If your Kubernetes Operator creates
anything outside its own namespace — a cloud volume, a DNS record, an
external SaaS API call, or even a Kubernetes resource in another cluster —
it almost certainly needs a finalizer.
Without one, a user runs kubectl delete mykind sample, Kubernetes
immediately removes the object from etcd, your controller never gets a
chance to clean up the side-effects, and you have just created an orphaned
resource leak.
Finalizers are the canonical Kubernetes mechanism for safe cleanup, and they
are conceptually simple — a string on metadata.finalizers that the API
server refuses to ignore. The mechanics, on the other hand, are subtle:
getting them wrong gives you stuck "Terminating" objects, hot reconcile
loops on deletion, or worse, silent skipping of cleanup logic.
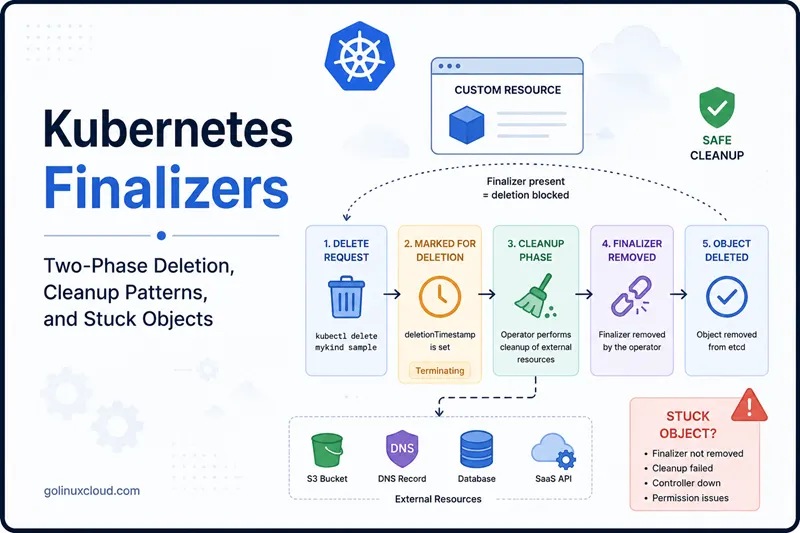
The two-phase deletion model. A
kubectl deleteis a request; the actual removal from etcd happens only after every finalizer has been cleared by its owning controller.
If you have not yet read the reconcile loop explained, that article is a prerequisite — finalizers reuse the same control loop you already know.
TL;DR — how finalizers work
A finalizer is a string in metadata.finalizers that protects an object
from immediate deletion. The full lifecycle, in six steps:
- User runs
kubectl delete mykind sample. - API server sees a non-empty
finalizersarray, refuses to delete from etcd. Instead it stampsmetadata.deletionTimestampwith the current time. - Every watch fires — your controller reconciles and notices that
deletionTimestampis set. - Controller runs cleanup logic (delete external DNS record, drop cloud disk, call vendor API, etc.).
- Controller removes its finalizer string from
metadata.finalizersand writes the object back. - API server sees
finalizersis now empty and finally garbage-collects the object from etcd.
A user who ran
kubectl delete -wwill see the object stuck inTerminatingbetween steps 2 and 6. That is correct behaviour — the object is being deleted, the API server is just waiting for the controller to give it the go-ahead.
This pattern is mandatory for any Operator that has external side-effects. For an Operator that only manages other Kubernetes resources, ordinary owner references and cascade deletion are usually enough.
Two-phase deletion in detail
The six steps above collapse into a simpler mental model: deletion is a two-phase process, not a single operation.
When a user runs:
kubectl delete mykind sampleKubernetes does not immediately remove the object from etcd. Instead, the API server first checks whether the object contains any entries in metadata.finalizers. If a finalizer exists, deletion is paused and the object enters a special Terminating state. This gives the owning controller an opportunity to perform any required cleanup before the object disappears permanently.
Concretely, before deletion the object looks like this:
metadata:
finalizers:
- backups.acme.io/finalizerImmediately after kubectl delete backup sample, the object is still there — only with a deletionTimestamp stamped on it:
metadata:
deletionTimestamp: "2026-06-01T12:34:56Z"
finalizers:
- backups.acme.io/finalizerThe API server has not removed anything from etcd; it has only marked the object for deletion and is now waiting for the controller to remove the finalizer.
The following diagram shows the complete lifecycle, from the object's creation through kubectl delete to the final etcd removal:
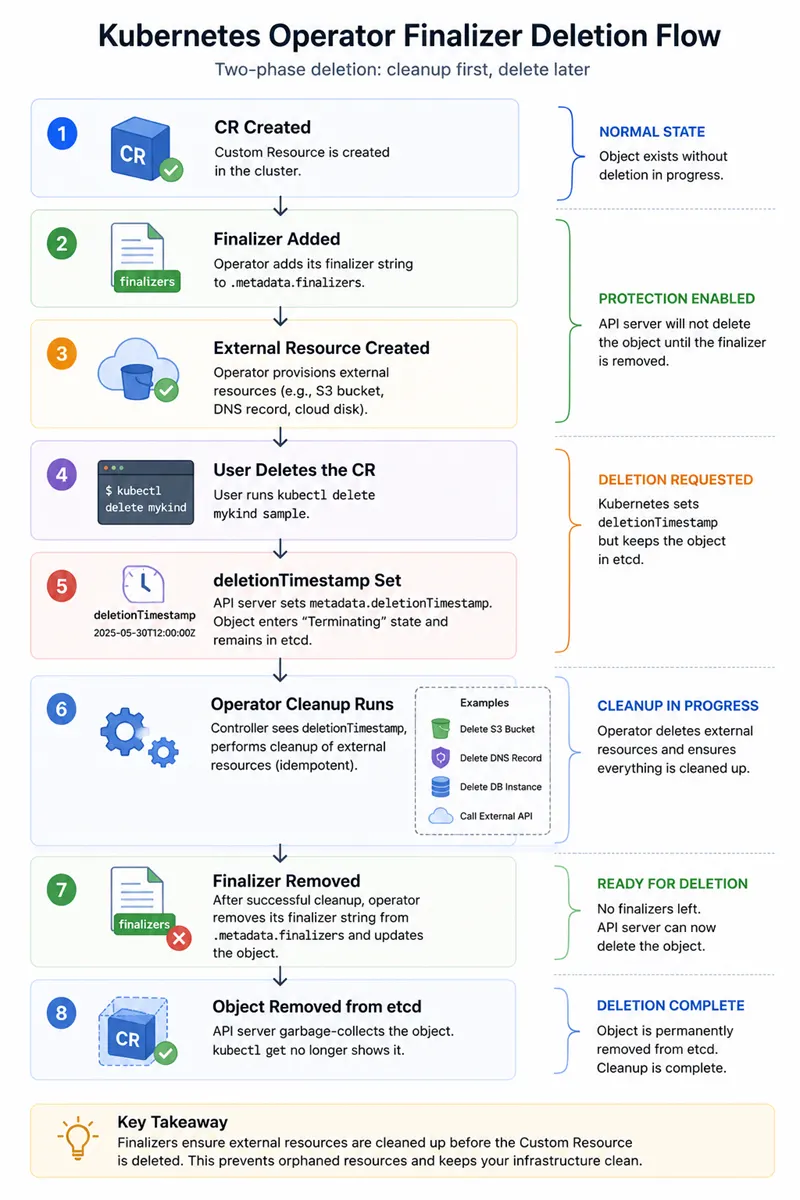
The eight-step lifecycle of a finalizer-protected Custom Resource, with the controller's cleanup phase highlighted.
The critical point is that kubectl delete is only a deletion request, not the actual deletion. Once deletionTimestamp is set:
- The object remains visible through the API.
- The object typically shows as
Terminating. - Reconcile continues to run.
- Cleanup logic can still update metadata and status.
- The API server waits for all finalizers to be removed.
Only after every finalizer has been cleared does Kubernetes perform the final garbage collection step and remove the object from etcd.
Kubernetes itself uses finalizers
You already use finalizers indirectly every day.
Consider a PersistentVolume backed by a cloud disk.
When you delete the PersistentVolume object, Kubernetes does not immediately remove it from etcd.
Instead:
- Kubernetes first deletes the underlying cloud disk.
- It waits for confirmation that cleanup succeeded.
- Only then does it remove the PersistentVolume object.
Without this protection, the PV could disappear while the expensive cloud disk continues running and generating costs.
A finalizer gives your Operator the same protection.
The API server delays deletion until your controller confirms that all external resources have been cleaned up.
Why owner references are not enough
A common question is:
If Kubernetes already has OwnerReferences and garbage collection, why do I need finalizers?
Owner references work only for Kubernetes resources that exist inside the cluster.
For example:
Memcached CR
└── Deployment
└── Service
└── ConfigMapDeleting the Memcached CR automatically deletes the child resources because Kubernetes garbage collection understands those objects.
However, Kubernetes cannot garbage-collect resources that exist outside the cluster:
Memcached CR
└── AWS S3 Bucket
└── Route53 DNS Record
└── External DatabaseThe API server has no way to delete those resources.
Finalizers allow the Operator to perform that cleanup before the CR disappears.
Rule of thumb:
- Kubernetes resources → OwnerReferences.
- External resources → Finalizers.
- Many Operators use both together.
Deletion propagation policies and finalizers
kubectl delete accepts a --cascade flag that controls how children with ownerReferences are handled when the parent goes away. All three policies interact with finalizers, but each in a different way — and one of them silently adds a finalizer of its own.
--cascade |
What happens to the parent | What happens to children | Interaction with finalizers |
|---|---|---|---|
background (default) |
Deleted immediately (subject to its finalizers) | Garbage-collected asynchronously | Your finalizer runs on the parent while children may still be alive |
foreground |
Stamped with deletionTimestamp and an implicit foregroundDeletion finalizer |
Deleted first, blocking parent removal | User finalizers cleared only after every child with a blocking ownerReference is gone |
orphan |
Deleted immediately | Left alone, ownerReferences stripped |
Parent finalizers still run; children become standalone objects |
foregroundDeletionis a finalizer the kube-controller-manager owns. If you see it inmetadata.finalizersand the object is stuckTerminating, the children are stuck, not your operator. Look at the child kinds before you blame your own cleanup code.
Use foreground deletion when your cleanup logic must observe a fully-deleted child tree — for example, an operator that mirrors child state to an external system and needs to confirm "no children remain" before tearing down the upstream representation. For most operators the default background policy is correct.
The finalizer string - convention and naming
The string itself is opaque to Kubernetes - the API server only counts how many strings are in the array. The convention is to use a domain-style name your controller owns, so there is never a collision when multiple controllers finalize the same object:
acme.io/release-cleanup
backups.acme.io/finalizer
crossplane.io/composite-resource
finalizer.cert-manager.ioYou may also see the historical short form mycontroller-finalizer in older
operators - it works, but the domain-style form is the
upstream-recommended convention
and reads better in kubectl describe. Adopt it for new code.
Three properties to aim for when picking the string:
- DNS-prefixed. Use the API group of your CRD as the prefix
(
cache.example.com/finalizer). This avoids collisions with other operators in the same cluster. - Specific. If your operator manages multiple distinct external
resources (bucket + DNS + IAM), use one finalizer string per resource
rather than a single catch-all. The API server runs them independently,
and per-resource strings make
kubectl describeself-documenting:s3.cache.example.com/bucket,dns.cache.example.com/record,iam.cache.example.com/role. - Stable. Renaming a finalizer is a migration headache - existing
objects in production carry the old name and will not match your
code's
ContainsFinalizer(..., newName). The cleanup path silently skips them and the finalizer becomes permanent. Pick the right name on day 1.
A constant (or a small block of them) in your Go package keeps the spelling honest:
const (
finalizerBucket = "s3.cache.example.com/bucket"
finalizerDNS = "dns.cache.example.com/record"
)The full Reconcile() pattern
Important:
Adding or removing a finalizer modifies
metadata.finalizers, which means you must user.Update().
r.Status().Update()only updates the status subresource and will not persist finalizer changes.
Almost every controller with finalizers follows the same skeleton. With controllerutil helpers it fits on one screen:
import (
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/controller/controllerutil"
"sigs.k8s.io/controller-runtime/pkg/client"
)
const myFinalizer = "backups.acme.io/finalizer"
func (r *BackupReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
var backup acmev1.Backup
if err := r.Get(ctx, req.NamespacedName, &backup); err != nil {
return ctrl.Result{}, client.IgnoreNotFound(err)
}
if backup.GetDeletionTimestamp().IsZero() {
if controllerutil.AddFinalizer(&backup, myFinalizer) {
if err := r.Update(ctx, &backup); err != nil {
return ctrl.Result{}, err
}
}
} else {
if controllerutil.ContainsFinalizer(&backup, myFinalizer) {
if err := r.cleanupExternalResources(ctx, &backup); err != nil {
return ctrl.Result{RequeueAfter: 30 * time.Second}, err
}
controllerutil.RemoveFinalizer(&backup, myFinalizer)
if err := r.Update(ctx, &backup); err != nil {
return ctrl.Result{}, err
}
}
return ctrl.Result{}, nil
}
return r.reconcileNormal(ctx, &backup)
}Five things to notice:
- Add the finalizer on the first reconcile, before any external
side-effect. If you create a DNS record first and the next
Updatefails, you have orphaned a DNS record before the finalizer is in place. AddFinalizerandRemoveFinalizerreturn a bool - they tell you whether the slice was mutated. Use the return to avoid pointlessUpdatewrites that trigger fresh watch events.- Cleanup is on the same code path as
RemoveFinalizer. If cleanup fails, return the error and re-reconcile; the finalizer stays in place and the object stays inTerminating. - Idempotency is mandatory. Cleanup will run again on the next reconcile
if the
RemoveFinalizerUpdate fails - your DNS-record deletion should tolerate "not found" gracefully. - No
.specchanges in the deletion branch. The API server will reject them withforbidden: only deletion is allowedbecausedeletionTimestampis set.
For why the Update and not a separate Status().Update() - finalizers
live in metadata, which the regular Update covers; the status subresource
is for .status only. See status and conditions
for the matching pattern on the status side.
An idempotent cleanup function
The cleanup function called from the deletion branch must tolerate being re-run any number of times. A workqueue retry, a controller restart, or a slow external API can all force the cleanup logic to execute again after it has already succeeded in part. Treat "already gone" upstream as a successful outcome:
func (r *MemcachedReconciler) cleanupExternalResources(
ctx context.Context, mem *cachev1alpha1.Memcached,
) error {
log := log.FromContext(ctx)
if mem.Status.ExternalBucketName == "" {
log.Info("no external bucket recorded - nothing to cleanup")
return nil
}
if err := r.s3.DeleteBucket(ctx, mem.Status.ExternalBucketName); err != nil {
if isS3NotFound(err) {
log.Info("bucket already deleted upstream",
"bucket", mem.Status.ExternalBucketName)
return nil
}
return fmt.Errorf("delete bucket %q: %w",
mem.Status.ExternalBucketName, err)
}
log.Info("deleted external bucket", "bucket", mem.Status.ExternalBucketName)
return nil
}Two takeaways worth emphasising:
- Record what you created on
.status. The cleanup path cannot know which bucket to delete unless you persisted.status.ExternalBucketName(or equivalent) when you created the bucket. Operators that manage external resources always keep an inventory on the CR's own.status. - Map "404 not found" to success. Most upstream APIs raise an error when you try to delete a resource that no longer exists; that is the exact case where you want to continue and remove the finalizer.
Atomic ordering: cleanup → confirm → remove → update
A subtle but common bug is to call RemoveFinalizer before the cleanup
result is known:
// BAD - finalizer removed first, cleanup result unverified
controllerutil.RemoveFinalizer(&mem, myFinalizer)
if err := r.cleanupExternalResources(ctx, &mem); err != nil {
return ctrl.Result{}, err
}
return ctrl.Result{}, r.Update(ctx, &mem)If cleanupExternalResources fails, the in-memory mem already has the
finalizer removed; eventual consistency usually saves you, but the
in-memory state was briefly inconsistent and the bug is easy to miss in
unit tests. Always keep the ordering as: cleanup → confirm success →
RemoveFinalizer → Update.
Multi-finalizer ordering
Nothing stops several controllers from adding finalizers to the same object. cert-manager, ArgoCD, your in-house Operator, a Velero backup hook - each can append its own string. The API server's rule is simple:
An object is removed from etcd only when
metadata.finalizersis the empty slice. The order of removal does not matter.
In practice you do not need to coordinate with other controllers. Each
finalizer is independent - when your controller sees deletionTimestamp
set, it runs its own cleanup and removes its own string. Other finalizers
remain; the object stays Terminating until they too are cleared. The
ordering you actually need to guarantee is within your controller:
// 1. Delete external DNS record. If this fails, requeue, do not remove finalizer.
if err := r.deleteExternalDNS(ctx, backup); err != nil {
return ctrl.Result{RequeueAfter: time.Minute}, err
}
// 2. Delete cloud disk. If this fails, requeue, do not remove finalizer.
if err := r.deleteCloudDisk(ctx, backup); err != nil {
return ctrl.Result{RequeueAfter: time.Minute}, err
}
// 3. Only when *every* external side-effect is gone, remove the finalizer.
controllerutil.RemoveFinalizer(&backup, myFinalizer)
if err := r.Update(ctx, &backup); err != nil {
return ctrl.Result{}, err
}A common bug is to remove the finalizer before the cleanup completes - your operator looks neat, the object disappears quickly, and the cloud disk leaks into your bill.
If you genuinely need strict ordering across finalizers (DNS must be
deleted before the IAM role), encode the ordering on a status field such
as .status.cleanupPhase rather than relying on finalizer-array ordering -
which the API server does not guarantee.
Making cleanup observable
A finalizer that fails silently is a debugging nightmare. Two practices
turn a stuck Terminating into a self-explanatory ticket:
Surface cleanup progress on .status Conditions
Set the standard Ready Condition to False with a Cleaning reason while
the deletion branch runs, so anyone running kubectl get sees the operator
is actively trying:
meta.SetStatusCondition(&mem.Status.Conditions, metav1.Condition{
Type: "Ready",
Status: metav1.ConditionFalse,
Reason: "Cleaning",
Message: fmt.Sprintf("deleting bucket %q", mem.Status.ExternalBucketName),
ObservedGeneration: mem.Generation,
})
if err := r.Status().Update(ctx, &mem); err != nil {
return ctrl.Result{}, err
}For the full Conditions convention — the four standard types, reason
spelling, and observedGeneration rules — see
status subresource and Conditions explained.
Emit Events on cleanup failures
Events are the on-call engineer's first hop after kubectl describe.
Emit one whenever cleanup fails:
r.recorder.Eventf(&mem, corev1.EventTypeWarning,
"CleanupFailed",
"failed to delete external bucket %q: %v",
mem.Status.ExternalBucketName, err,
)That event surfaces in kubectl describe memcached memcached-sample and
in any event-stream consumer (Slack notifier, Alertmanager). Without it,
the only signal is operator logs - which nobody reads until something is
already on fire.
Testing finalizer logic with envtest
The unit test most operators do write covers the happy reconcile. The
path most operators forget is the finalizer cleanup, which is precisely
the path that leaks money in production. With envtest (the controller-runtime
test harness that spins up a real kube-apiserver and etcd in your test
process) it is a 30-line Ginkgo spec:
It("deletes external resource and removes finalizer on CR delete", func() {
cr := &cachev1alpha1.Memcached{ /* ... */ }
Expect(k8sClient.Create(ctx, cr)).To(Succeed())
// wait for the finalizer to be added
Eventually(func() bool {
_ = k8sClient.Get(ctx, key, cr)
return controllerutil.ContainsFinalizer(cr, myFinalizer)
}, "5s").Should(BeTrue())
// simulate an external resource that was created earlier
cr.Status.ExternalBucketName = "test-bucket"
Expect(k8sClient.Status().Update(ctx, cr)).To(Succeed())
// delete the CR
Expect(k8sClient.Delete(ctx, cr)).To(Succeed())
// assert the external resource was actually deleted by the operator
Eventually(func() bool { return s3Mock.WasDeleted("test-bucket") }, "5s").
Should(BeTrue())
// and the CR is finally gone
Eventually(func() bool {
return apierrors.IsNotFound(
k8sClient.Get(ctx, key, &cachev1alpha1.Memcached{}),
)
}, "5s").Should(BeTrue())
})kubectl delete is asynchronous, so polling assertions with timeouts
(Eventually(..., "5s")) is the pattern. This single spec catches the
entire class of "finalizer leaks external resources" bugs that otherwise
only surface in production support tickets.
Force-deleting a stuck object
Common misconception:
kubectl delete --force --grace-period=0does not bypass finalizers. The--force --grace-period=0combination only skips graceful pod termination — it tells the API server to immediately delete a pod without waiting for kubelet acknowledgement, and it is meaningless on any non-pod kind. Finalizers are unaffected: the object staysTerminatinguntil they are cleared. Thekubectl patch ... --finalizers []recipe below is the only built-in escape hatch.
When a controller is buggy, gone, or genuinely unable to clean up, you can patch the finalizers slice to empty. The API server will then garbage-collect the object immediately, side-effects be damned:
kubectl patch <kind> <name> -n <ns> \
-p '{"metadata":{"finalizers":[]}}' --type=mergeEquivalent JSON-Patch form (some Kubernetes versions are picky about the strategic-merge form when the field is missing):
kubectl patch <kind> <name> -n <ns> \
--type json -p '[{"op":"replace","path":"/metadata/finalizers","value":[]}]'Two warnings:
- This skips your cleanup logic. Anything the controller would have deleted - cloud volumes, DNS, external secrets - is now orphaned. Clean it up manually before patching.
- Confirm the controller is the only thing that should be doing this. On rare occasions the controller is alive and will shortly clean up on its own; in that case patching the finalizer races the controller and leaves cleanup half-finished.
For day-to-day operations the right move is to fix the controller and let it run; the patch is the last-resort escape hatch.
Diagnosing a stuck Terminating object
The standard checklist when an object sits in Terminating for more than a
few seconds:
-
Inspect the object metadata.
bashkubectl get <kind> <name> -n <ns> -o jsonpath='{.metadata.finalizers}'The string tells you exactly which controller is supposed to be doing cleanup.
-
Confirm the owning controller is running.
bashkubectl -n <operator-ns> get pods kubectl -n <operator-ns> logs <controller-pod> --tail=200A crashlooping or off-cluster controller is the most common cause of stuck finalizers.
-
Check the controller's RBAC.
If the controller can
getthe object but notupdateit, finalizer removal silently fails. Look forforbidden:lines in the logs. See operator RBAC: minimum permissions for the exact verbs every controller needs on its own CRs. -
Look for events on the object.
bashkubectl describe <kind> <name> -n <ns>A well-written controller emits an Event each time cleanup fails (e.g.
Warning CleanupFailed external DNS API returned 503). -
Last resort: force-delete with
kubectl patch(see above).
A useful one-liner for cluster-wide audits:
kubectl get all -A -o json | jq -r \
'.items[] | select(.metadata.deletionTimestamp != null) |
"\(.kind)/\(.metadata.namespace)/\(.metadata.name) finalizers=\(.metadata.finalizers)"'This surfaces every object that has been "deleting" for longer than expected.
The anti-patterns that ship to production
-
Adding the finalizer after creating the external side-effect. If the subsequent
Updatefails or the controller crashes, the side-effect is orphaned. Fix: add the finalizer first, on the very first reconcile, before any external write. -
Removing the finalizer in a
defer. A panic inside cleanup would still remove the finalizer, skipping the cleanup. Fix: remove the finalizer only on the explicit success path. -
Not handling cleanup idempotency. External APIs return 404 when a resource is already gone; treat 404 as success in cleanup code. Fix:
if err != nil && !apierrors.IsNotFound(err) { return err }on every external delete. -
Calling
r.Status().Update()in the deletion branch and expecting finalizers to come along. Finalizers live inmetadata, not instatus; the status subresource does not propagatemetadata.finalizerschanges. Fix: user.Update()for finalizer-changing writes. -
Forgetting to update tests. Unit tests that pass with a controller that ignores finalizers are doing zero work. Fix: write a test that sets
deletionTimestampon the fixture object and asserts that the controller calls cleanup and clears the finalizer. -
Namespace-scoped CR holding a cluster-scoped external resource. Deleting the namespace tries to delete the CR, but the operator pod lives in a different namespace that may already be gone - the finalizer can never be removed, and the entire namespace gets stuck in
Terminating. Fix: if your CR's cleanup target is cluster-scoped (an IAM role, a global DNS record, a cluster-wide CRD), make the CR itself cluster-scoped, or run the controller in a namespace that survives target-namespace teardown. -
Renaming the finalizer string after release.
controllerutil.ContainsFinalizer(..., "new/name")returns false on every CR in production. Cleanup is silently skipped, the old finalizer becomes permanent (the new code never adds it; the old code is gone). Fix: keep the original name, or ship a one-shot migration controller that rewrites finalizer names before the rename lands.
Frequently Asked Questions
1. What is a finalizer in Kubernetes?
2. How do Kubernetes finalizers work?
3. When should I add a finalizer to my operator?
4. Where exactly do I add the finalizer in the reconcile loop?
5. How do I detect that the CR is being deleted?
6. What does the cleanup path look like?
7. What is the naming convention for finalizers?
8. How do I add a finalizer in controller-runtime?
9. How do I handle multiple finalizers safely?
10. How do I test finalizer logic?
11. Why is my Kubernetes resource stuck in Terminating?
12. How do I force-delete a stuck Kubernetes object?
13. What is the difference between owner references and finalizers?
14. What happens if a finalizer is never removed?
15. What is the difference between --cascade=foreground and --cascade=background?
16. Does kubectl delete --force --grace-period=0 bypass finalizers?
What's next?
You now have safe deletion handled. Natural next reads:
- Status subresource and Conditions explained —
the symmetric mechanism for writing observed state back to the API
server, with the KEP-1623
Ready/Progressing/Available/Degradedconvention used in the observability section above. - The Kubernetes reconcile loop explained —
the level-triggered control loop that calls your
Reconcile()in the first place, and the threeResultreturn paths your finalizer logic relies on. - Server-Side Apply in operators —
why finalizer updates use
r.Update()rather thanr.Patch(), and how SSA changes the conflict story for the rest of the reconcile loop. - Watches, events, and predicates —
why
DeleteEventis not a reliable cleanup trigger on its own and why you need finalizers even with a custom watch predicate. - Owner references and garbage collection — when ownerReferences alone are enough and finalizers are unnecessary.
- Operator RBAC: minimum permissions —
the most common cause of a stuck finalizer is a missing
updateverb on the CR; this is the article that prevents it. - Custom Resource Definitions explained — the schema the finalizers are guarding.
Summary
A finalizer is Kubernetes' safety mechanism for preventing resource leaks during deletion.
Instead of deleting an object immediately, the API server pauses deletion by setting deletionTimestamp and waits for every controller listed in metadata.finalizers to complete its cleanup work.
For Kubernetes-native resources, owner references and garbage collection are usually sufficient.
For anything outside the cluster—cloud volumes, DNS records, databases, SaaS APIs, certificates, or infrastructure services—a finalizer is the difference between clean deletion and an orphaned resource.
The production pattern is simple:
- Add the finalizer before creating external resources.
- Detect
deletionTimestampduring reconciliation. - Perform idempotent cleanup.
- Remove the finalizer only after cleanup succeeds.
- Let Kubernetes complete the deletion.
Get this pattern right once, and every deletion your Operator performs becomes safe, predictable, and recoverable.
