Kubernetes Operators are not a single shape. Calling cert-manager, the Prometheus Operator, KEDA, and an Istio sidecar injector all "Operators" is correct, but it hides the fact that they solve very different problems and use very different internal architectures. Picking the wrong pattern is the single biggest cause of Operators that ship and never get adopted — the API feels awkward, the failure modes confuse users, and operators that should be simple end up looking like every other CRUD app.
This guide walks the six patterns that cover almost every Operator you will encounter or write, the real-world examples for each, and the rules of thumb for combining them when a single shape does not fit.
If you have not yet read What is a Kubernetes Operator? and Operator vs Controller vs CRD, those two articles set up the vocabulary used below.
TL;DR — the six patterns at a glance
| # | Pattern | One-line summary | Canonical example |
|---|---|---|---|
| 1 | Singleton | One controller per cluster, one logical responsibility. | cert-manager |
| 2 | Capability | High-level CRDs reconciled into low-level workloads. | Prometheus Operator |
| 3 | Lifecycle | Full day-0 / day-1 / day-2 ops of a stateful workload. | Zalando Postgres Operator |
| 4 | Auto-Pilot / Auto-Tune | Continuously self-optimises without user input. | KEDA, Vertical Pod Autoscaler |
| 5 | Sidecar-Injecting | Mutating webhook that rewrites Pods to add containers. | Istio, Linkerd, OPA Gatekeeper |
| 6 | GitOps-Controlled | Operator's CRs are themselves reconciled by a higher GitOps tool. | Crossplane + Argo CD |
You can think of these as orthogonal axes rather than mutually exclusive categories. cert-manager is "Singleton + Capability". The Postgres Operator is "Lifecycle + Auto-Pilot". This is normal — design patterns describe facets, not buckets.
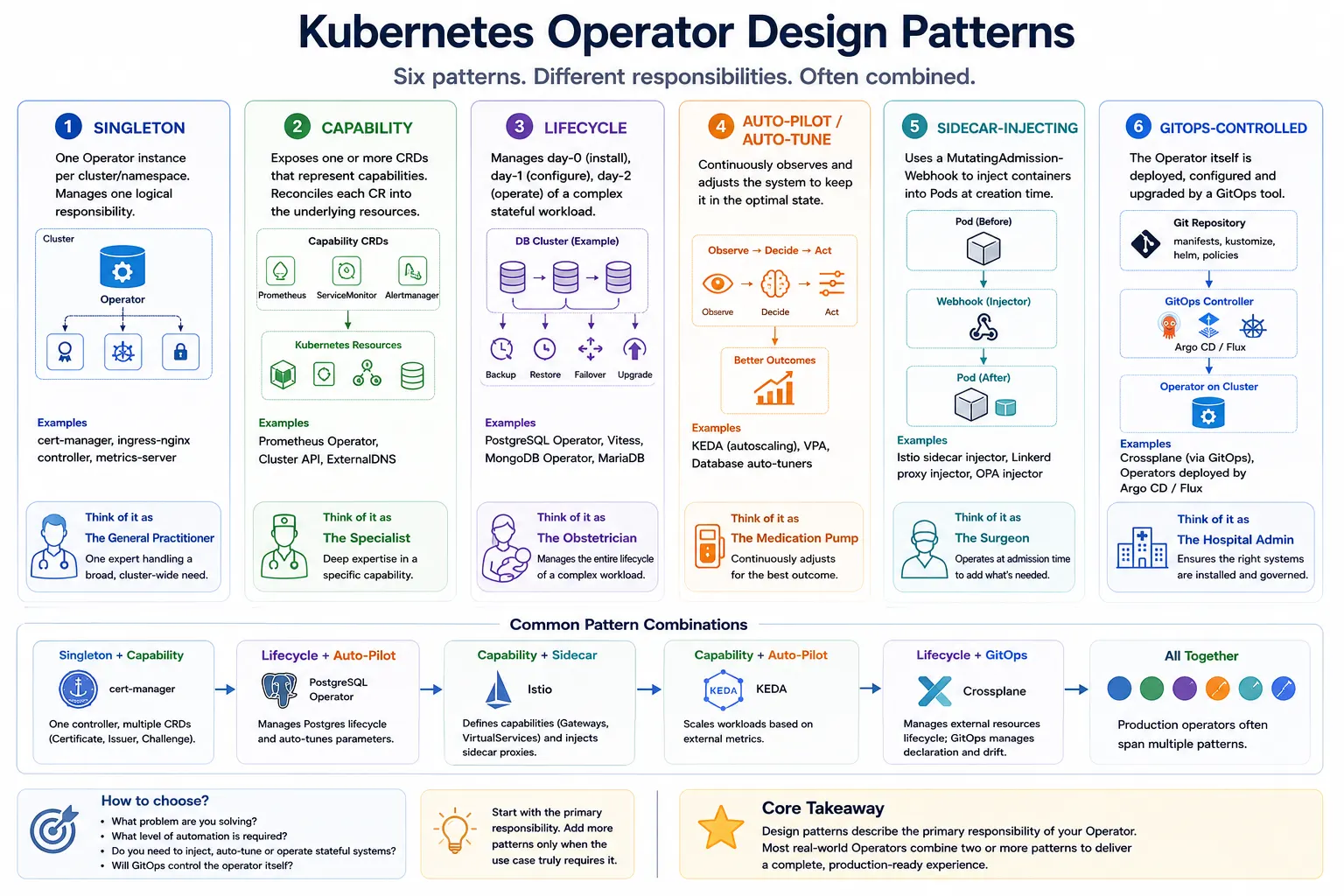
The table above is a useful reference, but real-world Operators rarely fit into a single box. Most production Operators combine multiple patterns depending on the responsibilities they need to fulfil. Keep this overview in mind as you read the detailed sections below.
For the Red Hat capability levels (I–V) that the OperatorHub submission process uses, see the companion article on the Operator capability levels and maturity model. Patterns are how an Operator is built; capability levels are how much it does.
A quick analogy: think of medical specialists
A hospital doesn't have one "doctor". It has a general practitioner for common care, specialists for focused domains, an obstetrician for multi-month processes, a smart medication pump that self-adjusts dosage, and an admin who tags every new arrival with a wristband. Kubernetes Operators work the same way — each pattern below is a role an Operator can fill, and a real Operator often wears two or three of those hats at once.
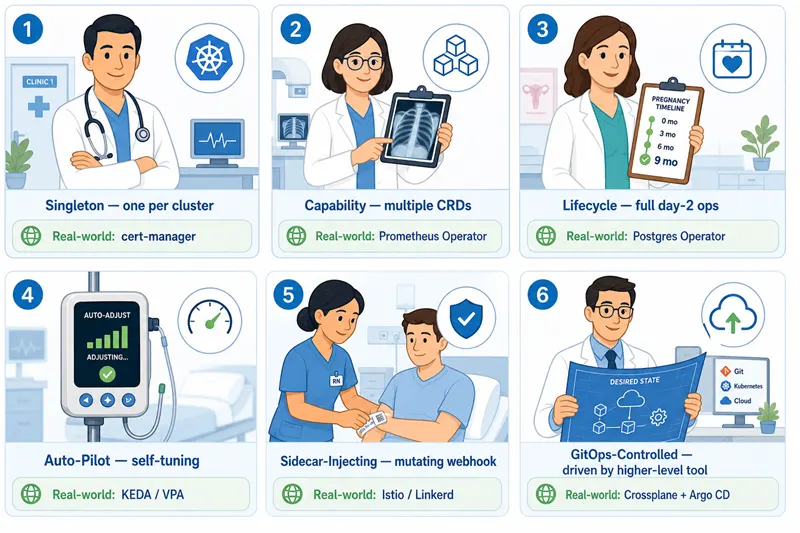
Different specialists for different problems. cert-manager is a GP; the Prometheus Operator is a specialist team; the Postgres Operator is an obstetrician + smart pump combined.
Why operator design patterns matter
Calling something "an Operator" without naming the pattern is like calling something "an application" — technically correct, useless for deciding anything about it. Three concrete reasons the pattern matters:
1. The API surface follows the pattern
A Singleton operator that exposes one cluster-wide CRD looks nothing like a Capability operator with five composing CRDs. Users learn your API through the pattern, not through the field-by-field schema. A user who has installed cert-manager (Singleton + Capability) can guess how a similarly-shaped operator works before reading any documentation.
2. Failure modes follow the pattern
Each pattern has a characteristic first failure:
| Pattern | What breaks first |
|---|---|
| Singleton | Lease loss, RBAC misconfiguration |
| Capability | Schema mismatch between CRDs |
| Lifecycle | State-machine transitions stuck in Progressing |
| Auto-Pilot | Runaway scale loop, oscillation |
| Sidecar-Injecting | Webhook unreachable — every Pod create in the cluster blocked |
| GitOps-Controlled | Drift war between the operator and the GitOps tool |
Picking the right pattern means picking the failure mode you can operationally tolerate. A Sidecar-Injecting operator has the highest blast radius of any pattern listed; a Capability operator's worst day affects only its own CRDs.
3. The wrong pattern is the #1 reason operators get abandoned
A Lifecycle-shaped CRD on a stateless workload feels bureaucratic. A
Singleton trying to do per-namespace tenancy hits RBAC complexity. A
Sidecar-Injecting webhook used for non-Pod kinds confuses every user who
runs kubectl describe. Users do not read your code — they read your
CRDs. If the CRDs look wrong for the responsibility, adoption stalls.
When you find yourself wanting to "extend" your operator with capabilities that feel foreign to the original pattern, that is usually a signal that you have a second pattern hidden inside the first. The Combining patterns section below covers when that is the right call.
1. The Singleton Operator pattern
The simplest pattern. A single Deployment (usually one replica with leader-election enabled, sometimes scaled to two or three for HA) runs in a dedicated namespace and reconciles every instance of one or more CRDs across the cluster.
Architecture in one paragraph:
- One controller binary, one ServiceAccount, one set of RBAC rules.
- Reconciles its CRDs cluster-wide (or in a configurable list of namespaces).
- A leader-election lease prevents two replicas from reconciling the same object in parallel.
- Failure mode: if the controller is down, no new reconciles happen, but existing workloads keep running (the Operator does not sit in the data path).
When to use it: the responsibility is cluster-wide (TLS certs, ingress configuration, network policy), the data plane is owned by some other controller (kube-apiserver, kubelet, ingress controller), and your Operator just needs one brain reconciling the desired state.
Canonical examples:
- cert-manager - one controller manages every
Certificate,Issuer,CertificateRequest, etc. across the cluster. - external-dns - reconciles cluster Ingress / Service entries into DNS records.
- ingress-nginx (controller
half) - one controller per cluster watching every
Ingressresource.
Anti-patterns to avoid:
- Running a Singleton Operator per namespace "for isolation". You give up shared caches, multiply RBAC complexity, and create N watch streams against the API server. If you need namespace isolation, use one controller with a namespace allow-list — see operator multi-tenancy patterns for the standard approaches.
- Skipping leader-election because "we only run one replica anyway". Pod-disruption events and rolling updates can leave two replicas alive for seconds; without leader-election they race.
2. The Capability Operator pattern
A Capability Operator exposes one or more high-level CRDs ("a Prometheus instance", "an alert routing config", "a service monitor") and reconciles each one into the underlying Deployments, StatefulSets, ConfigMaps, and Services that actually run the workload. Users never write a Deployment YAML; they write the high-level CRD and the Operator handles the wiring.
Architecture in one paragraph:
- Several related CRDs, each representing a capability (a thing the Operator can manage). The CRDs themselves form a typed API for the domain.
- The reconciler renders the CRD into Kubernetes primitives the way a Helm chart would - except it does so dynamically and on every spec change.
- Owner references on the rendered children let cascade deletion clean up the whole tree when the parent CRD is deleted.
When to use it: you are packaging operational knowledge of a complex multi-resource application (a metrics stack, a logging stack, a CI runner cluster). The Operator is essentially a typed alternative to a Helm chart - with the additional benefit that it can react to subsequent edits and to cluster state.
Canonical examples:
- Prometheus Operator -
Prometheus,ServiceMonitor,Alertmanager,PodMonitor,ThanosRuler. Each CRD is one capability; the reconciler renders each into the corresponding StatefulSet / ConfigMap / Service. - Strimzi for Apache Kafka -
Kafka,KafkaTopic,KafkaUser,KafkaConnect,KafkaConnector. - Elastic Cloud on Kubernetes -
Elasticsearch,Kibana,Beat,EnterpriseSearch.
Anti-patterns to avoid:
- One mega-CRD with 200 fields covering every aspect of the application. Split into focused CRDs the way Prometheus Operator did - users learn one CRD at a time, and the API ages better.
- Reconciling fields the user did not write. The high-level CRD should be
the single source of truth; defaults belong in the CRD schema, not in
hidden mutation logic. See
Custom Resource Definitions explained
for the
default:marker mechanics.
3. The Lifecycle Operator pattern
The most ambitious pattern. A Lifecycle Operator owns the entire operational lifecycle of a stateful workload: install, configure, scale, upgrade, back up, restore, fail over, repair. It encodes the operational runbook in code so a cluster of database servers can be operated without a dedicated DBA.
Architecture in one paragraph:
- One or more CRDs with rich
.status.conditions(Ready / Progressing / Available / Degraded - see status and conditions). - A state machine inside
Reconcile()that walks each instance through install → configure → ready → upgrade → backup, etc. - Coordinates with the data plane via custom protocols - SQL connections for a database Operator, HTTP for a search-cluster Operator, gRPC for a storage Operator.
- Heavy use of finalizers because deletion involves real-world cleanup (drop cloud disks, deregister from shared metadata stores, take final backups).
When to use it: the workload is stateful, complex, and currently requires human operators (DBAs, SREs, storage admins) to manage. The ROI of a Lifecycle Operator is the human time saved on the day-2 operations the Operator automates.
Canonical examples:
- Zalando Postgres Operator - install, configure, scale, upgrade, fail over, point-in-time recovery for PostgreSQL.
- CloudNativePG - the same problem space, different design.
- Vitess Operator - sharded MySQL with automatic resharding and online schema changes.
- MongoDB Community Operator - replica sets, sharded clusters, version upgrades.
- Redis Enterprise Operator.
Anti-patterns to avoid:
- Hiding configuration in operator-internal annotations. Users will need to set every knob your Operator exposes; put them in the CRD spec where validation, defaulting, and version migration apply.
- Skipping the upgrade path. A Lifecycle Operator that can install a database but cannot upgrade it is missing the part that pays for the Operator's existence.
4. The Auto-Pilot / Auto-Tune Operator pattern
An Auto-Pilot Operator continuously observes the workload it manages and adjusts the configuration without user input. The user expresses intent (a target latency, a cost ceiling, a load pattern) and the Operator decides the actual numbers (replica count, CPU request, shared_buffers value, JVM heap size).
This is the highest of Red Hat's five capability levels. It demands the most engineering effort but offers the biggest user value: the API surface shrinks dramatically because users stop tuning low-level parameters.
Architecture in one paragraph:
- A primary CRD expressing intent (
KEDA ScaledObject,VerticalPodAutoscalerrecommendation,AutoTunePolicy). - One or more probes feeding observed metrics: Prometheus queries, the Metrics API, custom external metrics adapters, application-level health endpoints.
- A decision loop - sometimes a simple proportional controller, sometimes a full reinforcement-learning model - that converts the probe stream into configuration changes.
- Outputs flow either to other Kubernetes objects (HPA, PDB, custom resources) or directly to the data plane via API calls.
When to use it: the workload has tuning parameters that are continuously load-dependent and impractical to set statically (autoscaling, JVM heap, DB connection pools).
Canonical examples:
- KEDA - event-driven autoscaling that reads from external metrics sources (queues, Prometheus, cloud APIs) and adjusts Deployments.
- Vertical Pod Autoscaler - observes resource usage and recommends or applies CPU / memory request changes.
- Karpenter - node provisioner that observes pending pods and provisions just-right nodes from a fleet of EC2 instance types.
Anti-patterns to avoid:
- Auto-tuning without an override field on the CRD. Users will need to pin a value temporarily for incident response; design for it from day 1.
- No emergency stop. A misbehaving Auto-Pilot can do real damage; expose a "paused" condition and respect it.
5. The Sidecar-Injecting Operator pattern
This Operator does not (primarily) reconcile a CRD. It registers a
MutatingAdmissionWebhook
against Pods and rewrites every newly-created Pod spec to add
containers, volumes, init containers, environment variables, or
annotations.
Architecture in one paragraph:
- A
MutatingWebhookConfigurationthat targets thepodsresource onCREATE. - A webhook server (frequently the same controller binary, sometimes a separate Pod) that receives every Pod creation as an AdmissionReview and returns a JSON Patch.
- Often paired with a CRD describing what to inject (Istio's
Sidecar, Linkerd'sProxyconfig), but the data plane work happens at admission time, not at reconcile time. - Failure modes are uniquely scary: a misbehaving mutating webhook can
prevent every new Pod in the cluster from starting. Always set
failurePolicy: Ignorefor non-critical injectors, scope withnamespaceSelector, and run the webhook server HA with very tight readiness probes.
When to use it: the change must happen on every Pod (service mesh proxies, security agents, log forwarders, secrets injectors), and after-the-fact patching of existing Pods is acceptable to lose.
Canonical examples:
- Istio sidecar injector - injects envoy proxy on every Pod in mesh-enabled namespaces.
- Linkerd proxy injector - same pattern, smaller proxy.
- HashiCorp Vault Agent Injector - injects a Vault Agent container that fetches secrets at runtime.
- OPA Gatekeeper - same webhook pattern, used for validation rather than mutation.
Anti-patterns to avoid:
- A single webhook serving the whole cluster with
failurePolicy: Failand no readiness probe. The day the webhook Pod crashloops, the cluster cannot start new Pods. (A real outage at multiple shops.) - Side effects in the webhook handler (creating other resources, calling external APIs). Webhooks must be idempotent and fast (< 1 second).
6. The GitOps-Controlled Operator pattern
A GitOps-Controlled Operator is itself reconciled by a higher-level GitOps tool. The Operator's CRDs are the output of compositions, claims, or overlays that live in git. The Operator does not authentically own the desired state; it owns the active state. For a deep dive on the GitOps tools that drive this pattern, see Helm Operator vs Flux vs Argo CD.
Architecture in one paragraph:
- The Operator exposes CRDs as usual (Helm releases, Crossplane composed resources, Argo CD applications-of-applications).
- Argo CD or Flux owns the content of those CRDs by syncing from git.
- The Operator's job is to translate the git-driven CR changes into actual cluster state - it still reconciles, but the higher-level "what should exist" is decided elsewhere.
When to use it: large multi-cluster or multi-tenant environments where the source of truth must live in git for audit and policy reasons, and the Operator is a building block in a larger declarative pipeline.
Canonical examples:
- Crossplane Composite Resources reconciled by Argo CD or Flux - one git repo defines compositions, another defines the claims, Argo CD applies them, Crossplane fulfils them.
- Argo CD Applications -
Argo CD itself is an Operator whose
ApplicationCRDs are defined in git and synced by Argo CD into the same cluster (the "app-of-apps" pattern). - Flux Helm Controller - the
HelmReleaseCRD is itself produced by a Kustomization synced from git.
Anti-patterns to avoid:
- Webhook side effects that mutate fields the GitOps tool then "drifts" back. Pick one source of truth; Argo CD's drift detection is the right place for it.
- Manual
kubectl editon resources that are git-controlled. It works once and then Argo CD reverts the change, with predictably confused operators.
Combining patterns - the production reality
Production Operators routinely span two or more of the patterns above. Three common combinations:
Singleton + Capability
The default for any cluster-wide Operator with more than one CRD.
cert-manager is the textbook example - one controller per cluster
(Singleton), several capability CRDs (Certificate, Issuer, Order,
Challenge, CertificateRequest).
Lifecycle + Auto-Pilot
The default for serious database Operators. Zalando Postgres installs and upgrades the cluster (Lifecycle) and continuously fails over to a healthy replica when the primary becomes unreachable (Auto-Pilot). Same pattern for Strimzi Kafka with its rolling-update controller, and for the Elastic Cloud on Kubernetes Operator.
Capability + Sidecar-Injecting
The service-mesh shape. Istio is a Capability Operator
(VirtualService, DestinationRule, Gateway) plus a Sidecar Injector;
both halves are needed for the mesh to work.
When you find yourself reaching for a second pattern, that is usually a healthy signal that the responsibility has genuinely distinct facets - not an excuse to refactor toward "one pattern fits all".
How to pick a pattern (decision tree)
First check whether you need an Operator at all. A surprising number of "we built an Operator" projects would have shipped faster and aged better as a Helm chart, a Kustomize overlay, or a
ValidatingAdmissionPolicy. Reach for an Operator only when the workload genuinely needs ongoing intelligence — failover, upgrade choreography, drift correction against external state, or automated reactions to cluster events. If the only thing your "Operator" does is render YAML and apply it once, ship a chart instead.
1. Does the responsibility need ongoing intelligence (failover, retries,
reactions to cluster state)?
NO -> Use a Helm chart. You don't need an Operator.
YES -> continue.
2. Is the workload stateful with non-trivial day-2 operations
(backups, upgrades, failover)?
YES -> Lifecycle Operator (often + Auto-Pilot).
NO -> continue.
3. Does the user express *intent* rather than *configuration*
(scale to keep latency below X, not "run N replicas")?
YES -> Auto-Pilot / Auto-Tune.
NO -> continue.
4. Must the change happen on every Pod and is admission time the only
feasible insertion point?
YES -> Sidecar-Injecting (mutating webhook).
NO -> continue.
5. Is the desired state owned by a higher-level GitOps tool, and your
Operator just translates it to cluster state?
YES -> GitOps-Controlled.
NO -> continue.
6. Does your Operator manage one cluster-wide responsibility through one
or more typed CRDs?
YES -> Singleton (+ Capability if more than one CRD).The decision tree is not gospel - real Operators frequently combine patterns - but it does force you to articulate which facet you are designing for first.
Pattern vs capability level - two orthogonal axes
A common confusion: design pattern is how the Operator is built; capability level is how much it does. A simple Singleton Operator that only does install (Level I) is just as valid a pattern instance as a Singleton Operator that does full auto-pilot (Level V) - they are the same pattern, different maturity.
In OperatorHub submissions you declare your capability level; the pattern is implicit in how the controller is implemented. Both matter for adoption: pattern is what users see at the API surface, capability level is what they get from running it.
Operators distributed through OperatorHub are packaged and installed by the Operator Lifecycle Manager (OLM), which handles install, upgrade, and dependency resolution as a meta-Operator running on the cluster. The pattern your operator implements does not change how OLM packages it — OLM treats all six patterns as the same shape: a Deployment plus a set of CRDs. The pattern only affects what your users see in the API.
Frequently Asked Questions
1. What are the design patterns for Kubernetes Operators?
2. What is the Singleton Operator pattern?
3. What is the Capability Operator pattern?
4. What is the Lifecycle Operator pattern?
5. What is an Auto-Pilot Operator?
6. What is a sidecar-injecting Operator?
7. When should I combine multiple operator design patterns?
8. What is the difference between an Operator and a Helm chart?
9. Should I write an Operator or use a Helm chart?
What's next?
You now know the six shapes. The natural follow-ups:
- Operator capability levels I-V (maturity model) — the orthogonal axis: how mature an Operator is on the install → upgrades → lifecycle → insights → auto-pilot scale, and what OperatorHub requires per level.
- What is a Kubernetes Operator? — the conceptual ground-up walkthrough that this article extends.
- The controller-runtime architecture — the Go library that almost every pattern listed here is built on top of.
- Custom Resource Definitions explained — the schema half of every Capability and Lifecycle Operator.
- Kubernetes finalizers explained — the safe-deletion primitive every Lifecycle Operator must implement.
- Mutating and validating admission webhooks — the implementation guide for the Sidecar-Injecting pattern and for every CRD-side webhook a Capability or Lifecycle Operator might add.
- Helm Operator vs Flux vs Argo CD — the comparison of the GitOps tools that drive the GitOps-Controlled pattern.
- Ready to pick one and build it? Move on to install Operator-SDK on Linux and the Chapter 2 scaffolding walkthrough.
