
A user runs kubectl apply to express desired state on .spec. The
controller runs Reconcile() and discovers what the actual state of the
world is. The status subresource is how the controller publishes that
discovery back to the API so users, CI/CD pipelines, peer controllers, and
kubectl wait know what is going on. Get this surface right and your
Operator integrates cleanly with every other tool in the Kubernetes
ecosystem; get it wrong and users have no idea whether the resource is
ready, failing, or still in flight.
This guide covers why the status subresource exists separately from .spec,
the KEP-1623 Conditions standard, the meta.SetStatusCondition helper, the
observedGeneration field, and the reconcile hot-loop trap that catches
almost every first-time Operator author writing status updates.
The split-URL design:
/specis the user's lane,/statusis the controller's lane. The conditions array is the structured language they use to communicate.
If you have not yet read desired state vs actual state and the reconcile loop explained, those two articles set up why the split exists; this one is how to use it cleanly.
TL;DR — status & conditions in 60 seconds
The status subresource is a separate URL the API server exposes for each custom resource:
| Endpoint | Who writes | What lives there |
|---|---|---|
/apis/<g>/<v>/.../<plural>/<name> |
Users via kubectl apply |
metadata, .spec |
/apis/<g>/<v>/.../<plural>/<name>/status |
Controllers via r.Status().Update() |
.status only |
A Condition is a structured entry in .status.conditions describing one
observable property of the resource. Every controller in the ecosystem now
uses the same shape, standardised by
KEP-1623:
status:
observedGeneration: 7
conditions:
- type: Ready
status: "True"
reason: ReconcileSucceeded
message: "All backup targets are healthy"
lastTransitionTime: "2026-05-31T10:31:12Z"
observedGeneration: 7Status subresource enabled? Verify with
kubectl get crd <plural>.<group> -o jsonpath='{.spec.versions[0].subresources}'
- the output should contain
"status":{}. Without it,r.Status().Update()writes through to.specand you get cross-lane races. See Custom Resource Definitions explained for how to declare the subresource in the CRD YAML.
A quick analogy: an Amazon order page
Picture an Amazon order page.
- What you ordered — "1 pair of running shoes, size 10, deliver by
Tuesday" — is your
.spec. You wrote it. You can change it (with caveats) up until shipment. - What you see on the order page — "Order placed → packed → shipped →
out for delivery → delivered" — is your
.status. Amazon writes it. You never write to that field — and if you somehow could, you would trample over Amazon's tracker. - The little status tags "Packed", "Out for delivery", "Delivered" — each with a timestamp and a short explanation — are Conditions.
![]()
Now imagine if Amazon let you accidentally edit "Delivered: True" on a
package that was still in the warehouse. Chaos. That is exactly why
Kubernetes split /spec and /status into two URLs — the user writes
one, the controller writes the other, and they cannot accidentally
overwrite each other's lanes.
The KEP-1623 condition standard is what makes the status tags consistent across every Operator in the world, the same way every shipping company ended up with the same vocabulary: Packed, In transit, Out for delivery, Delivered. Once you know the words, every package — and every custom resource — speaks the same language.
Why status and conditions matter
Three concrete reasons it is worth getting this surface right, rather than
treating .status as a free-form scratch area:
1. It is the contract every ecosystem tool expects
kubectl wait --for=condition=Ready, Argo CD, Flux, Helmfile, Backstage,
the Operator dashboard in the OpenShift console — they all read the
.status.conditions array and they all expect the
KEP-1623 polarity-positive types (Ready=True is the good state).
The moment you publish a non-standard Phase enum or invert the polarity
("NotReady=False"), every downstream tool stops working — silently,
because they will not crash, they will simply wait forever for a condition
that never appears.
2. It is the only thing peer controllers can react to
Operators chain on each other all the time — a CertificateRequest
controller waits for a Backup controller, which waits for a
PostgresCluster controller. The only public surface they share is each
other's .status. If your status is unreliable, every operator that
depends on you is unreliable too. Different
operator design patterns (Singleton,
Lifecycle, Auto-Pilot) demand different status shapes, but they all live or
die on the same contract.
3. observedGeneration is how CI/CD knows your change landed
Every GitOps tool watches for observedGeneration == metadata.generation before it considers a rollout complete. Omit it once
and your CI pipelines will start acting on stale conditions — marking
deployments green minutes before the controller has actually caught up to
the new .spec. This is the single most common cause of "my pipeline
passed but production is broken" on Operator-managed workloads.
The KEP-1623 Conditions standard
Before KEP-1623 every project invented its own status schema - some used a
phase: Pending|Running|Failed enum, some used a free-form message, some
nested conditions inside conditions. The fragmentation broke ecosystem tools
like kubectl wait, GitOps controllers, and Operator dashboards.
KEP-1623
standardised the shape every condition must take. The metav1.Condition
struct is defined in k8s.io/apimachinery/pkg/apis/meta/v1:
type Condition struct {
Type string // PascalCase, "Ready", "Progressing"
Status ConditionStatus // "True" | "False" | "Unknown"
ObservedGeneration int64 // metadata.generation when written
LastTransitionTime metav1.Time // when Status last flipped
Reason string // machine-readable, no spaces
Message string // human-readable
}Three rules from the KEP that catch every Operator author:
- Polarity-positive types only.
Ready=Trueis the good state.NotReadyis not a valid type - useReady=False. The convention avoids double-negatives in dashboards (NotReady=Falseis unreadable). Reasonmust be aCamelCasetoken, not a sentence. Good:ReconcileSucceeded,EndpointNotResolvable. Bad:reconcile succeeded.LastTransitionTimeupdates only whenStatusflips. Re-reconciles that confirm the same state must not bump the timestamp - otherwise every dashboard shows constantly-changing state.
meta.SetStatusCondition (in k8s.io/apimachinery/pkg/api/meta) implements
these rules correctly and is the only sensible way to append-or-update a
condition:
import (
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/apimachinery/pkg/api/meta"
)
meta.SetStatusCondition(&backup.Status.Conditions, metav1.Condition{
Type: "Ready",
Status: metav1.ConditionTrue,
ObservedGeneration: backup.Generation,
Reason: "ReconcileSucceeded",
Message: "All backup targets are healthy",
})The helper handles three things you do not want to write yourself:
- If a condition of the same
Typealready exists, it is updated in place (not appended again). LastTransitionTimeis bumped only whenStatusactually flips.- The output array is kept sorted by
Typefor stable diffs inkubectl get -o yaml.
The four standard condition types
KEP-1623 does not mandate a fixed list, but the ecosystem has converged on four polarity-positive types that you should publish in almost every Operator:
| Type | True means | Example Reason codes |
|---|---|---|
Ready |
The resource is fulfilling its purpose right now. | ReconcileSucceeded when True; ReconcileError, BackupPolicyMisconfigured, WaitingForDependency when False |
Progressing |
The controller is actively reconciling toward the desired state. False simply means idle, not broken. | Reconciling when True; RolloutComplete when False |
Available |
The resource has at least the minimum capacity to serve users (e.g. enough replicas). | MinimumReplicasAvailable when True; MinimumReplicasUnavailable, EndpointNotResolvable when False |
Degraded |
Something is wrong, but the resource is still functioning - partial outage, not full failure. | OneOfThreeReplicasUnhealthy, SlowResponseTime when True (note: True is the bad state here) |
Degraded is the only condition where True is the bad state, kept that
way for backwards compatibility with pre-KEP usage. Many newer Operators omit
it; if you do publish it, document the polarity explicitly.
Not every resource needs every condition. A simple ConfigMap-like custom
resource may only need Ready. A controller managing a multi-node service
may publish all four. Pick the minimum that gives users actionable
information.
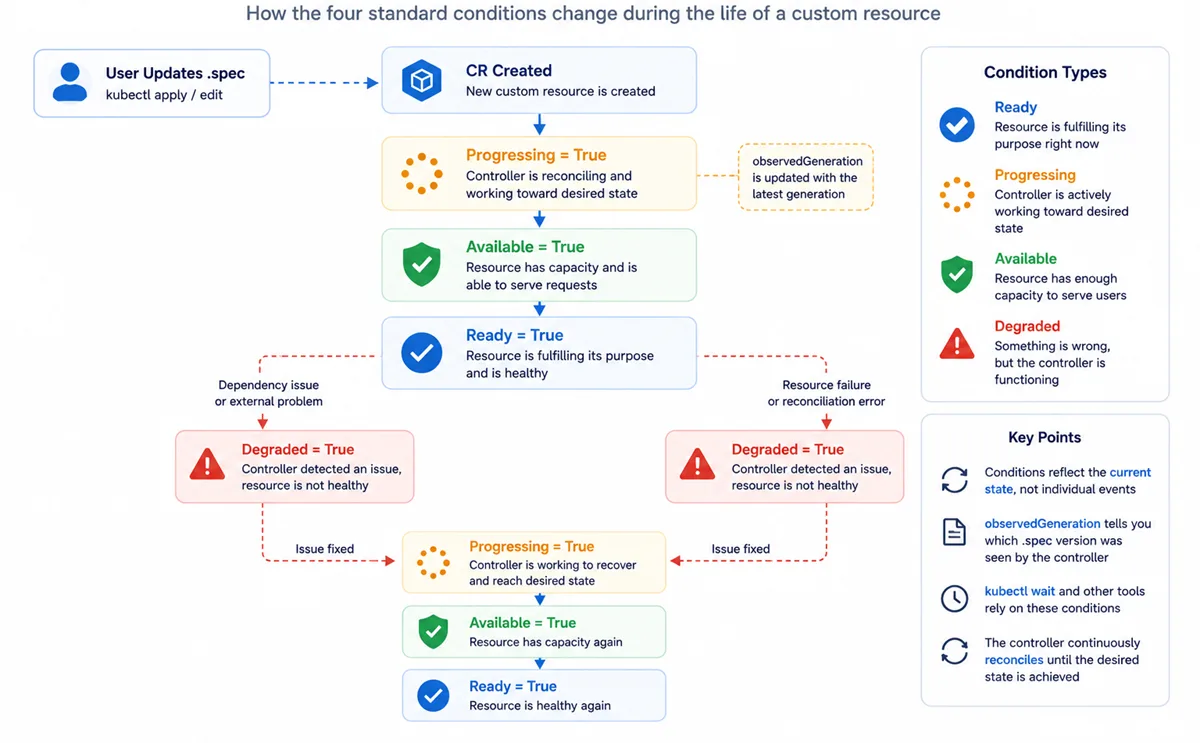
The diagram below shows a typical lifecycle for an Operator-managed resource.
Most resources start with Progressing=True while reconciliation is in
progress, eventually become Available=True and Ready=True, and may later
enter Degraded=True if the controller detects a problem. After recovery,
the resource transitions back through Progressing and returns to
Ready=True.
observedGeneration - the "is this status fresh?" field
metadata.generation is a 64-bit integer the API server increments every
time .spec is mutated. Status updates do not bump generation - it is
specifically the user-mutation counter.
observedGeneration is your controller's promise: "I have seen
generation = N and the conditions below describe that version of the
spec." When a user runs:
kubectl wait <kind> <name> --for=condition=Readykubectl checks both Status=True and observedGeneration == metadata.generation. If a stale status from before the latest user edit
still says Ready=True, kubectl wait does the right thing and keeps
waiting until the controller catches up.
In practice you set it on every condition you write:
meta.SetStatusCondition(&backup.Status.Conditions, metav1.Condition{
Type: "Ready",
Status: metav1.ConditionTrue,
ObservedGeneration: backup.Generation,
Reason: "ReconcileSucceeded",
Message: "All targets healthy",
})Some Operators also publish a top-level status.observedGeneration for the
whole resource - this is what newer KEP-1623 audits prefer. Either pattern
is acceptable as long as you pick one and stick to it. Operators that also
do periodic
drift detection typically expose
both: observedGeneration for "did I see the latest spec?" and a separate
lastSyncTime for "when did I last verify external state matches?".
How kubectl wait uses conditions
The most common consumer of .status.conditions is kubectl wait — used
by CI/CD pipelines, end-to-end tests, and kubectl rollout-style scripts
to block until a custom resource is ready before the next step runs.
# Wait up to 5 minutes for the backup to be Ready=True
kubectl wait backup nightly --for=condition=Ready=True --timeout=300s
# Wait for Progressing to drop back to False (rollout complete)
kubectl wait postgrescluster prod --for=condition=Progressing=FalseWhat kubectl wait --for=condition=<Type>[=<Status>] actually checks:
- The resource has a condition of the given
Typein.status.conditions. - The condition's
Statusmatches the requested value (defaults toTrue). observedGeneration == metadata.generation— the condition was written by the controller after the most recent.specchange.
Step 3 is why setting ObservedGeneration on every condition write
matters. Without it, a stale Ready=True from before the user's latest
kubectl apply would make kubectl wait return immediately — and your CI
would mark the rollout green before the controller has actually caught up.
Two patterns peer controllers and pipelines also use:
- JSONPath probe —
kubectl get <kind> <name> -o jsonpath='{.status.conditions[?(@.type=="Ready")].status}'returns the literal"True"/"False"/"Unknown". Useful in shell pipelines that cannot afford thekubectl waitwatch loop. - Full condition object —
kubectl get <kind> <name> -o json | jq '.status.conditions[] | select(.type=="Ready")'includesreasonandmessage, the easiest way to surface "why is it not ready?" in CI logs.
For consumers that do not want a separate kubectl wait step, your CRD's
additionalPrinterColumns can surface the same conditions inline:
additionalPrinterColumns:
- name: Ready
type: string
jsonPath: .status.conditions[?(@.type=="Ready")].status
- name: Reason
type: string
jsonPath: .status.conditions[?(@.type=="Ready")].reason
- name: Age
type: date
jsonPath: .metadata.creationTimestampNow kubectl get backup shows Ready / Reason / Age columns by default,
with no -o flag required — and pipelines can grep '^backup-name.*True'
as a quick readiness probe without parsing JSON.
Why split spec and status into two URLs?
The split solves three concrete problems that the original single-URL design suffered from in 2017-2018:
- Optimistic-concurrency clashes. When a user edited
.specand the controller updated.statusat almost the same instant, one of the twoUpdatecalls failed with a409 Conflictbecause both based their write on the sameresourceVersion. With the split, the two writes never touch the same field group. - RBAC granularity. A user role can have
get/list/updateon a custom resource without being able to write.status- the controller's ServiceAccount is the only thing withupdateon the/statusURL. This stops a curious user from manually marking a resourceReady=True. The per-subresource verbs (.../status) are part of why least-privilege Operator RBAC is easy to enforce in the first place. - Cleaner schema validation. The CRD schema's
subresources.status: {}declaration lets the API server fast-reject any request that tries to mutate the wrong half of the object.
Inside your controller, the two writes are one method call apart:
r.Update(ctx, &obj) // writes .metadata and .spec
r.Status().Update(ctx, &obj) // writes .status onlyA common newcomer bug is to call r.Update after setting conditions in
.status - the call succeeds but .status does not change, because the
non-/status endpoint silently drops status fields when the subresource is
enabled. Always use Status().Update() for status writes.
What belongs in .status (and what doesn't)
Newcomers routinely shove the wrong things into .status — desired
configuration, secrets, debug logs, free-form notes — and then wonder why
their operator becomes hard to reason about. The rule of thumb is simple:
.status is only for facts you have observed about the world and could
re-derive from the cluster if you restarted.
Belongs in .status |
Does not belong in .status |
|---|---|
| Observed external IDs (cloud resource ARNs, DB UUIDs) | Secrets, credentials, tokens |
Observed counts (readyReplicas, usedBytes, currentVersion) |
User input — that belongs in .spec |
| References to created child resources you own | Configuration that drives behaviour (also .spec) |
Conditions (KEP-1623) — Ready, Progressing, Available, Degraded |
A scratch field per reconcile (use the controller's in-memory cache) |
observedGeneration for freshness tracking |
Last-reconcile wall-clock (lastTransitionTime on a condition is the canonical place) |
A phase enum for human-readable summary (in addition to conditions) |
Anything you would have to guess if the controller restarted |
Three corollaries that follow from the rule:
- If a value cannot be re-derived from the cluster after a controller
restart, it does not belong in
.status— store it on an annotation, a child resource, or an external system. - Anything secret belongs in a
Secret, not in.status— status is world-readable to anyone withgeton the parent resource. - A
phaseenum can coexist with conditions, butReady/Progressing/Available/Degradedare still required because that is whatkubectl wait --for=condition=...and the rest of the ecosystem reads.
The full status-update pattern
A complete reconciler that handles spec, status, and the hot-loop trap:
func (r *BackupReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
var backup acmev1.Backup
if err := r.Get(ctx, req.NamespacedName, &backup); err != nil {
return ctrl.Result{}, client.IgnoreNotFound(err)
}
if !backup.GetDeletionTimestamp().IsZero() {
return r.reconcileDelete(ctx, &backup)
}
if err := r.ensureBackupTarget(ctx, &backup); err != nil {
return r.updateStatus(ctx, &backup, metav1.Condition{
Type: "Ready",
Status: metav1.ConditionFalse,
Reason: "EnsureTargetFailed",
Message: err.Error(),
})
}
return r.updateStatus(ctx, &backup, metav1.Condition{
Type: "Ready",
Status: metav1.ConditionTrue,
Reason: "ReconcileSucceeded",
Message: "Backup target is healthy",
})
}
func (r *BackupReconciler) updateStatus(ctx context.Context, b *acmev1.Backup, c metav1.Condition) (ctrl.Result, error) {
c.ObservedGeneration = b.Generation
original := b.DeepCopy()
meta.SetStatusCondition(&b.Status.Conditions, c)
if equality.Semantic.DeepEqual(original.Status, b.Status) {
return ctrl.Result{}, nil
}
if err := r.Status().Update(ctx, b); err != nil {
return ctrl.Result{}, err
}
return ctrl.Result{}, nil
}The five things to notice:
equality.Semantic.DeepEqualguard beforeStatus().Update(). This is the core hot-loop killer (see the next section). No-op status writes are skipped entirely. The helper lives ink8s.io/apimachinery/pkg/api/equalityand is preferred over the stdlibreflect.DeepEqualbecause it understandsmetav1.Timerounding,resource.Quantityequivalence, and other Kubernetes-specific semantics that the stdlib version reports as different.ObservedGenerationis set on every condition write. Cheap and gives every consumer the freshness signal they need.- One helper, one place where status is written. This is much easier
to test and review than scattering
Status().Update()calls across every error branch. - Errors update status with
Ready=Falseand return the error. The status update succeeds; the requeue from the returned error keeps the controller working on the real fix. r.Getalways returns the freshest cache copy. Do not stashbackupacross reconciles - the next invocation gets its own object from the cache.
Writing status with Server-Side Apply
For new operators, the recommended way to update status is Server-Side
Apply (SSA) rather than Status().Update(). SSA tracks per-field
ownership using a field manager, so two controllers that each set a
different condition type (e.g. yours sets Ready, cert-manager sets
CertificateReady) coexist without clobbering each other on read-modify-write:
patch := &unstructured.Unstructured{}
patch.SetGroupVersionKind(acmev1.GroupVersion.WithKind("Backup"))
patch.SetNamespace(backup.Namespace)
patch.SetName(backup.Name)
_ = unstructured.SetNestedSlice(patch.Object, []interface{}{
map[string]interface{}{
"type": "Ready",
"status": "True",
"reason": "ReconcileSucceeded",
"message": "Backup target is healthy",
"observedGeneration": backup.Generation,
},
}, "status", "conditions")
return r.Status().Patch(ctx, patch, client.Apply,
client.FieldOwner("backup-controller"),
client.ForceOwnership)See Server-Side Apply (SSA) in operators
for the full conflict-resolution rules and when to prefer SSA over
Status().Update().
The status-write hot loop (and how to kill it)
Every status update generates a fresh watch event, which triggers another reconcile, which may write status again. Without protection your operator pegs CPU. Two complementary defences:
Defence 1 - GenerationChangedPredicate{} on the primary watch
ctrl.NewControllerManagedBy(mgr).
For(&acmev1.Backup{}).
WithEventFilter(predicate.GenerationChangedPredicate{}).
Complete(r)This predicate only fires Update events when metadata.generation
differs - status-only updates do not bump generation, so they are dropped
before they reach the workqueue. See
watches, events, and predicates
for the full predicate catalogue.
Defence 2 - skip the API call when status is unchanged
The equality.Semantic.DeepEqual guard in the pattern above (from
k8s.io/apimachinery/pkg/api/equality). Even if a watch event sneaks past
the predicate, the API call is skipped when there is nothing new to
publish. Combined with meta.SetStatusCondition (which only updates
LastTransitionTime on a real flip), this turns the steady-state cost of
status maintenance to zero. Avoid the stdlib reflect.DeepEqual here — it
will spuriously report two semantically-identical statuses as different
whenever metav1.Time rounding or resource.Quantity normalisation comes
into play, defeating the guard.
Apply both. They cover slightly different failure modes - the predicate prevents every status-triggered reconcile from running, the deep-equal guard prevents some spec-triggered reconciles from writing status when nothing actually changed.
Status vs Events vs Annotations
Operators have three different surfaces for "telling the world something happened". Newcomers routinely pick the wrong one. The differences are sharper than they look:
| Surface | Schema | Typed | Atomic write | Survives controller restart | Best for |
|---|---|---|---|---|---|
.status |
CRD-validated | Yes | Yes (per-update) | Yes — lives on the resource | Stable, machine-readable observed state that other controllers and kubectl wait consume |
Event (corev1.Event) |
Loose | No | No (best-effort, deduped) | No — TTL ~1 h by default | Recent human-readable activity that shows up in kubectl describe |
| Annotation | map[string]string |
No | Yes | Yes — lives on the resource | Free-form metadata, opt-in feature flags, controller-internal hints |
Practical decisions you will make every week:
- "The backup failed because the target bucket is unreachable." Both —
set
Ready=FalsewithReason=TargetUnreachable(machine-readable, the thing peer controllers act on) and fire anEventof typeWarning(human-readable, the thing the user sees inkubectl describe backup). - "The user wants verbose logging for this one resource." Annotation
(
acme.io/log-level: debug) — free-form, opt-in, nothing else needs to validate it. - "The S3 backup completed at 14:32 and used 1.4 GiB."
.status— this is observed state that peer controllers and dashboards need.
Rule of thumb — if a downstream system needs to make a decision on it,
put it in .status. If a human needs to read it in kubectl describe,
fire an Event. If only your own controller needs to remember it, an
annotation is fine.
Status field selectors
When your CRD declares additionalPrinterColumns against .status paths,
kubectl uses the same paths for field selectors:
kubectl get backup --field-selector status.phase=Failed -AThe trick: status fields are only field-selectable if you list them in the
spec.versions[*].additionalPrinterColumns of the CRD. This is one of the
under-appreciated wins of putting real data in status - it becomes
queryable without users needing jq.
For consumers that just want a Boolean signal:
kubectl wait backup nightly --for=condition=Ready=True --timeout=300skubectl wait checks both Status and observedGeneration, so it is
the right tool for CI/CD pipelines and end-to-end tests.
The five anti-patterns that ship to production
-
Calling
r.Update()to write status. The non-/statusendpoint drops status changes silently when the subresource is enabled. Fix: alwaysr.Status().Update()for status writes. -
Writing status on every reconcile without a guard. Hot loop within seconds. Fix: an
equality.Semantic.DeepEqualguard (fromk8s.io/apimachinery/pkg/api/equality) before the API call. Prefer it over the stdlibreflect.DeepEqual— it knows aboutmetav1.Timerounding andresource.Quantityequivalence that the stdlib version reports as different. -
Not setting
ObservedGeneration.kubectl waitand GitOps tools cannot tell stale conditions from fresh ones. Fix: set it on every condition you write. -
Inventing a
Phaseenum instead of using conditions. Pre-KEP pattern; breakskubectl wait --for=condition=.... Fix: publishReady,Progressing,Available,Degradedeven if you keep aPhasefield for backward compatibility. -
Re-appending the same condition every reconcile. Without
meta.SetStatusConditionyou end up with a growing array of duplicateReady=Trueentries. Fix: use the helper - it updates in place byType.
Status anti-pattern cheat sheet
| Symptom | Root cause | Fix |
|---|---|---|
r.Status().Update() returns 200 but .status is empty in kubectl get -o yaml |
Called r.Update() (not the Status() sub-client), or CRD missing subresources.status: {} |
Use r.Status().Update(); verify CRD with kubectl get crd ... -o jsonpath='{.spec.versions[0].subresources}' |
| Operator pegs CPU after a single reconcile, etcd write rate climbs | Status hot loop — every Status().Update() triggers a fresh watch event |
Add predicate.GenerationChangedPredicate{} in SetupWithManager and an equality.Semantic.DeepEqual guard before the API call |
kubectl wait --for=condition=Ready returns instantly on a stale status |
observedGeneration not set on conditions |
Set ObservedGeneration: obj.Generation on every condition write |
Ready flickers True↔False every reconcile |
Manually appending conditions to the slice instead of using meta.SetStatusCondition |
Switch to meta.SetStatusCondition — it dedupes by Type and only bumps LastTransitionTime on a real flip |
kubectl wait --for=condition=Ready returns timeout for a resource that is clearly healthy |
Using a custom Phase: Ready enum instead of conditions |
Publish Ready + Progressing + Available conditions alongside any legacy Phase field |
Frequently Asked Questions
1. What is the status subresource in Kubernetes?
2. What is a Condition in Kubernetes?
3. What are the standard Kubernetes condition types?
4. What is observedGeneration in a Kubernetes condition?
5. Why is my operator stuck in a reconcile hot loop after a status update?
6. How do I update status in controller-runtime?
7. Should I use Status or annotations for observability data?
8. What is the difference between Kubernetes Events and the status subresource?
9. How do I write status with Server-Side Apply?
What's next?
You now know how to publish observed state cleanly. Natural next reads:
- Kubernetes finalizers explained —
the symmetric mechanism for deletion that lives in
metadatarather thanstatus, and why you need both for any Operator with external side-effects. - The Kubernetes reconcile loop explained —
the level-triggered control loop that the conditions and
observedGenerationfields describe. - Watches, events, and predicates —
the
GenerationChangedPredicate{}filter that protects you from the status-write hot loop. - Server-Side Apply (SSA) in operators — the modern, conflict-free way to publish status when multiple controllers share the same resource.
- Drift detection patterns in operators —
how
observedGenerationandlastSyncTimecooperate to keep controller-managed external state in sync. - Desired state vs actual state —
the wider rationale for why
.specand.statusare separated in the first place.
Looking for the bigger picture? The Kubernetes Operator tutorial sequences every article in this series in pedagogical order — this article is part of the controller-runtime internals chapter, alongside watches, finalizers, and owner references.
