Every conversation about Kubernetes — from the simplest kubectl scale to the
most sophisticated multi-region Operator — eventually boils down to the same
sentence: "the actual state of the cluster should match the desired state
declared in YAML." This article unpacks that sentence and shows why the
choice between declarative and imperative, and between
level-triggered and edge-triggered, is the single most important
design decision in the system.
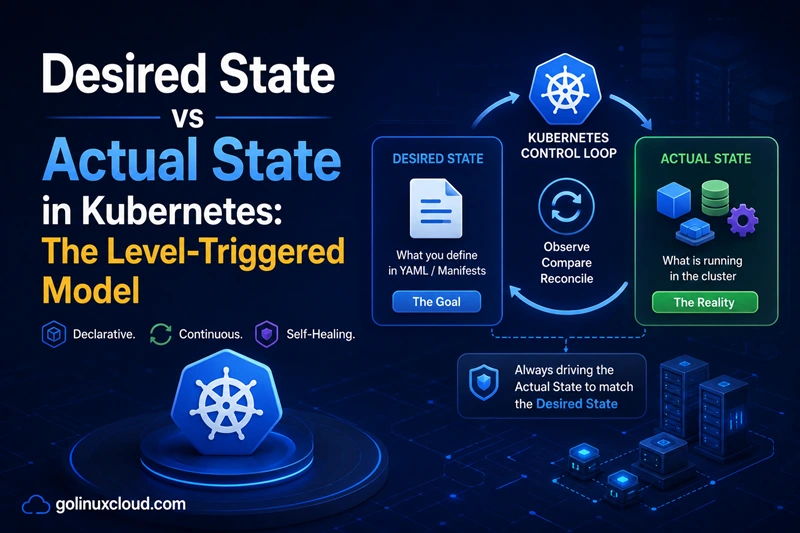
.specis what you want,.statusis what currently is, and the reconciler runs forever to make them agree.
If you have not yet read The reconcile loop explained, this article and that one form a pair — the loop is how, this article is why.
TL;DR: Desired State vs Actual State at a glance
In Kubernetes:
- Desired state is everything inside
.spec— it is what the user wants. - Actual state is what the cluster currently looks like — Pods running,
IPs assigned, conditions reached. It is reflected (but not defined) in
.status. - The controller (or Operator) is whoever closes the gap. Every built-in
controller and every Operator does the same thing on a loop: read
.spec, observe reality, reconcile.
Kubernetes is declarative (you describe the goal, not the steps) and level-triggered (the controller acts on the current state, not on transitions). Together, those two properties are what give Kubernetes its famous self-healing, drift correction, and GitOps-friendly behaviour.
A Quick Analogy: A Thermostat and a Heater
Imagine you set your home thermostat to 22°C.
That temperature is the desired state. It represents the condition you want the system to maintain.
The room itself has an actual state. Right now it might be 22°C, 18°C, or 25°C depending on what is happening around it.
The thermostat continuously compares the desired temperature with the actual temperature:
- If the room is already 22°C, no action is needed.
- If the temperature drops to 18°C, the thermostat detects the difference.
- The heater turns on and raises the temperature.
- Once the room reaches 22°C again, the thermostat stops heating.
The thermostat never cares how the temperature changed. Maybe someone opened a window. Maybe it became colder outside. Maybe the heater was temporarily turned off. It only cares about one thing:
Is the actual state equal to the desired state?
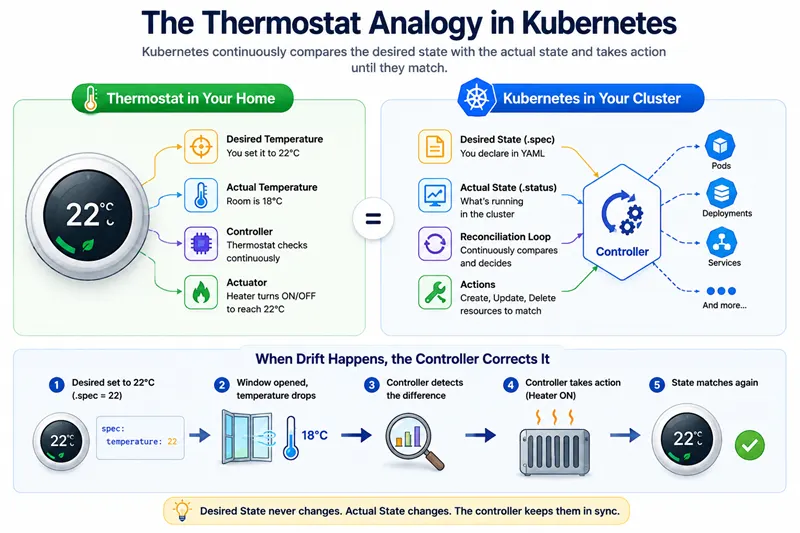
The desired temperature mirrors Kubernetes desired state (.spec); the actual room temperature mirrors the cluster's actual state (.status); the thermostat is the controller. When drift occurs — the room cools from 22°C to 18°C — the thermostat detects the difference and turns the heater on until the desired temperature is restored. Kubernetes controllers do exactly the same with cluster state.
Kubernetes works exactly the same way.
| Thermostat System | Kubernetes |
|---|---|
| Desired temperature (22°C) | Desired state (.spec) |
| Actual room temperature | Actual state (.status) |
| Thermostat | Controller |
| Heater | Create, update, or delete operations |
| Temperature drift | Configuration drift, failed Pods, deleted resources |
| Returning to 22°C | Reconciliation |
Suppose a Deployment declares:
spec:
replicas: 3At some point, one Pod crashes and only two remain.
The desired state has not changed. The actual state has.
Just like a thermostat noticing the room has cooled below 22°C, the controller notices that only two Pods are running when three are required. It takes corrective action and creates a replacement Pod.
Once three Pods are running again, the system has converged back to the desired state.
This continuous comparison and correction process is what Kubernetes calls reconciliation, and it is the foundation of the platform's self-healing behaviour.
Declarative vs imperative - Kubernetes' deliberate choice
Two ways a system can be controlled:
| Style | You say | The system does |
|---|---|---|
| Imperative | "Start container, then add to load balancer, then update DNS" | Executes the steps in order. If a step fails or is forgotten, the system is in an unknown state. |
| Declarative | "This Deployment has 3 replicas behind this Service with these labels" | Computes the steps itself, runs them, and keeps running them until reality matches. |
Kubernetes picked declarative intentionally - documented in the official "Working with Kubernetes objects" guide - because declarative state composes:
- It can live in a Git repository, version-controlled and reviewed.
- Multiple actors (humans, CI, Operators) can edit different parts safely.
- The system recovers automatically when nodes restart, networks blip, or someone deletes a Pod by hand.
- The same YAML works on Minikube, on EKS, and on a 5-region production fleet.
Imperative kubectl run and kubectl scale commands still exist for one-off
shell convenience, but every one of them eventually edits the declarative
state in etcd. There is no parallel imperative engine running underneath.
That last property — the same YAML works everywhere — is the foundation of GitOps. Tools like Argo CD and Flux work because the desired state of a Kubernetes cluster is just a directory of YAML in a Git repository. They sync Git → etcd and rely on Kubernetes' built-in drift correction to do the rest. There is no separate "apply engine" doing the heavy lifting; it is the same level-triggered reconcile loop that Kubernetes runs for every built-in object.
.spec is desire, .status is observation
Every Kubernetes object follows the same two-section layout:
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
spec: # written by the user - desired state
replicas: 3
template:
spec:
containers:
- image: nginx:1.27
status: # written by the controller - actual state
replicas: 3
readyReplicas: 3
conditions:
- type: Available
status: "True"Two crucial properties:
-
The user owns
.spec. The controller owns.status. This is enforced at the API level:.statusis exposed as a separate subresource (/status), and updates to it travel a different path. A user cannot accidentally smear.status, and a controller's status update will not race with a user's.specedit. -
.statusis derived, not stored as truth. If you wipe.status, the controller will rebuild it on the next reconcile from observations of the real cluster. The source of truth is always the cluster, not the recorded status.
This separation is also why every Operator we looked at in
What is a Kubernetes Operator? — Prometheus,
cert-manager, CloudNativePG — puts its observed-state reporting into
.status and never asks the user to fill it in.
Since Kubernetes 1.22, Server-Side Apply (SSA)
refined who owns which fields inside .spec. Each writer — a user with
kubectl apply --server-side, an Operator, a CI pipeline — gets a
fieldManager identity, and the API server records which fields each
manager owns. Two actors editing disjoint fields no longer overwrite each
other, and two actors editing the same field surface a clear conflict
instead of a silent last-write-wins.
Tip:
kubectl diff -f my-manifest.yamlshows exactly what the API server would change if you applied the manifest — desired state minus actual state, with no side effects. It is the cleanest way to inspect drift before deciding to fix it.
Drift correction is continuous, not one-shot
If you came from configuration management tools like Ansible or Terraform, you probably think of "apply" as a one-time event: you run it, the system converges, you're done. Kubernetes is different.
After kubectl apply, the API server stores the new .spec in etcd and
fires watch events. From that moment, every relevant controller starts
working continuously to close the gap — and it never stops. Three
concrete examples of self-healing in action:
- A Pod gets evicted by the kubelet (perhaps it was OOMKilled).
The ReplicaSet controller notices
replicas: 3but only 2 Pods exist, and creates a new one. - An admin manually deletes a Service the Operator created. The Operator's reconcile re-creates it on the next loop iteration — usually within milliseconds.
- A node disappears overnight. The replica count is still 3, so the scheduler places the missing Pods elsewhere the moment alternate capacity is available.
This is what people mean when they call Kubernetes self-healing. The reconcile loop is not an installer; it is a daemon that lives the lifetime of the cluster. (For the full pipeline that powers this, see the Kubernetes reconcile loop explained.)
Continuous correction only works because every reconcile is idempotent
— running it twice has the same effect as running it once. Creating a Pod
that already exists is a no-op, scaling a Deployment that is already at the
right replica count does nothing, and patching a Service to the spec it
already has produces no API change. Idempotency is what lets controllers
re-run their Reconcile() function as often as they need to — every few
seconds, every minute, on every watch event — without drifting into a
broken state while trying to fix one.
Operators take this one level higher. The Deployment controller restores a Pod; a Postgres Operator restores the right Pod in the right role at the right replication position — that is the domain expertise we talked about in Operator vs Controller vs CRD.
Edge-triggered vs level-triggered - the design choice that makes drift correction work
Two ways a controller could decide when to act:
| Model | Trigger | Failure mode |
|---|---|---|
| Edge-triggered | A specific transition ("replicas changed from 3 to 5") | If the event is dropped (network glitch, controller restart), the action is lost forever. |
| Level-triggered | The current state ("replicas is now 5") | Safe. If the controller missed an event, the next reconcile sees the same level and acts the same way. |
Kubernetes is firmly level-triggered. The watch stream from the API server wakes your controller, but the controller does not consume the event payload - it asks the controller-runtime cache for the latest object state and works from there. As the official controller documentation puts it:
"Each controller tries to move the current cluster state closer to the desired state."
What would go wrong if Kubernetes were edge-triggered? Three real failure modes that level-triggered design avoids for free:
- A controller crash while it was processing an event would lose that event permanently. Recovery would require log replay or external reconciliation tools.
- A network partition between the API server and a controller would cause a backlog of events; on reconnect, the controller would have to carefully replay them in order. With level-triggered, you just re-list and act on the current state.
- Two writers modifying the same object would race in unpredictable ways - you'd need exactly-once delivery, which is fundamentally hard in distributed systems. Level-triggered systems converge to the same end state regardless of event ordering.
Eventual consistency - what Kubernetes actually promises
Kubernetes does not promise that your desired state becomes the actual state
immediately. It promises eventual consistency: if you stop changing
.spec and the underlying infrastructure is healthy, the system will
converge in bounded time.
Three concrete consequences:
- Pods that go
Pendingare not bugs - the scheduler is still searching for capacity. The desired state is "running"; the actual state is "pending"; the gap is being closed. - Status fields lag by a tick. Right after
kubectl apply, you may see the old.status.replicasfor a fraction of a second. The next reconcile catches up. - The order of changes does not matter. You can apply 50 manifests in any sequence - the controllers will sort themselves out as soon as the dependencies (CRDs, namespaces, ConfigMaps) exist.
If you want stronger consistency (e.g. "do not return from kubectl apply
until the Deployment is fully rolled out"), tools like kubectl rollout status or Argo CD's wave-based sync
wait for convergence on your behalf - they do not change Kubernetes'
underlying model.
Common Misconceptions
Three things that trip up almost every newcomer to the declarative model:
"Pending Pods are failures."
They usually are not. Pending means the desired state (a running Pod)
has been recorded and the scheduler is still working on the actual state
(placement onto a node). Wait, or check kubectl describe pod <name> for
the real reason, before assuming something is broken.
"kubectl apply finishes when the command returns."
It does not. kubectl apply only updates desired state in etcd. The
actual state catches up afterwards, asynchronously, in the controller's
own time. Use kubectl rollout status, kubectl wait, or your GitOps
tool's sync wave if you need to block until convergence.
".status is the source of truth."
It is not. .status is a cached projection of reality that the
controller maintains for the convenience of users and other controllers.
If you delete it, the controller will rebuild it on the next reconcile
from real observations of the cluster. The actual cluster — the running
Pods, the assigned IPs, the bound volumes — is always the real source of
truth, and .spec is always the desired source of truth. .status is
the bridge between them.
Frequently Asked Questions
1. What is the desired state in Kubernetes?
2. What is the actual state in Kubernetes?
3. Is Kubernetes declarative or imperative?
4. What does it mean that Kubernetes is level-triggered?
5. How does Kubernetes detect drift between desired and actual state?
6. What is the difference between spec and status in Kubernetes?
7. What is reconciliation in Kubernetes?
8. What does self-healing mean in Kubernetes?
What's next?
The desired-state / actual-state model is the foundation; the next articles build on it directly:
- How is the gap actually closed? The Kubernetes reconcile loop
explained covers the pipeline
from watch event to
Reconcile()and theResult{}return values. - What is the API contract for desired state? Custom Resource Definitions
(CRDs) explained shows
how the OpenAPI schema, structural validation, and the
spec/statussubresource separation work in detail. - Where does drift detection get really interesting? Future article on drift detection patterns in operators covers periodic resync vs spec diffing vs Server-Side Apply.
- What is doing the watching? controller-runtime architecture walks the Manager, Cache, and Informer that power level-triggered control.
- Going back to basics? What is a Kubernetes Operator? and Operator vs Controller vs CRD are the two foundational concept articles in this course.
