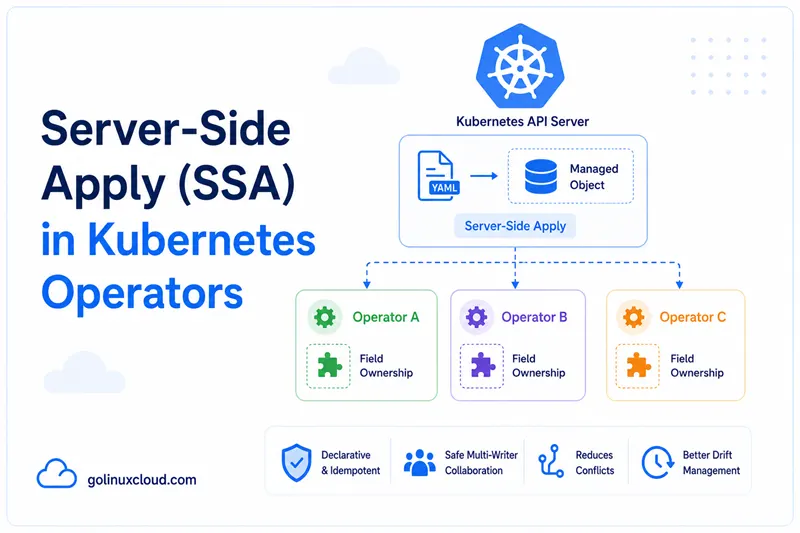
Every operator you write does the same thing thousands of times a day: read a Custom Resource from the API server, build a Deployment (or Service, or ConfigMap) that matches the spec, then push that Deployment back to the cluster. For years the recommended way to push the Deployment was r.Update(ctx, &deploy) or a strategic-merge patch. That works — until the moment another controller, an HPA, a sidecar injector, or a human running kubectl edit also touches the same object. Then your operator and the other actor start fighting over fields, "object has been modified" errors flood the logs, and reconciles loop forever.
Server-Side Apply (SSA) is the modern solution to this exact problem. Instead of sending a full object back to the server, your operator sends only the fields it claims to own, tagged with a unique manager name. The API server tracks ownership in metadata.managedFields and merges your changes with everyone else's atomically — no client-side three-way merge, no resourceVersion races, no fighting.
This article explains why SSA exists, how the ManagedFields contract works, the FieldOwner naming convention, the conflict-vs-force decision, the Go patterns for client.Apply, and how to migrate an existing operator from Update to Apply without breaking production. The whole goal is to leave you with a clear mental model — by the end you will know exactly when to reach for SSA and exactly what to watch out for.
TL;DR — Server-Side Apply in 60 seconds
Server-Side Apply (SSA) is a write mode where the API server, not the client, computes the merge. The client sends a partial object containing only the fields it claims, tagged with a fieldManager (in controller-runtime, client.FieldOwner("memcached-operator")). The server tracks ownership in metadata.managedFields, merges the partial object with the live one, and rejects writes where another manager already owns a field — unless the client passes client.ForceOwnership.
The minimal Go pattern:
const fieldOwner = client.FieldOwner("memcached-operator")
desired := &appsv1.Deployment{ /* only the fields this operator owns */ }
desired.TypeMeta = metav1.TypeMeta{APIVersion: "apps/v1", Kind: "Deployment"}
return r.Patch(ctx, desired, client.Apply, fieldOwner)Three rules:
- Set
TypeMeta— SSA needsapiVersion+kindto look up the schema. - Set only the fields you own — every field you include claims
ssa fieldmanager operatorownership inmanagedFields. - Skip
client.ForceOwnershipwhile you are still figuring it out — the conflict errors are the most useful signal you'll get.
Migration from r.Update is incremental: one object kind at a time, shadow-Apply for a few days, then cut over. The full playbook is below.
A simple analogy: a shared Google Doc with named cursors
Before we touch any Go code, picture a Google Doc that three people are editing at once: an author, a copy editor, and an automated grammar bot. Each one's cursor has a coloured name tag. The author writes the body paragraphs. The copy editor changes punctuation and casing. The grammar bot underlines passive voice and proposes fixes.
The doc works because Google Docs tracks who edited what. When the grammar bot tries to rewrite a sentence the author has just locked in, Google Docs flags a conflict instead of silently overwriting the author's work. When the copy editor deletes their own comment, only their comment goes away — the author's paragraph and the grammar bot's underline are untouched. Three people can co-edit one document without anyone needing to "take turns".
A Kubernetes object under SSA works exactly the same way. The "name tags" are FieldManagers. The "doc" is the object (a Deployment, a ConfigMap, anything). The "co-editors" are your operator, an HPA, a webhook, and the occasional human running kubectl edit. The API server is the Google Docs of the cluster — it tracks ownership in metadata.managedFields and refuses to let one editor silently overwrite another's claimed fields unless they explicitly assert authority with force: true.
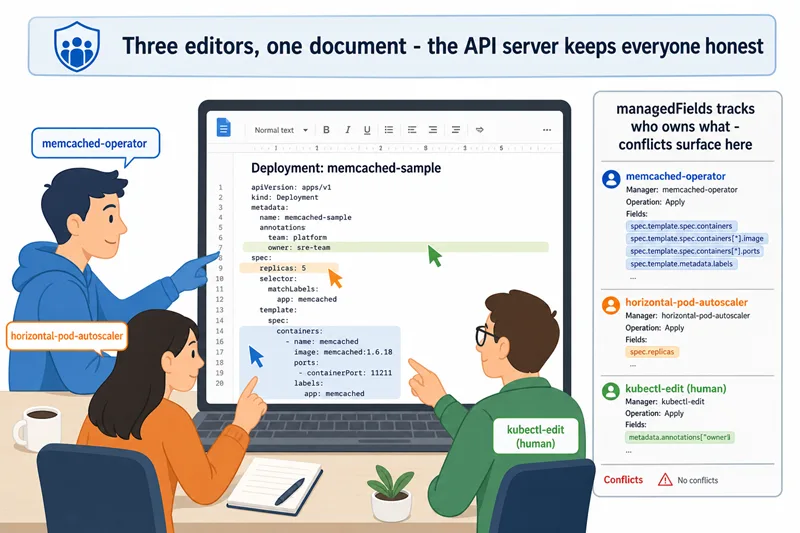
With SSA, every controller is just another cursor in a shared document — and the API server is the editor that keeps everyone honest.
Once you can hold that picture in your head, the rest of SSA is mostly bookkeeping. Everything that follows — managedFields, conflicts, Force — is just how the API server makes the analogy real.
Why Server-Side Apply matters
SSA went stable in Kubernetes 1.22 specifically because the older write modes had three structural problems that bit every non-trivial operator:
1. Update produces "object has been modified" retry storms
The r.Update(ctx, &obj) call requires sending the full object with the current resourceVersion. Under any kind of write contention — an HPA touching the same Deployment, a webhook injecting a sidecar, another operator co-owning a label — the resourceVersion you read at the start of reconcile is stale by the time you write, and the API server rejects with Conflict: object has been modified; please apply your changes to the latest version. The standard fix (re-read + retry) is just papering over the fact that you are sending fields you do not actually own. SSA sidesteps the whole problem: you send only your fields, and the server merges atomically.
2. Strategic merge patch has no concept of ownership
The pre-SSA "best" practice was strategic merge patch — but the server-side merge logic treats every writer identically. If your operator and an HPA both write spec.replicas, the last writer wins, with no record of who took it from whom. SSA encodes ownership directly in metadata.managedFields: each manager has a separate entry, each entry lists the field paths it owns, and the server enforces non-overlap on every Apply.
3. Drift correction is implicit, not declared
With r.Update, "this operator owns this field" is a property of your reconciler code — invisible to humans, invisible to other controllers, invisible to auditors. With SSA, that ownership is a first-class object in the API. kubectl get deploy foo -o yaml | yq '.metadata.managedFields[].manager' answers the question "who owns what" in one shell line — and the multi-resource reconciliation and multi-tenancy patterns that build on top of SSA both depend on this visibility.
For the official deep dive on SSA semantics, see the Server-Side Apply reference in the Kubernetes docs. For the controller-runtime side, the client.Apply documentation shows exactly how Go operators wire it up.
Prerequisites
- A working operator scaffolded by
kubebuilder4+ oroperator-sdkwithcontroller-runtimewired in. - Familiarity with the reconcile loop — SSA changes the shape of every write your reconciler makes.
- Familiarity with watches, events, and predicates —
managedFieldsupdates from SSA are exactly the kind ofResourceVersionChangedPredicatetraffic the predicates discussion warned about. - Optional but recommended: Status subresource and Conditions — the canonical exception to "use SSA for everything."
Life with vs life without Server-Side Apply
The fastest way to feel why SSA matters is to walk through one concrete failure that the old model produces and SSA fixes. Take a Memcached operator that owns a Deployment, alongside an HPA that the user has installed to autoscale that Deployment. Both controllers want to write to the Deployment object — but they care about different fields.
Without SSA, your operator's reconcile loop reads the Deployment with r.Get, builds a desired Deployment based on the CR's .spec.size, sets deploy.Spec.Replicas = 3, and calls r.Update(ctx, &deploy). Two seconds later the HPA reads the same Deployment, decides that load justifies 5 replicas, sets Replicas: 5, and updates the object — using its own copy with whatever resourceVersion it has. If your operator now reconciles again with a stale resourceVersion, the API server rejects the Update with a conflict. Your operator retries, reads the new Deployment (with 5 replicas), and resets it to 3 because that is still what the CR's .spec.size says. The HPA notices and writes 5 again. You have a controller fight, and somebody pages on-call.
The "fix" you see in older operator code is one of two ugly options: either the operator gives up and adds a special case to skip Replicas when an HPA is detected, or the operator does a strategic-merge patch and hopes the field structure does not change. Both work for a while; both rot the codebase.
With SSA, your operator sends an Apply request that explicitly does not include spec.replicas. The fieldManager memcached-operator claims everything in the Deployment spec except replicas. The HPA's fieldManager horizontal-pod-autoscaler claims spec.replicas and nothing else. The two controllers co-own the object peacefully. If your operator ever does try to write spec.replicas (perhaps a bug, perhaps a feature), the server returns a clean conflict telling you which field the HPA already owns — you get a precise error message instead of a fight.
This is why every modern operator scaffolded by kubebuilder 4+ uses SSA by default for managed resources, and why the Kubernetes documentation now actively recommends migrating away from full Updates in controller code.
Why is it called "Server-Side" Apply?
The name distinguishes it from the old kubectl apply flow, which was client-side. In the client-side model, kubectl apply annotates each object with kubectl.kubernetes.io/last-applied-configuration — a JSON blob containing the previous version of the object. On the next kubectl apply, kubectl reads the cluster's current object, reads the last-applied annotation, computes a three-way merge between the three (current, last-applied, desired), and sends a patch to the API server.
That worked surprisingly well for a long time, but the design had three structural problems. First, the last-applied annotation is just text glued onto the object — any controller writing to the object could (accidentally or maliciously) corrupt it, breaking subsequent apply operations. Second, the three-way merge is computed on the client, so two clients computing diffs against slightly different views of "current" can converge to incompatible patches. Third, there is no concept of who owns which field — the merge logic treats all fields equally, which means a controller writing a single field still claims authority over the entire object.
The Kubernetes API working group designed Server-Side Apply to solve all three problems at once. By moving the merge into the API server, ownership becomes a first-class concept tracked in metadata.managedFields, and the merge logic becomes deterministic across clients. The work was specified in KEP-555 — Server-side Apply, promoted to beta in Kubernetes 1.16, and graduated to stable (GA) in 1.22.
So when someone says "use SSA", they mean: let the API server own the merge logic, and let managedFields be the source of truth for ownership. That phrase is the whole spirit of the feature.
How does Server-Side Apply actually work?
Let's slow down and walk through one Apply request, end to end, using the Memcached example.
-
The operator builds a desired object. This is not a full Deployment — it is a tiny "what I claim to own" view. For example, just the container image, the labels the operator manages, and the volume mounts. It explicitly omits
spec.replicas(the HPA owns that) andspec.template.spec.tolerations(the cluster autoscaler injects those). -
The operator sends a PATCH request to the API server with
Content-Type: application/apply-patch+yamland the query parameterfieldManager=memcached-operator. The body is the partial object as YAML or JSON. -
The API server validates the partial object against the object's schema. Required fields that the operator did not include are tolerated (because Apply is partial), but type errors and value-range violations still fail fast.
-
The API server computes ownership. For every field path in the partial object (e.g.
spec.template.spec.containers[name=memcached].image), it looks up the existingmanagedFieldsto see which manager already owns it. If the field is unowned or already owned bymemcached-operator, the change is allowed. If another manager owns it, the request is rejected with a conflict — unlessforce=truewas set. -
The API server merges the desired fields into the live object. Lists are merged by their declared merge key (often
name); maps and structs are merged field-by-field. Fields the operator did not mention are left exactly as they were — they belong to other managers (or to no one). -
The API server updates
metadata.managedFieldsto record the new ownership. Each entry includes the manager name, the operation (ApplyorUpdate), the API version, a timestamp, and a compressed representation of the field paths owned. -
The API server returns the post-merge object. Your operator can inspect it, write status, and finish the reconcile.
That last point matters. The Apply response gives you back the authoritative state of the object after your changes — including fields owned by other managers. That is the data you should use to compute your CR's status, not the desired object you sent.
What does managedFields actually look like?
Here is a real managedFields block on a Deployment owned by both a Memcached operator and an HPA. Notice how each manager has a separate entry, and how the field set is encoded as a structured fieldsV1 blob.
apiVersion: apps/v1
kind: Deployment
metadata:
name: memcached-sample
namespace: default
managedFields:
- apiVersion: apps/v1
fieldsType: FieldsV1
fieldsV1:
f:metadata:
f:labels:
f:app: {}
f:app.kubernetes.io/managed-by: {}
f:spec:
f:selector: {}
f:template:
f:metadata:
f:labels:
f:app: {}
f:spec:
f:containers:
k:{"name":"memcached"}:
.: {}
f:image: {}
f:name: {}
f:ports: {}
manager: memcached-operator
operation: Apply
time: "2026-05-31T10:42:00Z"
- apiVersion: autoscaling/v2
fieldsType: FieldsV1
fieldsV1:
f:spec:
f:replicas: {}
manager: horizontal-pod-autoscaler
operation: Apply
time: "2026-05-31T10:55:13Z"Read it from the bottom: horizontal-pod-autoscaler owns exactly one field, spec.replicas. From the top: memcached-operator owns metadata.labels.app, spec.selector, the container's image, name, ports, and the template labels. Neither manager mentions spec.replicas in the operator's entry, so the operator never fights the HPA. This is the whole point of SSA — encoded right there in the YAML, visible to anyone who runs kubectl get deploy memcached-sample -o yaml.
You can inspect managedFields on any object the same way. It is verbose, but it is the closest thing Kubernetes has to a debugger for cross-controller ownership disputes.
The FieldManager name: pick one and stick to it
The FieldManager is a string. Kubernetes does not validate it beyond a length limit (128 chars), but the convention is to use a stable, descriptive name per controller. controller-runtime exposes it through the client.FieldOwner option.
const fieldOwner = client.FieldOwner("memcached-operator")
func (r *MemcachedReconciler) reconcileDeployment(ctx context.Context, mem *cachev1alpha1.Memcached) error {
desired := r.buildDesiredDeployment(mem)
return r.Patch(ctx, desired, client.Apply, fieldOwner, client.ForceOwnership)
}Three rules for naming:
Use one FieldManager per controller, not per object kind. Resist the urge to name them memcached-deployment-manager, memcached-service-manager, memcached-configmap-manager. A single name like memcached-operator is easier to reason about and makes ownership audits trivial — kubectl get deploy foo -o jsonpath='{.metadata.managedFields[*].manager}' gives you a clean answer.
Never reuse a name another tool uses. kubectl, kube-controller-manager, horizontal-pod-autoscaler, kustomize-controller (Flux), and helm are taken. Using one of these will produce confusing conflict messages because the API server will treat your operator as the same actor as that tool — and the tool will eventually overwrite your fields anyway.
Keep the name stable across releases. Once your operator ships and starts owning fields, renaming the FieldManager creates an orphaned managedFields entry that nobody owns, and your new name has to re-claim every field. Worst case, your operator sees a flood of conflicts on the first reconcile after a rename. If you absolutely must rename, do it during a maintenance window and run a one-off migration script that patches all affected objects.
The same stability principle applies to the operator's other long-lived identifiers — see minimum RBAC permissions for the ServiceAccount name and leader election explained for LeaderElectionID. All three should be picked deliberately on day one and never renamed casually.
Apply in Go: the client.Apply patch type
The controller-runtime Go API exposes SSA through the existing Patch method, with client.Apply as the patch type. Here is the canonical pattern, broken down into a desired-state builder and an apply call.
package controllers
import (
"context"
appsv1 "k8s.io/api/apps/v1"
corev1 "k8s.io/api/core/v1"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"sigs.k8s.io/controller-runtime/pkg/client"
cachev1alpha1 "github.com/example/memcached-operator/api/v1alpha1"
)
const fieldOwner = client.FieldOwner("memcached-operator")
func (r *MemcachedReconciler) reconcileDeployment(ctx context.Context, mem *cachev1alpha1.Memcached) error {
desired := &appsv1.Deployment{
TypeMeta: metav1.TypeMeta{
APIVersion: "apps/v1",
Kind: "Deployment",
},
ObjectMeta: metav1.ObjectMeta{
Name: mem.Name,
Namespace: mem.Namespace,
Labels: map[string]string{
"app": mem.Name,
"app.kubernetes.io/managed-by": "memcached-operator",
},
},
Spec: appsv1.DeploymentSpec{
Selector: &metav1.LabelSelector{
MatchLabels: map[string]string{"app": mem.Name},
},
Template: corev1.PodTemplateSpec{
ObjectMeta: metav1.ObjectMeta{
Labels: map[string]string{"app": mem.Name},
},
Spec: corev1.PodSpec{
Containers: []corev1.Container{{
Name: "memcached",
Image: "memcached:" + mem.Spec.Version,
Ports: []corev1.ContainerPort{{
Name: "memcached",
ContainerPort: 11211,
Protocol: corev1.ProtocolTCP,
}},
}},
},
},
},
}
// NOTE: spec.Replicas is intentionally omitted; an HPA may own it.
return r.Patch(ctx, desired, client.Apply, fieldOwner, client.ForceOwnership)
}Three details that matter and are easy to miss.
TypeMeta is required. Server-Side Apply uses apiVersion and kind to look up the schema and merge keys. The struct-tag default of empty strings will produce a confusing 400 error from the API server.
Set only the fields you claim to own. In the example above, spec.replicas is deliberately not set. If your CR carries a Spec.Size field that you intend to write to the Deployment, set it explicitly — and accept that you are claiming ownership of spec.replicas. If you do not want the operator to fight the HPA, leave the field out entirely.
Pass client.ForceOwnership cautiously. With the option, the operator wins any conflict — useful when your operator is the authoritative source of truth for the object. Without it, you get a clean conflict error that lists which fields are contested, which is invaluable while you are still figuring out which fields you really own. Many teams ship without Force during development, then add it during the production cutover.
Conflict resolution: when SSA rejects your write
A conflict response from SSA looks like this in the operator logs:
admission webhook "..." denied the request: Apply failed with 1 conflict:
conflict with "horizontal-pod-autoscaler" using autoscaling/v2:
.spec.replicasThe three pieces of information in the error are: the other manager's name, the API version that manager was using when it claimed the field, and the exact field path that is contested. With those three pieces, you can decide what to do.
Option A — drop the field from your Apply. If the other manager is the rightful owner (an HPA owning spec.replicas), simply stop sending the field from your operator. This is the cleanest fix and resolves the root cause.
Option B — retry with Force. If your operator is the authoritative source and the other manager is wrong (a human ran kubectl edit and froze the image tag), retry the same Apply with client.ForceOwnership. The next reconcile will overwrite the bad value and steal ownership back to your operator's FieldManager.
Option C — defer to the conflict and surface it. Sometimes the right answer is "the cluster is in a state I do not understand; let a human decide". In that case, record an Event on the CR (r.Recorder.Eventf(mem, corev1.EventTypeWarning, "Conflict", "field %q owned by %q", path, other)) and return without retrying. The CR's status will surface the conflict, and an operator can investigate.
Avoid the anti-pattern of always passing Force just to silence conflicts. Force is a hammer, not a default. It works because the API server trusts you to know what you are doing. If your operator force-overwrites a field an HPA legitimately owns, you have created exactly the controller fight SSA was supposed to prevent.
In reconcile-loop terms, a conflict is a permanent error until the underlying ownership situation changes — retrying the identical request with the same input will fail in exactly the same way. The right pattern is to back off (record an Event, surface a Degraded Condition via .status.conditions), and let the next CR .spec change or external intervention drive a fresh reconcile.
Migrating from Update to Apply
Most operator code shipped before 2023 uses r.Update or r.Patch with strategic-merge — not SSA. Migrating is not difficult, but it does require care because the moment you Apply, you change what your operator claims to own in managedFields. Get the field set wrong and the next reconcile will yank ownership away from another controller you did not mean to fight.
A safe migration looks like this:
Step 1: Pick one object kind to migrate first. A good starting candidate is something the operator owns completely — a ConfigMap or Service the operator creates from scratch and that no other controller touches. Avoid Deployments and Pods in the first round; they tend to be co-owned with HPAs, sidecar injectors, and admission webhooks.
Step 2: Build a "desired object" function that returns only the fields you own. This is the hard part. Walk through your existing Update code and ask "would this operator ever care if a human added field X by hand?". If the answer is no, leave field X out of the desired object — let it stay in the user's hands.
Step 3: Run a "shadow Apply" phase. Keep your existing Update call but, before it, log what a hypothetical Apply would send. Deploy to a staging cluster and watch the logs for a few days. The diff between the shadow-Applied object and the Updated one is what other managers are doing — if you see fields the operator did not expect, decide whether to start owning them (add to your desired object) or to let them go (leave them out).
Step 4: Cut over. Replace r.Update with r.Patch(ctx, desired, client.Apply, fieldOwner). Initially do not pass client.ForceOwnership — let conflicts surface so you can see if your field set is wrong. After 24–48 hours of clean reconciles, add client.ForceOwnership so your operator is genuinely authoritative.
Step 5: Repeat for every kind. Move on to the next object kind your operator manages, applying the same shadow-then-cutover process. Avoid the temptation to do all kinds in one big bang — the diagnostic value of going one kind at a time is huge.
A practical safety net: keep the old Update code in a feature-flagged branch for one release after the SSA cutover. If something goes sideways in production, you have a one-line config change to revert. After one release of clean SSA operation, delete the dead code.
When NOT to use Server-Side Apply
SSA is the right default for almost every modern operator, but there are real cases where Update or a custom patch is still the better choice.
Updating the status subresource. The .status subresource has its own ownership rules — only the controller is supposed to write status, and there are no co-owners. Update via r.Status().Update(ctx, mem) is simpler, faster, and produces clearer code. For the canonical pattern (including the equality.Semantic.DeepEqual guard that prevents status hot loops), see status subresource and Conditions. SSA is valid for status if you have a hard requirement to share status fields across multiple controllers — but that is rare.
Atomic resourceVersion-guarded writes. If your operator implements optimistic concurrency control over a contested CR (e.g. enforcing a state-machine transition that must happen exactly once), the explicit resourceVersion check of Update is the right tool. SSA does not give you the same guarantee — two Apply calls in flight can both succeed without conflict if they touch different fields.
Removing a label or annotation. SSA "removal" requires explicitly setting the field to nil/absent in the desired object, which the API server then strips because no manager owns it any more. This works for fields your own manager set, but cleaning up fields owned by other managers requires a Patch with a JSON-merge operation. It is rare, but it is real.
Operators that pre-date SSA support in your target Kubernetes version. SSA went GA in Kubernetes 1.22. If you support 1.19 or earlier (and a small number of regulated-industry clusters still do), stick with the older patterns and gate SSA behind a build-time flag.
For most modern operators on Kubernetes 1.24+, none of these caveats apply — start with SSA for the workload objects and use r.Status().Update for status. That combination gets you 95% of the production-grade ergonomics without any of the edge cases.
Common pitfalls and how to avoid them
A handful of mistakes show up repeatedly when teams migrate to SSA. Calling them out explicitly saves a lot of debug time.
Forgetting TypeMeta. A blank APIVersion or Kind will fail with a 400 from the API server and a misleading error message ("Invalid type for object"). Always set both.
Reusing the FieldManager across multiple controllers. If a single binary runs three reconcilers and they all use client.FieldOwner("my-operator"), the managedFields entry will conflate ownership across them. Either use distinct names (memcached-operator/Memcached, memcached-operator/Backup) or accept that one manager owns everything together — but do it deliberately.
Sending fields you did not mean to own. A common bug: copy-pasting the entire scaffolded Deployment into the desired-state builder, including spec.replicas from the CR. The operator now owns replicas and will fight any HPA the user installs. The fix is mechanical — delete the field from the builder — but the symptom (HPA flapping back and forth with the operator) is confusing if you have not seen it before.
Always passing client.ForceOwnership. Force is for the cutover and for genuine "I am the authority" cases. If every Apply uses it, your operator silently steals ownership from anything in its path. Drop Force, run for a few hours, and see what conflicts surface — that tells you which fields you should not be sending.
Mixing Apply and Update on the same object. As covered above, this corrupts managedFields. If you absolutely have to do one Update on an object (perhaps to recover from a broken state), follow it immediately with an Apply of the same fields so ownership is re-established under the SSA model.
Not budgeting for the migration. Switching one operator from Update to Apply is a one-week project (build, shadow, cutover, monitor). Switching ten objects at once is a one-month project. Plan accordingly and migrate one kind at a time.
Pitfall cheat sheet
| Symptom | Root cause | Fix |
|---|---|---|
Invalid type for object 400 from client.Apply |
Missing TypeMeta on the desired object |
Set desired.TypeMeta = metav1.TypeMeta{APIVersion: ..., Kind: ...} explicitly |
| HPA and operator flap between two replica counts | Operator's desired object includes spec.replicas; SSA recorded ownership |
Remove the field from the builder; let HPA own spec.replicas alone |
Apply failed: conflict with "kustomize-controller" on every reconcile |
client.ForceOwnership is not set and a legitimate co-owner is touching the field |
Decide: drop the field (other manager is the authority) or pass client.ForceOwnership (your operator is the authority) |
| Fields silently disappear after switching to Apply | Manager previously owned them via Update, then Apply omitted them — server treated that as a release |
Either include those fields in the Apply payload (you do own them) or accept the release (you do not) |
| Three reconcilers in one binary fight over the same fields | All using client.FieldOwner("my-operator") |
Use distinct fieldManagers per controller: my-operator/Memcached, my-operator/Backup, etc. |
Renaming the fieldManager causes a flood of conflicts |
New name has to re-claim every field; old name still exists as an orphaned managedFields entry |
Plan a maintenance window; run a one-off migration script that strips the old entry and applies under the new name |
| SSA still produces "object has been modified" sometimes | You called r.Get(...) then r.Update(...) somewhere in the flow — r.Patch(... client.Apply) is the only true SSA path |
Audit reconciler for stray Update calls; convert each one or leave it as a deliberate exception with a comment |
Summary
Server-Side Apply is the modern, controller-co-friendly way to write Kubernetes objects from an operator. Instead of sending the full object with a fresh resourceVersion, the operator declares the small set of fields it owns and tags the request with a stable fieldManager. The API server tracks ownership in metadata.managedFields, atomically merges your changes with everyone else's, and surfaces conflicts as clean errors when two managers want the same field. The result is fewer "object has been modified" loops, peaceful coexistence with HPAs and sidecar injectors, and a real audit trail of who changed what.
The practical playbook is small: use client.Apply with a stable client.FieldOwner per controller; build a desired object that contains only the fields you genuinely own; do not pass client.ForceOwnership until you have spent a day or two looking at the conflicts your operator produces; and migrate from Update one object kind at a time, with a shadow phase before each cutover. Do those four things and SSA will quietly remove an entire class of bug from your operator that you used to spend pull requests papering over.
For the broader operator playbook this fits into — the reconcile loop, multi-resource reconciliation, owner references and GC, watches and predicates, and the rest — the Kubernetes Operator Tutorial course hub is the index. SSA is the foundation on which most of the advanced articles build, so getting comfortable with it now pays off everywhere downstream.
Frequently Asked Questions
1. What is Server-Side Apply in Kubernetes?
fieldManager name. The API server tracks each manager's ownership in metadata.managedFields, merges the new fields with the existing object, and rejects writes where another manager already owns the same field - unless the client explicitly sets force: true. SSA replaces the older client-side three-way merge that strategic-merge-patch and kubectl apply (without --server-side) traditionally used.2. Why should an operator use SSA instead of Update?
resourceVersion; under contention the operator retries forever. SSA sends only the operator's own fields and merges atomically. (2) Multiple controllers can co-own one object safely. An HPA owns spec.replicas, your operator owns the rest of the Deployment - neither overrides the other. (3) Drift correction is automatic. Any field the operator did not include in its Apply request is left alone, so non-operator-managed fields (labels added by humans, sidecars injected by other webhooks) survive reconciliation.3. What is a FieldManager and how do I pick one?
client.FieldOwner("memcached-operator"). The convention: one fieldManager per controller, named after the controller (or <group>/<kind>). Different controllers in the same operator binary should use different fieldManagers so the API server can attribute ownership correctly. Do not reuse kubectl or kube-controller-manager - those are reserved by other tooling and will cause confusing conflict messages.4. What does it mean when SSA returns a conflict?
force: true. The error body lists each conflicting field path. The right response depends on intent: if your operator is the authoritative source for that field, retry with Force. If the other manager is the authority (an HPA, a sidecar injector), drop the field from your Apply request entirely - you should not be sending it.5. When should I use Force conflicts in SSA?
kubectl edit, a misbehaving controller wrote a default). Do not use Force as a way to silence conflicts you do not understand - that just hides the design problem. The rule of thumb: Force is safe when the field is in your CRD-defined contract for the workload (e.g. the Deployment's spec.template.spec.containers[0].image); unsafe when the field is genuinely shared (a label sidecar injectors mutate).6. How is SSA different from strategic merge patch?
managedFields to know what is yours vs. someone else's. SSA is more robust because the server has stable knowledge of ownership; SMP requires the client to read the object first and compute a delta, which races under contention.7. Can I mix Update and Apply in the same operator?
8. How do I migrate an existing operator from Update to Apply?
client.FieldOwner("my-operator")). (2) Convert each r.Update(ctx, &obj) into building a desired-state object and calling r.Patch(ctx, &desired, client.Apply, fieldOwner). The desired object should contain ONLY the fields your operator is the source of truth for. (3) Run a shadow phase where you log the would-be Apply but keep doing Update - verify the diff is small. (4) Cut over in a release; monitor for unexpected conflicts in the first 24 hours. The hardest part is item (2) - deciding what fields you really own.9. Should I use SSA for the status subresource?
.status subresource has exactly one writer (your controller) and no co-owners by design, so the canonical pattern is r.Status().Update(ctx, cr) guarded by an equality.Semantic.DeepEqual check (see status subresource and Conditions). SSA on status is only worth the extra complexity if you genuinely have multiple controllers writing to the same .status.conditions slice and need atomic field-level merging - rare. The corresponding RBAC is the same either way: verbs: [get, update, patch] on <plural>/status (see operator RBAC minimum permissions).10. How does SSA interact with multi-tenant operators?
fieldManager per tenant - e.g. client.FieldOwner(fmt.Sprintf("memcached-operator/%s", tenantNs)). If every per-tenant manager applies as the same string, SSA cannot tell them apart in managedFields, conflict reporting becomes useless, and audit trails lose the tenant dimension. The same convention applies to the operator-per-tenant pattern - each tenant pod gets its own fieldManager string scoped to the tenant namespace.Further reading
- External: the Server-Side Apply Kubernetes documentation, the KEP-555 design document, and the controller-runtime client API reference.
