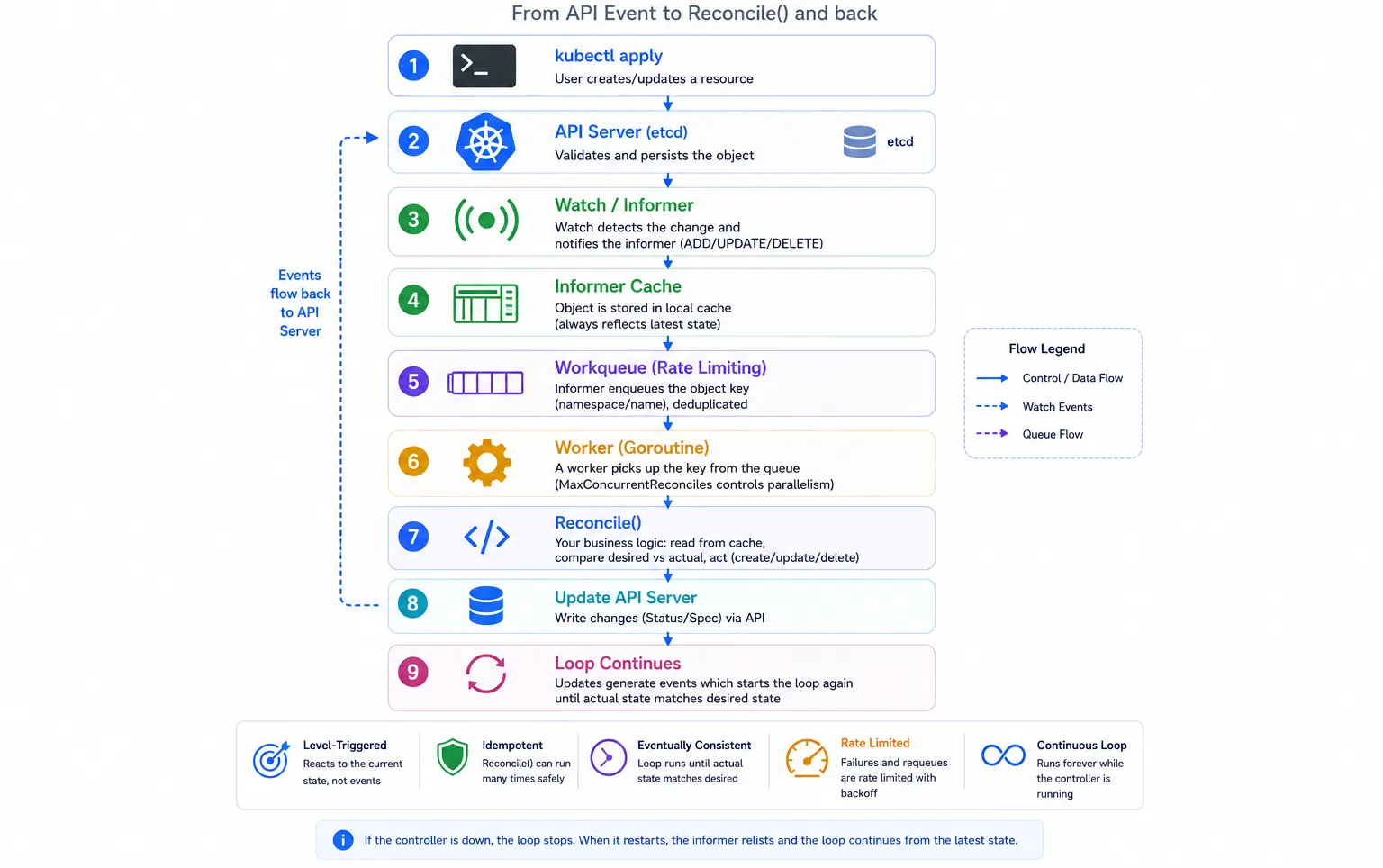
A simple kubectl apply -f mycluster.yaml starts a chain of events:
- The API Server validates and stores the object in
etcd. - A watch notifies the controller's informer about the change.
- The object is updated in the local informer cache.
- The object's
namespace/namekey is placed into a rate-limited workqueue. - A worker goroutine picks the key and calls
Reconcile(ctx, req). - Your reconciler compares the desired state with the actual state and makes any required changes.
- Those changes generate new events, and the loop continues until the cluster converges to the desired state.
A few important details:
- The cache stores objects, while the workqueue stores only keys (
namespace/name). - Multiple updates to the same object are deduplicated in the workqueue.
- Workers always read the latest state from the cache, not from the original event.
- Returning an error requeues the key with exponential backoff.
- The loop is level-triggered: it reacts to the current state of the object, not to individual events.
This architecture is what makes Kubernetes controllers scalable, resilient to missed watch events, and safe to run continuously in large clusters.
The Reconcile() signature
In controller-runtime every reconciler implements:
type Reconciler interface {
Reconcile(ctx context.Context, req Request) (Result, error)
}
type Request struct {
NamespacedName types.NamespacedName // namespace + name
}req carries only the key - not the object. You must client.Get() the
current state at the top of your function. The four reconcile result types
you can return are:
| Return | Meaning |
|---|---|
Result{}, nil |
Success. The workqueue forgets the key (resets backoff counter). The reconciler will only wake up again on the next watch event or resync. |
Result{Requeue: true}, nil |
Success, but reconcile me again immediately. Subject to the workqueue rate limiter. |
Result{RequeueAfter: 30*time.Second}, nil |
Success, reconcile me again after exactly 30 s. Bypasses the rate limiter - use this for polling external systems. |
Result{}, err |
Failure. The key is requeued with exponential backoff (default: 5 ms base, doubling, 1000 s cap; global 10/s with burst 100). |
This is the single most common interview question on Operators, and the
single most common bug in newbie code (returning an error to "retry later"
instead of RequeueAfter).
How does the reconcile loop get woken up? — For, Owns, Watches
The pipeline above shows what happens once a key is enqueued. The next
question is who enqueues the key. In controller-runtime, you declare the
event sources your reconciler subscribes to in SetupWithManager(), the
function kubebuilder scaffolds for every controller:
func (r *PostgresClusterReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&acmev1.PostgresCluster{}). // primary
Owns(&appsv1.StatefulSet{}). // owned child
Owns(&corev1.Service{}). // owned child
Watches(&corev1.ConfigMap{}, handler.EnqueueRequestsFromMapFunc(r.mapConfigMap)).
WithEventFilter(predicate.GenerationChangedPredicate{}). // spec-only changes
Complete(r)
}Three subscription primitives, each picks a different event source:
| Primitive | When to use it | What it enqueues |
|---|---|---|
For(&PrimaryKind{}) |
The CR your controller owns. Every controller must have exactly one. | Events on the primary CR itself → the CR's own key. |
Owns(&ChildKind{}) |
Child resources you create with SetControllerReference, e.g. a StatefulSet your reconciler renders from spec. |
Events on the child → the owning CR's key (via the owner reference walked by EnqueueRequestForOwner). |
Watches(&UnrelatedKind, handler) |
Foreign objects you read but do not own — e.g. a ConfigMap referenced by CR.spec.configMapRef. |
Events on the foreign object → whatever keys your custom MapFunc returns. |
Owns is just sugar for Watches with the EnqueueRequestForOwner handler
pre-wired. Predicates such as GenerationChangedPredicate wrap all of
these and decide whether the event makes it onto the queue at all —
GenerationChangedPredicate only enqueues when .metadata.generation
changes (which Kubernetes only bumps for .spec writes, not .status
writes), making it the standard fix for the status hot loop we cover in the
anti-patterns section below.
For the predicate menu (GenerationChanged, ResourceVersionChanged,
LabelSelector, AnnotationChanged, etc.) and the decision matrix for
Owns vs Watches in real controllers, see the dedicated guide on
Watches, events, and predicates.
For the pattern of reconciling many child resources per CR, see
Multi-resource reconciliation.
Idempotency - the contract you cannot break
Your Reconcile() function will be called many times for the same desired state. Three reasons:
- The informer's periodic resync (default 10 hours in controller-runtime) wakes every cached object whether anything changed or not.
- Any
RequeueAfteryou set forces another call. - A child resource owned by your CR (a Pod, Service, PVC) firing an update
event will wake the parent reconciler if you used
Owns().
That means your reconcile must be idempotent - calling it ten times in a
row with the same .spec must produce the same outcome as calling it once.
In practice:
- Use
controllerutil.CreateOrUpdateto converge child resources, never rawCreate()(which fails on the second call withAlreadyExists). - Compute the desired child object from
.specevery time. Do not cache state between reconciles - if the controller pod restarts, in-memory state is gone. - Update
.statusonly when the new value actually differs - more on this in the anti-patterns section below.
Concurrency - what runs in parallel and what doesn't
controller-runtime gives you exactly the concurrency guarantee you want:
- Per-key serialization. A single resource key (
namespace/name) is reconciled by at most one goroutine at a time. The workqueue's processing set blocks new dequeues of an in-flight key until the first reconcile returns. - Cross-key parallelism. Different keys reconcile in parallel up to
MaxConcurrentReconciles. The default is 1 in controller-runtime - so even your different Pods reconcile serially out of the box. Tune via:
ctrl.NewControllerManagedBy(mgr).
For(&acmev1.PostgresCluster{}).
WithOptions(controller.Options{MaxConcurrentReconciles: 4}).
Complete(r)The right value depends on how IO-heavy your reconcile is. Typical production values are 4-10 for stateful workloads, higher for cluster-scoped operators with thousands of objects.
You almost never need locks inside Reconcile() because of the per-key guarantee. You do need to be careful about shared state outside the reconciler (caches, counters, recorders) - those run on multiple goroutines across keys.
Note that MaxConcurrentReconciles only governs goroutines inside a single
operator process. When you run multiple replicas of your operator (the
standard HA topology), you also need
leader election so that only one
replica is actively reconciling at a time — otherwise both replicas race on
the same workqueue keys and you re-introduce all the concurrency hazards
controller-runtime tried to eliminate.
The cache resync - and why your reconciler runs at 3 am
A confusing observation when you watch operator logs: reconciles happen at seemingly random times even when nothing changed. That is the informer resync - a periodic re-fire of "synthetic" update events for every cached object so your reconciler can correct any drift the watch may have missed.
In controller-runtime the default is time.Hour * 10. You can override per
manager (ctrl.Options{Cache: cache.Options{SyncPeriod: ...}}) but it is rarely worth shortening - your
watches are already real-time, and a shorter resync just amplifies load on
both the cache and your reconciler. The
kubebuilder book
covers this in the cronjob tutorial. For the patterns operators use to
notice and correct external drift between resyncs (status diffing,
spec-vs-cluster hashing, periodic RequeueAfter), see
Drift detection patterns in operators.
The five anti-patterns that produce hot loops
This is where production operators die. In rough order of how often they happen:
-
Status hot loop. You call
Status().Update()on every reconcile, even when the value did not change. The update triggers a watch event, which triggers another reconcile, which writes status again. Fix: read the current.status, compare field-by-field, and only call Update when different. Or setGenerationChangedPredicateto wake the reconciler only on spec changes. -
Returning
errorfor routine retries. If you want to re-check in 30 seconds, returnResult{RequeueAfter: 30*time.Second}, nil, notnil, fmt.Errorf("not ready yet"). Errors trigger exponential backoff that compounds over time; you do not want a "wait 17 minutes" backoff for a non-error condition. -
Long-running work inside Reconcile(). Your reconciler is one of N workers. If you sleep, dial an external API with a 30-second timeout, or wait for a Pod to come up, the worker is blocked. Fix: kick off the work, write what you started to
.status, and returnResult{RequeueAfter: t}to check progress next time. -
Polling instead of watching. If you need to react to changes on a Pod, watch the Pod via
Owns(&corev1.Pod{})- do not loop a Get every 5 seconds. The framework is built for watches; everything else is wrong. -
Side effects without idempotency. Sending a Slack notification or incrementing an external counter inside Reconcile() will fire many times per logical event. Either dedupe with a
.status.lastNotifiedHashfield, or move the side effect to anEventRecorderevent that is naturally deduplicated.
Anti-pattern cheat sheet
| Symptom | Root cause | Fix |
|---|---|---|
| Reconcile fires every few seconds with no spec change | Status hot loop | Diff .status before Status().Update(), or apply GenerationChangedPredicate |
etcd write rate climbs after a config change |
Status hot loop or Result{Requeue: true} in a steady state |
Same as above; drop the Requeue: true when nothing is in flight |
| Backoff stretches to many minutes between reconciles | return err used for "not ready yet" |
Return Result{RequeueAfter: t}, nil instead |
| One reconcile blocks all others on the same controller | Long-running work (sleep, HTTP wait, exec) inside Reconcile() |
Kick off async work, store progress in .status, return RequeueAfter |
| Reconciler does not react to Pod state changes | Polling client.Get(Pod) on a timer |
Subscribe via Owns(&corev1.Pod{}) in SetupWithManager |
| Slack notification fires repeatedly for the same event | Side effect without dedup | Track lastNotifiedHash in .status or use EventRecorder |
Picking the right operator pattern up front saves you from most of these — see the Operator design patterns catalogue.
A real, idempotent reconciler in Go
Putting it all together. This is the shape kubebuilder scaffolds for every
new controller — a production-quality reconciler with status-update-on-change,
CreateOrUpdate for the child, and all three success return paths exercised:
func (r *PostgresClusterReconciler) Reconcile(
ctx context.Context, req ctrl.Request,
) (ctrl.Result, error) {
log := log.FromContext(ctx)
var cluster acmev1.PostgresCluster
if err := r.Get(ctx, req.NamespacedName, &cluster); err != nil {
return ctrl.Result{}, client.IgnoreNotFound(err)
}
desiredSS := r.buildStatefulSet(&cluster)
if err := ctrl.SetControllerReference(&cluster, desiredSS, r.Scheme); err != nil {
return ctrl.Result{}, err
}
op, err := controllerutil.CreateOrUpdate(ctx, r.Client, desiredSS, func() error {
desiredSS.Spec.Replicas = &cluster.Spec.Replicas
return nil
})
if err != nil {
return ctrl.Result{}, err // transient -> backoff
}
log.Info("statefulset reconciled", "op", op)
newStatus := r.computeStatus(ctx, &cluster)
if !equality.Semantic.DeepEqual(cluster.Status, newStatus) {
cluster.Status = newStatus
if err := r.Status().Update(ctx, &cluster); err != nil {
return ctrl.Result{}, err
}
}
if newStatus.Phase != "Ready" {
return ctrl.Result{RequeueAfter: 30 * time.Second}, nil
}
return ctrl.Result{}, nil
}The five rules to notice:
client.IgnoreNotFound— the CR may have been deleted between the watch event and your reconcile.SetControllerReference— so the StatefulSet gets garbage-collected when the CR is deleted. See owner references and garbage collection for the full mechanics (controller: truevsblockOwnerDeletion, foreground vs background propagation, etc.).CreateOrUpdate— idempotent merge of the desired child. This is the traditional approach; for new controllers, prefer Server-Side Apply (SSA), which tracks per-field ownership and avoids the read-modify-write race thatCreateOrUpdateis prone to under heavy concurrency.- Status update only on change — diffed via
equality.Semantic.DeepEqualto avoid the hot loop. Combine withGenerationChangedPredicateinSetupWithManagerif your reconciler does not need to react to its own status writes at all. RequeueAfterfor "not ready yet" — neverreturn errfor a non-error condition.
Frequently Asked Questions
1. What is the reconcile loop in Kubernetes?
2. How often does the reconcile loop run?
3. What is the difference between level-triggered and edge-triggered control?
4. What happens when Reconcile returns an error?
5. What is the difference between Requeue and RequeueAfter?
6. Can the same custom resource be reconciled in parallel?
7. Why is my operator stuck in a reconcile hot loop?
8. What is GenerationChangedPredicate and when should I use it?
9. When should I use Owns() vs Watches() in SetupWithManager?
What's next?
Once the reconcile loop clicks, everything else in the Operator world is just elaboration of these primitives:
- Why level-triggered? Read Desired state vs actual state for the design rationale behind this whole pattern.
- Status & Conditions — the proper way to communicate progress back to users. See Status subresource and Conditions explained.
- Finalizers — the two-phase delete pattern that uses the reconcile loop for cleanup. See Finalizers in Kubernetes.
- CRDs in depth — the OpenAPI schema, printer columns, conversion webhooks. See Custom Resource Definitions explained.
- Wiring up the loop — controller-runtime architecture
walks the Manager, Cache, Informer, and Workqueue in detail, and
Watches, events, and predicates
covers
OwnsvsWatches,GenerationChangedPredicate, and the rest of the predicate menu. - Running it safely in production — pair the loop with leader election so only one replica reconciles at a time and least-privilege RBAC so a buggy reconcile cannot escalate cluster-wide.
- Pick the right shape for your operator — Operator design patterns and Operator maturity model help you decide how much your reconciler should actually do.
- Ready to build? Install Operator-SDK on Linux and you will be writing reconcilers like the one above inside an hour.
Looking for the bigger picture? The Kubernetes Operator tutorial sequences every article in this series in pedagogical order — this article is the foundation the rest of the chapters build on.
Official references
- Kubernetes Controllers
- controller-runtime Reconcile package
- client-go workqueue
- Kubebuilder controller implementation
