A single replica of your operator works fine until the node it runs
on reboots, the pod gets evicted, or you roll out a bad image. The
cluster then has no operator running, and CRs sit unreconciled
until kubelet restarts something elsewhere — minutes of silent
drift while reconcile work piles up. The fix is more than one
replica, but two replicas of the same controller fighting over the
same CRs is a recipe for split-brain. Leader election is what
reconciles those two facts: run controller-runtime ha replicas
for availability, but let exactly one be active at any time.
This article covers the lease-based lock, the four manager options, the three timing knobs, the Downward API pattern for clean lease identities, and how to actually test failover.
TL;DR — operator leader election in 60 seconds
Three changes to enable leader election in a kubebuilder-scaffolded
operator (most of which kubebuilder init already wires for you):
// main.go
mgr, err := ctrl.NewManager(cfg, ctrl.Options{
LeaderElection: true,
LeaderElectionID: "memcached-operator.cache.example.com",
LeaderElectionResourceLock: "leases", // default since Kubernetes 1.20
LeaderElectionReleaseOnCancel: true,
})# config/manager/manager.yaml
spec:
replicas: 2 # or 3 - any number ≥ 2
template:
spec:
containers:
- name: manager
args:
- --leader-elect=true # kubebuilder scaffolds this flag# config/rbac/leader_election_role.yaml — scaffolded by kubebuilder
- apiGroups: ["coordination.k8s.io"]
resources: ["leases"]
verbs: ["get","list","watch","create","update","patch","delete"]Now kubectl get pods -n memcached-operator-system shows two
replicas; kubectl get lease -n memcached-operator-system shows
one kubernetes lease coordination api object whose
holderIdentity is the active leader. The rest of this article
explains the lease object in detail, the four manager options, the
three timing knobs, the Downward API trick for clean lease
identities, the pitfall cheat sheet, and how to actually test
failover.
A quick analogy: the on-call pager
A 24/7 ops team has a pager. The rules:
- Exactly one person holds the pager at any time. That person answers all incidents.
- The pager is handed off every shift. The new holder explicitly takes over.
- If the pager-holder is unreachable for 15 minutes, someone else picks it up. The team posts a Slack message ("@on-call missing — taking over") and the new person becomes the pager-holder.
Map this to leader election:
| Pager rotation | Operator leader election |
|---|---|
| The pager (a single physical object) | A Lease object in etcd |
| Holding the pager | Being the active leader |
| Hand-off at shift change | Graceful release on shutdown |
| "Unreachable for 15 min → pick it up" | LeaseDuration timeout → another replica wins |
| Multiple ops staff, only one paged | Multiple replicas, only one runs controllers |
The lease is the pager. The Kubernetes API server is the message board where the lease's holder is announced.
Prerequisites
- A working operator currently running with
replicas: 1(the default scaffolded bykubebuilder init/operator-sdk init). - Familiarity with the controller-runtime architecture — the Manager is what owns the election loop and what controllers hang off of.
- An understanding of
the operator's RBAC —
leader election needs
coordination.k8s.io/leasescreate/get/update permissions on the operator's namespace. - Optional: Prometheus metrics for visibility into the failover.
Why leader election matters
Three reasons running a single-replica operator in production is the wrong default:
1. Availability — a single replica is a single point of failure
Every operator pod is the only thing reconciling its CRs. When that pod restarts (node drain, kernel oops, bad image rollout), the reconcile loop is silent for the duration. On a healthy cluster that is 10–30 seconds; on an unhealthy one (no available nodes, image pull failure, scheduler backoff) it can be minutes — long enough for SLOs to break and for drift to accumulate on every CR the operator manages.
2. Coordination — two replicas without leader election will fight
Running replicas: 2 without leader election is worse than
running replicas: 1. Both controllers observe the same CRs, both
try to write .status, both try to add/remove the same
finalizers, both compete for
the same
.status.conditions field
manager — and the API server returns a steady stream of 409 Conflict errors. Even with
Server-Side Apply holding
field ownership constant, two field managers writing identical
state still racks up retries and obscures the real reconcile
history. Leader election makes "one writer at a time" a structural
guarantee.
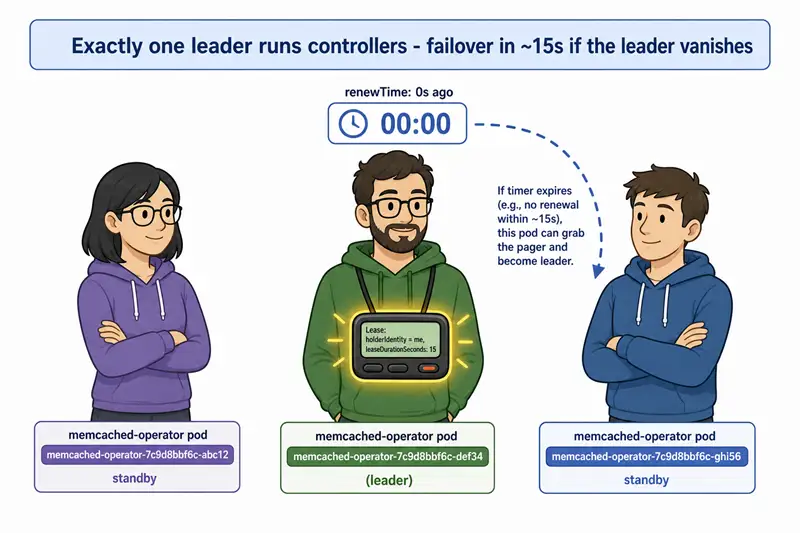
3. Failover is bounded, not optional
With leader election enabled, failover is bounded by `LeaseDuration
- RetryPeriod` — ~17 seconds on defaults, and configurable. Without it, failover is bounded by "however long it takes to schedule a fresh pod" — which is unbounded under cluster pressure. The whole point is to convert an availability problem (waiting for a fresh pod) into a latency problem (waiting one lease duration).
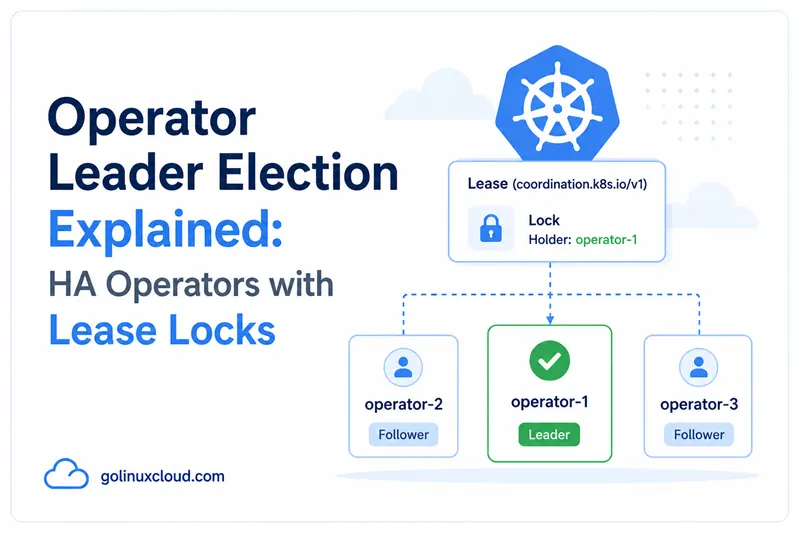
Step 1: What the Lease object looks like
After leader election starts, the cluster has a Lease like this:
kubectl get lease memcached-operator.cache.example.com -n memcached-operator-system -o yamlapiVersion: coordination.k8s.io/v1
kind: Lease
metadata:
name: memcached-operator.cache.example.com
namespace: memcached-operator-system
spec:
holderIdentity: memcached-operator-controller-manager-7c9b-abc12_a1b2c3d4-...
leaseDurationSeconds: 15
acquireTime: "2026-06-01T07:42:11.123456Z"
renewTime: "2026-06-01T07:55:33.456789Z"
leaseTransitions: 3Five fields with concrete meaning:
| Field | Meaning |
|---|---|
holderIdentity |
The leader's stable name + a per-process UID. The pod name is in there if you wired the Downward API. |
leaseDurationSeconds |
The leader has to renew within this window or someone else takes over. |
acquireTime |
When this leader first acquired the lease. |
renewTime |
When the leader last renewed. The lease is "alive" until renewTime + leaseDurationSeconds. |
leaseTransitions |
How many times leadership has changed hands. A high number on a small cluster is suspicious — probably a flaky leader. |
The whole election protocol is implemented as atomic updates of
this one object. Whoever can update the Lease (with the right
resourceVersion) becomes the holder. Everyone else loses the race
and retries.
Step 2: The election loop, conceptually
Inside controller-runtime, the
Manager runs a small loop on every replica from the moment
mgr.Start(ctx) is called:
loop forever:
lease = Get(LeaseName)
if lease does not exist:
Create(lease, holder = me) # I am now the leader
elif lease.renewTime + leaseDurationSeconds > now:
# Lease is alive
if lease.holder == me:
UpdateRenewTime(lease, now) # I keep being the leader
else:
sleep(RetryPeriod) # Stand by
else:
# Lease expired - claim it
Update(lease, holder = me) # I am now the leader
sleep(RetryPeriod or RenewDeadline)The same loop drawn as a state machine — every replica is always in exactly one of these states, and the only way between them is an atomic update to the Lease object in etcd:
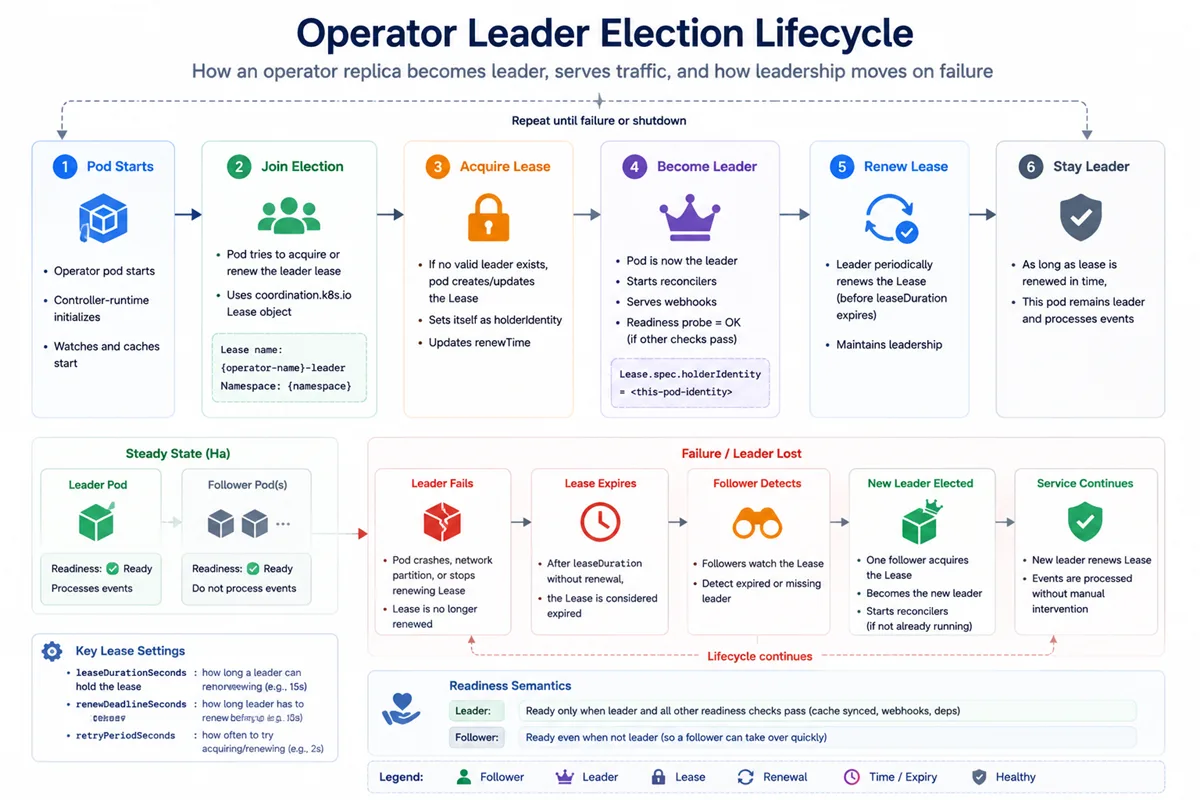
Every transition is a single atomic update to the Lease object — the API server's optimistic-locking is what guarantees there is at most one Leader at any instant.
Three things to internalise:
- All "elections" are races to update an etcd object. Whoever wins the API server's optimistic-locking race becomes the leader.
- Only the active leader runs controllers. Non-leaders run nothing useful — they just keep trying to acquire the lease.
- Failover is bounded by
LeaseDuration. When the leader vanishes, the longest a standby will wait is roughlyLeaseDuration + RetryPeriod(default 17 s).
Step 3: The four manager options
| Option | Type | Purpose |
|---|---|---|
LeaderElection |
bool |
Master switch — turns the whole thing on |
LeaderElectionID |
string |
The Lease's name; must be unique per controller |
LeaderElectionNamespace |
string |
Namespace the Lease lives in (defaults to the operator's own) |
LeaderElectionResourceLock |
string |
Lock backend: leases (default), configmaps, endpoints |
LeaderElectionReleaseOnCancel |
bool |
Whether the leader explicitly releases on shutdown |
LeaderElectionID
Treat it like a global identifier for this operator:
LeaderElectionID: "memcached-operator.cache.example.com"Rules:
- DNS-compatible (lowercase, dots and dashes OK, no underscores).
- Stable across releases. Renaming triggers a brief "no leader" window while old replicas hold the old name and new replicas hold the new one.
- Unique within the cluster if two different operators happen to use the same namespace. Defensive practice: include the API group as a suffix.
LeaderElectionNamespace
By default, the Lease is created in the same namespace as the
operator's pod. Override if you need cross-namespace leadership —
for example, an operator pod running in kube-system whose Lease
should live somewhere the cluster admins watch.
LeaderElectionReleaseOnCancel: true
A subtle but important quality-of-life flag. When true:
- On SIGTERM, the leader sends an update setting itself as the former holder (effectively expiring the lease now).
- The next replica picks up leadership in
RetryPeriod(~2 s) instead of waiting forLeaseDuration(~15 s) to expire.
This is the leaderelectionreleaseoncancel rolling deploy
pattern, and it is what you want for fast rolling deploys. Without
it, every rolling restart adds 15 s of "no leader" downtime — long
enough that one missed reconcile per deploy is realistic on a busy
cluster.
Step 4: The three timing knobs
LeaseDuration, RenewDeadline, RetryPeriod. The defaults
(15 s / 10 s / 2 s) are conservative and fine for almost
everything. They live in the underlying
leaderelection.LeaderElectionConfig:
import "k8s.io/utils/ptr"
mgr, _ := ctrl.NewManager(cfg, ctrl.Options{
LeaderElection: true,
LeaderElectionID: "memcached-operator.cache.example.com",
LeaderElectionReleaseOnCancel: true,
LeaseDuration: ptr.To(30 * time.Second), // override
RenewDeadline: ptr.To(20 * time.Second),
RetryPeriod: ptr.To(5 * time.Second),
})The one invariant that must always hold:
RetryPeriod<RenewDeadline<LeaseDurationViolating it produces split-brain windows or wedged leaders. The client-go
leaderelectionpackage validates this at startup and refuses to start with mis-ordered values — but it is still worth understanding why, because every choice on these three knobs is a trade-off between failover speed and tolerance for API jitter.
LeaseDuration— how long until the lock "expires" after the last renew. Shorter = faster failover but more API server pressure.RenewDeadline— the leader gives up its own claim if it cannot renew within this time. Shorter than LeaseDuration guarantees that a slow/partitioned leader steps down before someone else takes over (preventing split-brain).RetryPeriod— how often non-leaders retry, and how often the leader renews. Lower values mean faster failover but more API calls per replica.
When should you tune them?
- Fast failover (5/3/1 s) — only for sub-10s-failover-critical operators on extremely reliable clusters. The trade-off is more API calls per replica per minute and more sensitivity to API server hiccups.
- Lazy failover (60/40/10 s) — for very stable workloads where rare API server outages should not cause leadership flips. Don't go past 60 s without a good reason.
Step 5: Readable pod identity via the Downward API
By default, controller-runtime derives the lease holder identity from os.Hostname() (which is the pod name in
Kubernetes) plus a per-process UUID. That already makes the Lease
holder kubectl-greppable:
memcached-operator-controller-manager-7c9b-abc12_a1b2c3....
The Downward API is still useful when you want the same pod name available to your own logs, metrics, or health handlers:
spec:
template:
spec:
containers:
- name: manager
env:
- name: POD_NAME
valueFrom: { fieldRef: { fieldPath: metadata.name } }
- name: POD_NAMESPACE
valueFrom: { fieldRef: { fieldPath: metadata.namespace } }In main.go:
podName := os.Getenv("POD_NAME")
if podName == "" {
podName, _ = os.Hostname()
}Use podName in your own structured logs. It does not override
controller-runtime's Lease identity; in current controller-runtime
that identity is constructed inside the leader-election resource
lock. Overriding it requires a custom
LeaderElectionResourceLockInterface, which is rarely worth it for
ordinary operators.
Step 6: Watching the failover
Two terminals, run side by side.
Terminal 1 — watch the Lease:
kubectl get lease memcached-operator.cache.example.com -n memcached-operator-system -wYou should see a row updated every ~2 s (the active leader's
renew). Note the HOLDER column.
Terminal 2 — kill the leader (Linux / macOS shell — on Windows
PowerShell, split holderIdentity on _ manually):
LEADER=$(kubectl get lease memcached-operator.cache.example.com -n memcached-operator-system -o jsonpath='{.spec.holderIdentity}' | awk -F_ '{print $1}')
kubectl delete pod $LEADER -n memcached-operator-systemWatch the Lease again. Within ~15 s, the HOLDER column flips
to the standby replica's name. Within another second the new leader
starts logging "starting workers".
Watching with kubectl events
A more readable alternative to parsing the lease object is to tail
events scoped to the Lease — controller-runtime emits a
LeaderElection event each time leadership changes hands:
kubectl events -n memcached-operator-system \
--for lease/memcached-operator.cache.example.com --watchLAST SEEN TYPE REASON OBJECT MESSAGE
0s Normal LeaderElection Lease/memcached-operator.cache.example.com memcached-operator-controller-manager-7c9b-xyz12_a1b2... became leaderProduction should also alert on the lease transitions counter
(leader_election_master_status from controller-runtime metrics,
or the leaseTransitions field on the Lease itself) climbing
unexpectedly — a slow steady climb means a flaky leader, while a
single bump per deploy is the expected pattern.
Step 7: Standby behaviour
Standby replicas:
- Still run the
Manager's health/metrics HTTP server. Useful so they pass readiness probes during a deploy. - Still expose
/metrics,/healthz,/readyz— Prometheus doesn't care which replica holds the lease. - Do not start controllers and do not subscribe to watches:
the Manager's
LeaderElectionRunnables(including the informer cache) only start once the lease is acquired. - Are essentially "idle until needed".
A subtle but important implication: standbys do not warm their
informer cache. On failover, the new leader's first reconciles are
slightly slower while the cache catches up (typically 1–3 s on a
healthy cluster) — which is also why standbys should still report
ready: marking them not-ready does not help here and only widens
the no-traffic window. For tight SLOs, consider running specific
read-only Runnables with RunNonLeaderElected: true so they warm
in the background, but never do this for reconcilers that
mutate state (it defeats the whole point of leader election).
If your operator uses Server-Side Apply for writes, leader election is doubly important: SSA tracks field ownership by
fieldManager, and two replicas applying with the samefieldManagerwill still produce a fight-then-converge pattern rather than the clean single-writer story SSA is designed for. Pick one strategy — leader election with a singlefieldManager, or sharding with per-shard managers — never both writers at once.
Step 8: When NOT to use leader election
A few cases where single-replica is the right call:
- Stateless operators with very fast reconciles. A 100 ms
reconcile time on 10 CRs means failover takes ~17 s — about as
long as just starting a fresh pod from scratch. Two replicas with
no leader election (and accepting split-brain risk) is not
acceptable; one replica with
restartPolicy: Alwaysand a fast startup is fine. - Dev / lab environments. Leader election just complicates
make run. Disable in dev (--leader-elect=false), enable in staging/prod. - Operators with intentional sharding. If you partition CRs by label and run N replicas, each handling its slice, leader election is unnecessary — they aren't competing for the same CRs. See operator multi-tenancy patterns.
For everything else — managed workloads, lifecycle CRs, anything where state coherence matters — leader election is non-optional in production.
Common pitfalls
1. Two operators sharing the same LeaderElectionID
Symptom: both operators silently fight over the lease, neither
makes consistent progress. Fix: include the API group in the ID
(memcached-operator.cache.example.com).
2. RBAC missing for leases
Symptom: leader election immediately fails with leases.coordination.k8s.io "..." is forbidden. Fix: ensure the Role/RoleBinding for the
operator's ServiceAccount includes lease permissions.
3. Forgetting LeaderElectionReleaseOnCancel
Every rolling restart causes ~15 s of "no leader". The next replica
takes over after LeaseDuration expires. Fix: set
LeaderElectionReleaseOnCancel: true so leaders release the lease
explicitly on SIGTERM.
4. Aggressive timings on flaky clusters
You set LeaseDuration: 3 * time.Second. Every API server hiccup
flips leadership. The reconcile metric is now a sawtooth.
Fix: revert to defaults; if you need fast failover, fix the API
server flakiness first.
5. Two-replica deploy without leader election
Symptom: both reconcilers write to the same CR, conflicts everywhere,
finalizers fight, operator
logs full of Conflict errors. Fix: either set replicas: 1, or
enable leader election. Never two of the same controller without
coordination.
Pitfall cheat sheet
| Symptom | Root cause | Fix |
|---|---|---|
| Two operators in the same namespace silently fight, neither makes progress | Pitfall 1 — both use the same LeaderElectionID |
Suffix the ID with the API group (memcached-operator.cache.example.com) |
Operator crashes at startup with leases.coordination.k8s.io "..." is forbidden |
Pitfall 2 — RBAC for coordination.k8s.io/leases missing |
Apply the leader_election_role.yaml from kubebuilder scaffold |
| Every rolling deploy has ~15 s of "no leader" | Pitfall 3 — LeaderElectionReleaseOnCancel: false (or unset) |
Enable LeaderElectionReleaseOnCancel: true |
| Leadership flips every few minutes on a healthy cluster | Pitfall 4 — LeaseDuration set aggressively (<5 s) on a non-perfect API server |
Revert to defaults (15/10/2 s); fix API server latency before tuning |
Operator log full of 409 Conflict errors, finalizers added and removed in a loop |
Pitfall 5 — two replicas, no leader election | Enable leader election, or scale to replicas: 1 |
leaseTransitions counter grows steadily even with no deploys |
Slow/partitioned leader can't meet RenewDeadline |
Check the leader's CPU throttling and API latency before tuning timings |
Frequently Asked Questions
1. Why does an operator need leader election?
2. What is a Lease in Kubernetes?
coordination.k8s.io/v1.Lease is a tiny lightweight object whose only purpose is to record "who holds this lock right now, and when does the lock expire". Leader election uses one Lease per controller-manager: each replica fights to write itself as the holder; whoever wins becomes the leader.3. How do I enable leader election in controller-runtime?
ctrl.Options.LeaderElection: true plus a unique LeaderElectionID (a DNS-compatible name like memcached-operator.cache.example.com). The Manager creates the Lease in the operator's namespace and runs the election loop automatically. No extra code needed in the reconciler.4. What are LeaseDuration, RenewDeadline, RetryPeriod?
LeaseDuration (default 15s) is how long the lock stays valid after the last successful renew - i.e. how long until a dead leader is forgotten. RenewDeadline (default 10s) is how long the leader has to renew before it gives up its own claim. RetryPeriod (default 2s) is how often non-leaders try to acquire the lock. Defaults are fine; tune only if you understand the failover-vs-stability trade-off.5. What lock backend types are available?
leases (recommended, default since Kubernetes 1.20), configmaps, and endpoints. The latter two are legacy and still work, but leases is purpose-built (it uses the coordination.k8s.io API, less API server noise). Always use leases unless you are integrating with very old tooling.6. Can the standby replicas do anything?
LeaderElectionReleaseOnCancel option ensures the leader gives up the lease quickly on shutdown (rather than waiting LeaseDuration to expire). Some manager setups (mostly cluster-api) run some "always-on" work even on non-leaders by passing RunNonLeaderElected: true to specific Runnables.7. How do I get a stable identity for the lease holder?
POD_NAME with the Downward API only if you want to use the same readable pod name in your own logs or metrics; it does not change the Lease holderIdentity unless you replace the leader-election resource lock yourself.8. How do I test leader-election failover?
kubectl get lease <id> -w. Kill the leader with kubectl delete pod <leader-name>. Within LeaseDuration + RetryPeriod (~17 s with defaults) one of the standbys becomes the new leader. Test that no duplicate reconciles happen by checking your reconcile metrics.9. Why does my non-leader replica still use CPU and memory?
controller-runtime Manager (the HTTP server for /metrics, /healthz, /readyz), the leader-election loop (a Lease Get + sleep every RetryPeriod), and any RunNonLeaderElected: true Runnables you registered. They do not run controllers and do not warm the informer cache, so memory is small (typically 30-80 Mi) and CPU is tiny (1-5 m per replica), but it is non-zero. Budget for it in your Deployment requests and limits.10. Do I still need leader election if I use sharding?
LeaderElectionID. See operator multi-tenancy patterns for the full sharding playbook.Summary
Leader election is the standard pattern for high-availability
operators: enable LeaderElection: true with a unique
LeaderElectionID, use the leases backend, set
LeaderElectionReleaseOnCancel: true for fast rolling deploys,
deploy with replicas: 2 or 3, and accept the 15-second worst-
case failover window. The defaults work; tune the timings only when
you know exactly which trade-off you are buying.
For most operators, leader election is the difference between "the operator goes down whenever a node reboots" and "the operator keeps reconciling because there's always another replica ready."
Further reading
where the Manager that owns the election loop also owns the
cache, the webhook server, and the health probe bind-address.
the probes that decide which replica is healthy enough to lead,
and why both standby and leader should report ready.
the coordination.k8s.io/leases permissions leader election
requires.
the loop that runs only on the leader, and why missing it for
a LeaseDuration window matters.
the status writes that two leaderless replicas would fight over.
the canonical split-brain failure mode without leader election.
the writer-side reason a single fieldManager (and therefore a
single leader) matters.
when sharding can replace leader election entirely, and when it
cannot.
monitoring leader_election_master_status and the
leaseTransitions counter.
the full series; this article sits in the operability chapter
alongside probes, RBAC, and metrics.
- External: Kubernetes Lease docs and client-go leaderelection reference.
