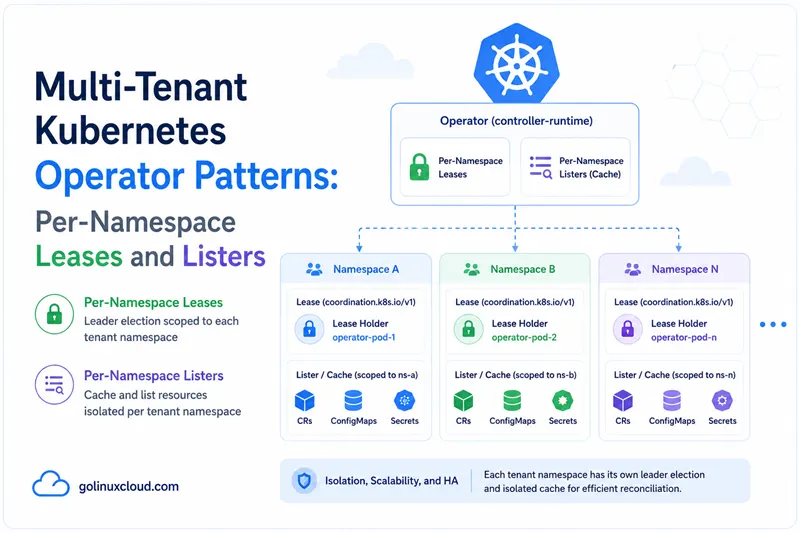
The interesting design space for any non-trivial operator is multi-tenancy. The "single binary, single lease, watches everything" shape is fine for a CI cluster but breaks down the moment you have customers in the same cluster with different SLOs, different security postures, or different blast-radius requirements. The good news: there are exactly three reusable patterns for multi-tenant operators, they all build on primitives controller-runtime already gives you, and the choice between them is mostly about trust model and budget.
This guide walks through the three patterns end-to-end: when each applies, the controller-runtime mechanics, and the operational realities (cost, upgrade story, blast radius). The patterns assume you have already worked through how the controller-runtime Manager and cache decide scope — multi-tenancy is the next layer above scope.
This is part of the Advanced Capabilities chapter. Prerequisites: leader election explained, RBAC minimum permissions, controller-runtime architecture, and watches, events, and predicates (cache-layer filtering is what makes per-namespace listers cheap).
TL;DR — multi-tenant operator patterns in 60 seconds
Three patterns, in order of increasing isolation:
| Pattern | One pod | Per-tenant lease | Per-tenant RBAC | Per-tenant limits | Operational cost |
|---|---|---|---|---|---|
| Shared (cluster-scoped) | ✅ | ❌ | ❌ | ❌ | Low |
| Hybrid (single binary, per-namespace leases) | ✅ | ✅ | ⚠️ partial | ❌ | Medium |
| Operator-per-tenant | ❌ (one per tenant) | ✅ | ✅ | ✅ | High |
The decision matrix:
- Tenants mutually trust each other (one organisation, multiple teams, similar SLOs) → Shared.
- Tenants need failure isolation but trust each other enough to share a pod (one organisation, larger scale, want noisy-neighbour protection) → Hybrid.
- Tenants are untrusted, or compliance demands per-tenant blast radius (multi-org SaaS, regulated workloads, distinct billing) → Operator-per-tenant.
Pick the pattern, then implement the mechanics. The mechanics are surprisingly small — controller-runtime gives you everything you need.
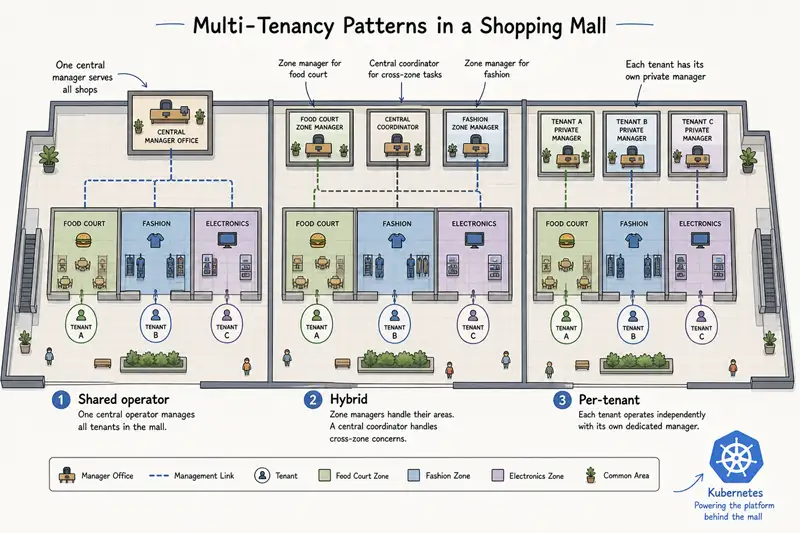
A quick analogy: shopping mall management styles
A shopping mall has many tenants (shops). The mall's management can be organised three ways:
- One head office, one set of rules, all shops watched by the same security team. Cheap, consistent, but if the head office is overwhelmed (a fire alarm) every shop's response is delayed. (Shared operator.)
- One head office, one mall-wide security team, but each shop has its own panic button that triggers their own response procedure. Same head office cost, but shop-level incidents are isolated — a stuck panic button in shop A does not delay response in shop B. (Hybrid.)
- Each shop has its own security guard, its own keys, its own panic button. Maximum independence, but the mall is now paying for many guards instead of one team. (Operator-per-tenant.)
The right answer depends on what kind of shopping mall you are running. A small family-run plaza with three friendly shops is fine with style 1. A regional mall with fifty mixed-tenant shops should at least be style 2. A high-security mall with bank branches, jewellers, and a pharmacy probably needs style 3.
| Mall management | Operator multi-tenancy |
|---|---|
| One head office for all shops | Shared cluster-scoped operator |
| Per-shop panic button + central security team | Hybrid (single binary, per-namespace leases) |
| Per-shop guards and keys | Operator-per-tenant |
| Mall-wide CCTV system | Cluster-scoped CRDs |
| Per-shop inventory system | Namespaced CRDs |
| Shopkeeper's master key to their own shop | RoleBinding scoped to one namespace |
| Security guard who can walk every floor | ClusterRoleBinding |
The analogy makes the cost calculation visible: more isolation costs more pods, more cluster operators, more upgrade orchestration. Most teams are at style 2 (hybrid) without realising it — they need failure isolation but not full identity isolation.
Prerequisites
- A working operator scaffolded by
kubebuilderoroperator-sdkwith a single Manager and cluster-wide RBAC. - Familiarity with the controller-runtime architecture — the Manager is what owns the cache, the leader lease, and the metrics endpoint; multi-tenancy is mostly about how many Managers you run and how you scope each one.
- Familiarity with leader election explained — multi-tenancy and leader election interact directly; per-namespace leases are the bedrock of the hybrid pattern.
- Familiarity with
watches, events, and predicates —
the
cache.Options.DefaultNamespacesselector this article uses is the same lever that makes a namespace-scoped lister cheap. - RBAC minimum permissions — the per-tenant RBAC choices live here.
Why operator multi-tenancy matters
Three reasons multi-tenancy is worth designing for before you hit the wall, not after:
1. The "single binary, single lease" shape has cluster-wide blast radius
A shared operator with one leader lease has exactly one reconcile loop serving every tenant. A wedged reconcile on tenant A's CR — a slow webhook, a stuck finalizer, a deadlocked external API call — starves every other tenant for the duration. On a busy cluster that can mean dozens of teams losing their reconcile loop because of one noisy CR. Per-namespace leases (the hybrid pattern) scope the wedge to its tenant; per-tenant pods (Pattern 3) scope it to the tenant's pod.
2. Noisy-neighbour effects are a workqueue problem, not a CPU problem
The kubernetes multi tenant operator failure mode is rarely "the
pod is out of CPU." It is "the workqueue is full of tenant A's
items and tenant B's CRs sit waiting." A single
workqueue with a fixed
MaxConcurrentReconciles is a fixed throughput budget; without
per-tenant queues, one tenant's burst (mass kubectl apply,
controller restart, label flip) drains the budget and produces
minutes of latency for everyone else. The metrics in
operator metrics — Prometheus are
the only place this shows up before customers complain.
3. The right pattern is irreversible-ish — choose deliberately
Moving from shared → hybrid is medium-effort (rewire main.go,
add per-namespace leases, fan out metrics ports). Moving from
shared → operator-per-tenant is high-effort (new packaging story,
new RBAC story, new upgrade story, fleet-management tooling).
Picking the wrong shape at v1 and rewriting at v3 — when you have
real customers depending on the v1 behaviour — is a multi-quarter
project. The good news: the decision matrix below is short, and
most teams pick correctly on the first try once they have it.
Pattern 1 — Shared operator (the default)
One operator deployment. One ServiceAccount with a ClusterRole. One leader lease. Every CR in every namespace is reconciled by the same worker pool.
This is what operator-sdk init gives you out of the box. It is correct for:
- Internal platform operators where tenants are teams in the same organisation.
- Operators with a small number of CRs (< 100) where noisy-neighbour effects are negligible.
- Operators in CI clusters and dev environments.
Code shape — nothing special in main.go:
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
LeaderElection: true,
LeaderElectionID: "memcached-operator-leader",
})Operational properties:
- Upgrade is one Deployment rollout. All tenants get the new version simultaneously.
- Blast radius is the whole cluster. A panic in Reconcile, a wedged finalizer on one CR, or a stuck external API call takes down reconciliation for every tenant.
- Resource limits are shared. One tenant's bursty workload can starve everyone else.
- RBAC is undifferentiated. The operator sees every CR with the same identity.
Most operators start here and stay here. The decision to move beyond shared is driven by an actual incident or a customer requirement, not by speculation.
Pattern 2 — Hybrid (per-namespace leader leases)
One binary, one deployment, but multiple controllers — one controller per watched namespace, each with its own workqueue and its own leader lease. From a Kubernetes perspective this looks like one pod; from a controller-runtime perspective it is many controllers cooperating inside one Manager.
This is the pattern that captures the "namespace-scoped behaviour" of an operator-per-tenant without the pod-per-tenant overhead. The trick is to use ctrl.NewManager to construct multiple manager instances, each with its own LeaderElectionNamespace, and run them concurrently:
// Conceptual sketch — production code factors this into a setup helper.
namespaces := []string{"team-a", "team-b", "team-c"}
mainCtx := ctrl.SetupSignalHandler()
for _, ns := range namespaces {
cfg := ctrl.GetConfigOrDie()
mgr, err := ctrl.NewManager(cfg, ctrl.Options{
Scheme: scheme,
Cache: cache.Options{
DefaultNamespaces: map[string]cache.Config{ns: {}},
},
LeaderElection: true,
LeaderElectionID: "memcached-operator-leader",
LeaderElectionNamespace: ns,
// Each manager has its own metrics port to avoid bind clashes.
// offsetFor() is any deterministic ns → small-int mapping;
// a stable hash of the namespace name works fine.
Metrics: server.Options{
BindAddress: fmt.Sprintf(":%d", 8080+offsetFor(ns)),
},
})
if err != nil {
return err
}
if err := (&MemcachedReconciler{Client: mgr.GetClient(), Scheme: mgr.GetScheme()}).
SetupWithManager(mgr); err != nil {
return err
}
go func(m manager.Manager) {
if err := m.Start(mainCtx); err != nil {
log.Error(err, "manager exited")
}
}(mgr)
}
<-mainCtx.Done()What this gives you:
- Per-namespace leader election. Lease
memcached-operator-leaderexists inteam-a, another inteam-b, etc. A wedged reconcile inteam-adoes not delayteam-b. - Per-namespace workqueue. Burstiness in one tenant does not consume the global worker pool.
- Per-namespace cache. Memory cost is proportional to objects you actually watch per tenant.
What it does not give you:
- Per-tenant identity. All managers share the same ServiceAccount. RBAC must therefore cover the union of all watched namespaces.
- Per-tenant resource limits. All managers run in the same pod, sharing CPU/memory limits.
- Per-tenant upgrade. A rollout updates every tenant's controllers simultaneously.
For most "noisy neighbour" complaints, this is the right pattern. You get fault isolation without the operational tax of a pod-per-tenant.
A simpler variant: keep a single Manager, single lease, but use controller predicates and MaxConcurrentReconciles to ensure each namespace gets a fair share. Effective for soft isolation but does not give you per-namespace leader election.
Pattern 3 — Operator-per-tenant
Each tenant runs their own operator deployment in their own namespace, with their own ServiceAccount, their own RBAC (scoped to that namespace), their own resource limits, their own metrics endpoint. From the cluster's perspective there are N operators serving N namespaces.
This is the strongest isolation pattern. Use it when:
- Tenants are mutually untrusted (multi-org SaaS, regulated workloads).
- Per-tenant resource accounting (showback, chargeback) matters.
- Per-tenant blast radius is a compliance requirement.
- You can absorb the operational cost — N tenants means N upgrade events, N metric streams, N pod startups per cluster restart.
The operator code is identical to the namespace-scoped operator pattern. The Helm chart or Operator Bundle is parameterised by tenant namespace and installed N times. The only operational novelty is fleet management — orchestrating updates across many independent installs (Argo CD ApplicationSets and ACM placement rules are the usual answer).
A subtle point: with N independent operator pods, you pay N times the baseline operator memory and CPU. For an operator with a 200 MB resident set, 50 tenants is 10 GB just to run idle reconcile loops. Hybrid pattern is often the right compromise.
Implementing per-tenant isolation in a shared operator
If you stick with the shared pattern but want some isolation, three knobs help:
1. Separate workqueues per namespace — each namespace's CRs go into a separate queue and have a separate worker pool. controller-runtime does not expose this directly; you implement it by registering one controller per namespace (the hybrid pattern's manager-per-namespace setup is the canonical way).
2. Per-tenant MaxConcurrentReconciles — different tenants get different concurrency budgets. Useful if one tenant pays for premium SLOs.
3. Tenant-aware error reporting — your reconciler emits Prometheus metrics labelled by tenant namespace, so dashboards can show per-tenant reconcile latency, error rates, and queue depth. Avoid leaking tenant identifiers as labels in every operator metric (high cardinality); restrict to the few that matter. The same caveat applies to per-tenant .status.conditions writes — the right answer is "one Condition per CR" not "one metric per CR."
// Per-tenant metric.
var reconcileErrors = prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "memcached_operator_reconcile_errors_total",
Help: "Reconcile errors, labelled by tenant namespace.",
},
[]string{"namespace"},
)
func (r *MemcachedReconciler) Reconcile(...) (ctrl.Result, error) {
// ...
if err != nil {
reconcileErrors.WithLabelValues(req.Namespace).Inc()
return ctrl.Result{}, err
}
return ctrl.Result{}, nil
}A worked example: building hybrid mode
Concrete code that runs N namespace-scoped managers from one binary. The interesting bits:
type tenant struct {
namespace string
metricsPort int
}
func runTenants(ctx context.Context, tenants []tenant) error {
g, ctx := errgroup.WithContext(ctx)
for _, t := range tenants {
t := t
g.Go(func() error {
cfg := ctrl.GetConfigOrDie()
// Custom client QPS per tenant if needed.
cfg.QPS = 30
cfg.Burst = 60
mgr, err := ctrl.NewManager(cfg, ctrl.Options{
Scheme: scheme,
Cache: cache.Options{
DefaultNamespaces: map[string]cache.Config{t.namespace: {}},
},
LeaderElection: true,
LeaderElectionID: "memcached-operator-leader",
LeaderElectionNamespace: t.namespace,
LeaderElectionResourceLock: resourcelock.LeasesResourceLock,
Metrics: server.Options{
BindAddress: fmt.Sprintf(":%d", t.metricsPort),
},
})
if err != nil {
return fmt.Errorf("manager for %s: %w", t.namespace, err)
}
if err := (&MemcachedReconciler{
Client: mgr.GetClient(),
Scheme: mgr.GetScheme(),
Recorder: mgr.GetEventRecorderFor(fmt.Sprintf("memcached-operator-%s", t.namespace)),
}).SetupWithManager(mgr); err != nil {
return err
}
return mgr.Start(ctx)
})
}
return g.Wait()
}Four production notes:
errgroupis the right primitive — if any manager dies, the context cancels and every other manager shuts down cleanly. This is critical for graceful shutdown.- Per-tenant
cfg.QPSlets you give premium tenants more API budget. The total across tenants must still fit in the API server's APF allocation for the operator's ServiceAccount. - Distinct metrics ports prevent address-in-use crashes on startup. Aggregate them with a Prometheus scrape config that knows about all the ports.
- Distinct
fieldManagerper tenant if you use Server-Side Apply for writes. Setclient.FieldOwner(fmt.Sprintf("memcached-operator/%s", t.namespace))so SSA's field-ownership graph mirrors the tenant boundary; otherwise every per-tenant manager looks identical to the API server and conflict reporting is useless.
Common pitfalls
Pitfall 1 — Sharing a single ResourceLock across tenants.
If every tenant's controller uses the same Lease (e.g. all pointing at kube-system/memcached-operator-leader), they all elect one leader and the per-tenant isolation disappears. Always set LeaderElectionNamespace per tenant in hybrid mode.
Pitfall 2 — High-cardinality tenant labels on every metric.
A metric like controller_runtime_reconcile_total{controller="memcached", namespace="team-a"} is fine. But labelling every internal histogram with tenant namespace explodes Prometheus cardinality. Pick 3–5 high-value metrics for per-tenant labelling; leave the rest aggregate.
Pitfall 3 — Forgetting per-namespace RBAC.
In hybrid mode, you might assume the operator's ClusterRole covers everything. It does, but RoleBindings in each watched namespace still need to exist if you want kubectl-style "who-can" introspection to show per-tenant scope. Generate RoleBindings even when ClusterRoleBindings are present, for auditability.
Pitfall 4 — Per-tenant upgrade without coordination.
In operator-per-tenant mode, each tenant's Helm chart is on a different version. If a CRD upgrade is required, every tenant must be upgraded together — otherwise some tenants see v1alpha1 while others see v1. Use a conversion webhook and coordinate releases via Argo CD ApplicationSets.
Pitfall 5 — Missing per-tenant resource limits in operator-per-tenant.
The whole point of pod-per-tenant is per-tenant resource accounting. Without requests and limits on each operator pod, you lose this benefit and you are paying for many pods without isolation. Always set per-tenant limits and a per-tenant ResourceQuota in the tenant namespace.
Pitfall 6 — Cross-tenant leakage via shared informers.
Even in hybrid mode, the controller-runtime cache is per-manager. If you ever share a cache or client across tenants for "efficiency", you have just punched a hole through the isolation boundary. Keep each manager self-contained.
Pitfall 7 — Assuming hybrid scales to hundreds of tenants.
One pod running 50 managers is heavy — 50 sets of informers, 50 leader-election loops, 50 metric registries. The practical ceiling is 20–30 tenants per pod. Past that, you want operator-per-tenant or a horizontal split of the hybrid pod (10 tenants per pod × 5 pods).
Pitfall cheat sheet
| Symptom | Root cause | Fix |
|---|---|---|
| Hybrid pod elects one leader across all tenants | Pitfall 1 — every tenant uses the same LeaderElectionNamespace (or it is unset) |
Set LeaderElectionNamespace: ns per manager; verify with kubectl get lease -A showing one Lease per tenant namespace |
| Prometheus pod OOMs after the operator goes multi-tenant | Pitfall 2 — every internal histogram labelled with tenant_namespace |
Restrict tenant labels to 3–5 high-value metrics (reconcile_errors, reconcile_time, workqueue_depth); leave the rest aggregate |
| Audit / "who-can" tooling shows the operator with cluster-wide scope even though hybrid is meant to be tenant-scoped | Pitfall 3 — only ClusterRoleBinding exists |
Generate per-tenant RoleBindings too, so the namespaced scope is visible to auditors |
| Operator-per-tenant uses 10× the memory of shared, with no observable isolation benefit | Pitfall 5 — no per-pod requests/limits and no per-namespace ResourceQuota |
Always pair pod-per-tenant with both — otherwise you are paying the cost without buying the isolation |
| Tenant A's CR mysteriously appears in tenant B's reconcile metrics | Pitfall 6 — a shared cache/client was introduced for "efficiency" | Each Manager must own its cache and client end-to-end; never share across tenant boundaries |
Hybrid pod starts crashing with bind: address already in use after adding a tenant |
Distinct metrics ports collided | offsetFor(ns) must be a stable, collision-free hash; the simplest safe variant is 8080 + sort.Search(allNamespaces, ns) |
| 30+ tenants per pod, CPU pegs at 1 core idle | Pitfall 7 — too many managers per pod | Horizontally split: 10 tenants per pod × N pods, with a deterministic tenant→pod assignment |
Further reading
- Kubernetes: Multi-tenancy · API Priority and Fairness
- controller-runtime:
Manager.LeaderElectionNamespace - client-go:
resourcelock - Internal: · · · · · · · · · ·
Frequently Asked Questions
1. What is multi-tenancy in the context of operators?
2. Why would I want per-namespace leader leases?
kube-scheduler and kube-controller-manager — both could in theory run as cluster-wide singletons but use leader election with per-scope leases to limit the blast radius.3. How does namespace-scoped listing differ from cluster-scoped listing?
4. Should each tenant have their own operator pod?
5. What is "noisy neighbour" in operator multi-tenancy?
6. How do I do per-tenant RBAC in a shared operator?
7. Can I run multiple operator instances in the same cluster for redundancy?
8. How does Server-Side Apply interact with multi-tenant operators?
fieldManager string when calling client.Apply with Server-Side Apply. If every per-namespace manager applies as "memcached-operator", SSA cannot tell them apart and conflict reporting becomes useless. A safe convention is memcached-operator/<tenant-namespace> so the SSA field-ownership graph mirrors the tenant boundary. The same rule applies to operator-per-tenant — each tenant pod gets its own fieldManager.9. When should I pick the hybrid pattern over operator-per-tenant?
Summary
Multi-tenant operators are a small variation on the patterns you have already learned. There are exactly three shapes — shared, hybrid, operator-per-tenant — and the choice between them is mostly about trust model and budget, not about technology. Each shape uses primitives controller-runtime already gives you (per-namespace caches, per-namespace leases, per-controller workqueues); the design work is selecting which combination matches your tenants' requirements.
The shopping-mall analogy keeps the trade-offs visible: one head office for friendly tenants, per-shop panic buttons for failure isolation, per-shop guards for hard isolation. More isolation costs more — more pods, more upgrade orchestration, more configuration. Most teams settle into the hybrid pattern because it captures the failure-isolation benefits without paying for per-tenant pods.
Three rules to live by:
- Default to shared until an actual incident or requirement forces hybrid.
- Move to operator-per-tenant only when tenants are mutually untrusted or compliance demands per-tenant blast radius.
- In hybrid mode, separate leases AND separate caches AND separate metrics — half-measures leak isolation.
The capabilities chapter ends here. Once you have multi-tenancy figured out, the next concerns are observability (operator metrics — Prometheus and health and readiness probes) and how all of this fits in the larger operator picture (the Kubernetes Operator tutorial — full course hub).
